GloVe
GloVe는 LSA와 Word2Vec의 단점을 개선한 Word representation 방법이다.
- Word2Vec의 단점 :
윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스 전체적인 통계 정보를 반영하지 못한다는 점, - LSA의 단점 :
Word2Vec 처럼 단어 벡터 간 연산을 통해 의미를 구하는 작업이 힘들다는 점
이를 해결하기 위해서 Word2Vec처럼 신경망을 활용한 방법에 LSA의 코퍼스 전체 정보를 반영한 윈도우 기반 동시 등장 행렬을 사용한다.
GloVe 알고리즘
GloVe에서 Word Embedding을 학습시킬 때의 목표는 유사한 단어들을 가까이 묶는 것이다.
GloVe에서 유사한 단어라는 뜻은 코퍼스 전체에서 '두 단어가 한 윈도우에 얼마나 같이 등장했는지'를 의미한다.
그리고 가까이 묶는 것의 의미는 각 단어의 임베딩의 내적값이 최대가 되는 것이다.
이를 식으로 표현하면 다음과 같다.
: 단어 i의 임베딩
: 중심 단어 i가 나왔을 때 윈도우 내에 단어 k가 있을 확률
: 중심 단어가 i 일 때 단어 j가 등장한 횟수
:
이때 X는 동시 등장 행렬을 의미한다.
GloVe의 실제 학습에서는 위와 같은 식을 바로 사용하지 않고 살짝 다르게 사용한다.
이 과정을 처음부터 살펴보자.
GloVe의 연구진은 위 식에서부터 출발한다.
위 식은 기준 단어 k가 i와 더 유사한지, j와 더 유사한지를 이용하여 임베딩을 학습시키고자 한다.
유사한 정도를 코퍼스 전체 정보인 동시 등장 행렬을 이용하는 것이므로 Word2Vec의 단점을 해결하는 것이다.
GloVe의 연구진은 위를 만족하는 모델 F를 조금 더 편하게 찾기 위해 다음과 같이 변형한다.
두 단어 i와 j의 사이의 관계를 결과값으로 가지므로 두 단어의 차이를 두 임베딩 벡터의 차이로 표현하고, 출력이 스칼라값이므로 입력 또한 스칼라값으로 맞추기 위해 내적을 활용했다.
F의 함수 추정
여기서 굉장히 흥미로운 점은 F는 다음과 같은 성질을 만족해야 한다는 것이다.
단어 i와 j의 위치를 바꿨을 때 F의 입력은 정확히 반대 부호가 된다.
즉, 입력값의 부호를 바꾸면, 출력값은 역수가 나와야 하는 것이다.
이러한 성질을 만족하는 함수는 대표적으로 지수함수이다.
ex) 2^2 = 4 , 2^-2 = 1/4
연구진은 따라서 F를 지수함수로 정하게 된다.
지수함수는 특수한 성질을 가지는데, 그것은 바로 실수에서 덧셈과 곱셈에 대한 준동형을 만족한다는 것이다.
즉, 지수함수에서의 덧셈은 지수함수끼리의 곱셈이 되는 것이다.
이러한 준동형 성질을 이용하여 두 수의 차이를 기준 단어와 내적했던 식을 다음과 같이 두 단어를 이용한 좀 더 직관적이고 쉬운 식으로 바꿀 수 있다.
이때, F는 지수함수이므로,
양 변에 log를 취하면,
가 된다.
준동형 성질을 이용하여, 식이 굉장히 간편해졌고 두 단어의 관계를 나타내는 임베딩의 결과값이 직관적으로 변했다.
하지만 여기서 i와 k의 위치를 바꿨을 경우 값이 똑같아야 하는데, 와 가 같다는 보장이 없다.
이를 해결하기 위해, 연구진은 편향을 사용하여 다음과 같이 식을 변형하였다.
이것이 GloVe 에서 목표하고자 했던 임베딩값이 된다.
loss function
loss 함수는 GloVe의 임베딩 목표에 대한 오차를 MSE로 계산한 값이다.
이때 앞에 가 추가되게 되는데, 이 함수는 동시 등장 행렬이 sparse 하거나 동시 등장 빈도가 적어서 매우 적은 값을 가지는 단어들이 많을 것이므로, 이러한 경우에는 학습을 덜 시키기 위해 동시 등장 빈도 에 따른 증가함수를 만든다.
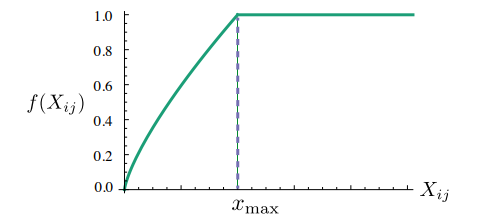
단순한 빈도수에 따라 증가함수를 만들지 않고, 일정 부분부터 꺾이는 이유는, 너무나 많은 빈도를 가진 단어들에 의해 학습이 영향을 받지 않게 제한하는 것이다.
GloVe는 F의 성질을 만족하기 위해 지수함수를 도입하고,
준동형을 이용하여 임베딩 식을 좀 더 간단하게 한 것이 굉장히 흥미로웠다.
