One hot의 단점
- 단어가 너무 많아서 불필요하게 메모리 공간 차지
- 단어 간 유사도가 전혀 반영이 안 됨 = 단어의 의미가 반영이 안 됨
이 두가지를 해결하는 방법이 Word Embedding
Word Embedding
단어를 vector space에 mapping 하는 작업
이때, 단어의 의미를 잘 반영하기 위해 semantically similar words는 비슷한 위치에 embedding 하는게 목표
NNLM (Neural Network Language Model)
NNLM의 목적
Learn simultaneously the word feature vectors and the parameters of that probability function
-
여기서 the word feature vectors의 의미는 단어를 어떤 vector에 임베딩 할 것인지,
-
probability function의 의미는 언어 모델의 다음 단어 예측을 수행하는 확률 함수
NNLM에서 위와 같은 목적이 왜 나왔는지를 이해하기 위해서 이전 방법인 통계 기반 언어 모델의 한계를 살펴보자.
통계 기반 언어 모델의 한계
언어 모델이라 함은 여태까지의 단어를 가지고 다음 단어를 예측하는 작업을 수행하는 모델이다.
언어 모델이 다음 단어를 예측하는 과정은 우리가 가지고 있는 코퍼스에 전적으로 의존한다.
자세한 과정
https://velog.io/@tri2601/Bag-of-Words%EC%99%80-Naive-Bayes-Classifier
문제는 말 그대로 통계 기반이기 때문에 만약 코퍼스에서 한 번도 등장하지 않은 단어들의 집합이 주어진다면 다음 단어를 예측할 수 없다는 것이다.
NNLM의 목적
한 번도 등장하지 않은 단어들이 나왔을 때 다음 단어를 예측하기 위해서 우리는 단어의 유사도를 이용한다.
예를 들어, '고양이가 방에서' 가 주어지고 다음 단어를 예측하려고 한다.
우리의 코퍼스는 고양이가 방에서로 시작하는 문장은 없고 '강아지가 방에서 뛰어논다.'라는 문장 밖에 없는 상황이다.
이런 경우 통계 기반은 다음 단어를 예측할 수 없는데, 단어의 유사성을 알고 있는 NNLM은 고양이와 비슷한 강아지를 대입하여 '고양이가 방에서' 의 다음 단어로 '뛰어논다'라는 단어가 나올 확률을 추정할 수 있다.
이러한 관점으로 다시 목적을 보면, NNLM이 하려고 하는 것은 한 번도 등장하지 않은 단어들의 집합 다음에 나올 단어를 예측하기 위해 단어들의 유사도를 학습하는 것이다.
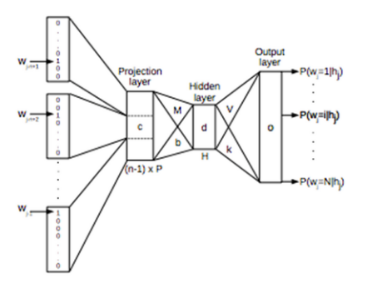
NNLM의 구조
NNLM의 모델을 f라고 하자. 그렇다면 f가 수행하는 역할은 다음과 같다.
: t 번째 오는 단어
여기서 n은 다음 단어를 예측할 때, 이전 단어를 몇 개를 볼 것인지에 대한 수이다.
NNLM의 목적으로 돌아와서 우리는 word representation과 다음 단어 예측 probability function을 얻고자 한다.
이 둘 모두 얻기 위해서 함수 f를 word representation 역할을 담당하는 C와 다음 단어 예측을 수행하는 g로 나누어 보자.
: t 번째 단어의 one-hot vector
: t 번째 단어의 embedding
: i는 에 오는 단어가 vocabulary의 i 번째 단어일 확률
이렇게 NNLM의 구조를 C와 g 두가지로 나타낼 수 있고,
이 논문에서는
C는 |V| x d 형태의 matrix를 이용한 projection layer,
g는 n개의 word embedding들을 input으로 받고 output으로 i 번째의 단어가 나올 확률 벡터 (크기 |V|)인 hidden layer
로 C와 g를 각각 선정했다.
참고자료
1. https://www.youtube.com/watch?v=bvSHJG-Fz3Y&t=1605s
2. https://wikidocs.net/45609
3. https://hul980.tistory.com/34
