Layer Normalization은 Batch Normalization과 함께 Normalization을 시켜주는 방법이다.
딥러닝에서의 Normalization의 효과는 다음과 같다.
일반적으로 기대할 수 있는 Normalization의 효과
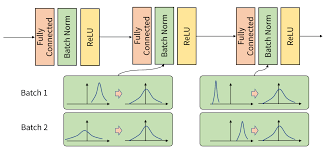
일반적인 경우 layer의 활성화함수 직전에 batch normalization을 배치하는데, 이때 batch normalization을 통해 활성화함수에서의 위치를 조절해 줄 수 있다. 예를 들어, sigmoid 의 경우 matrix를 통과한 활성화함수 입력값이 양 극단에 쏠려있다면, gradient값이 0에 가깝게 되고 이는 gradient vanishing과 함께 느린 학습의 원인이 된다.
이러한 활성화함수의 입력값을 표준화시켜준 후 적당한 위치에 배치시켜준다면, 적절한 학습을 할 수 있고 이로 인해 빠른 학습 효과도 기대해 볼 수 있다.
따라서 Normalization의 단계는 두 단계를 가진다고 할 수 있다.
- 입력값의 표준화
- 표준화 된 값을 적절한 곳으로 뿌려주기 위해 새로운 분포의 평균과 분산 학습한 후 표준화된 입력값을 이동시키기
Batch Normalization의 한계 (with sequential data)
Batch Normalization의 경우 두 가지 문제를 가진다.
1. batch size에 크게 의존적이다.
- batch normalization은 학습할 때의 batch size에 의존적이다.
2. RNN과 LSTM 같이 sequential한 데이터를 다룰 때는 한계가 있다.
- 만약 batch size가 2이고 한 데이터의 길이가 3, 나머지 데이터의 길이가 5인 경우라면, 4번째, 5번째 layer에서 길이가 짧은 배치는 pad값이 입력으로 들어가기 때문에 batch 끼리 normalization 해주는 의미가 사라진다.
이러한 두 가지 문제로 인해 sequential 데이터를 transformer와 같은 모델에서는 batch nornalization이 아닌 layer normalization을 사용한다.
Layer Normalization
가장 직관적으로 이해할 수 있는 사진은 아래와 같다. BN (batch normalization)에서는 Batch 단위로 표준화를 하기 때문에 Batch에 있는 모든 영역에 색이 칠해진 것을 확인할 수 있다. (색이 칠해진 부분은 한 번 표준화를 할 때 해당되는 대상들이다.)
반면 layer normalization에서는 아래와 같이 하나의 데이터에서 Feature 대상으로만 표준화가 일어나는 것을 확인할 수 있다.
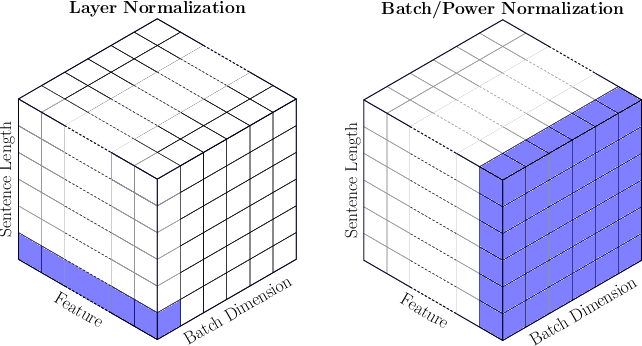
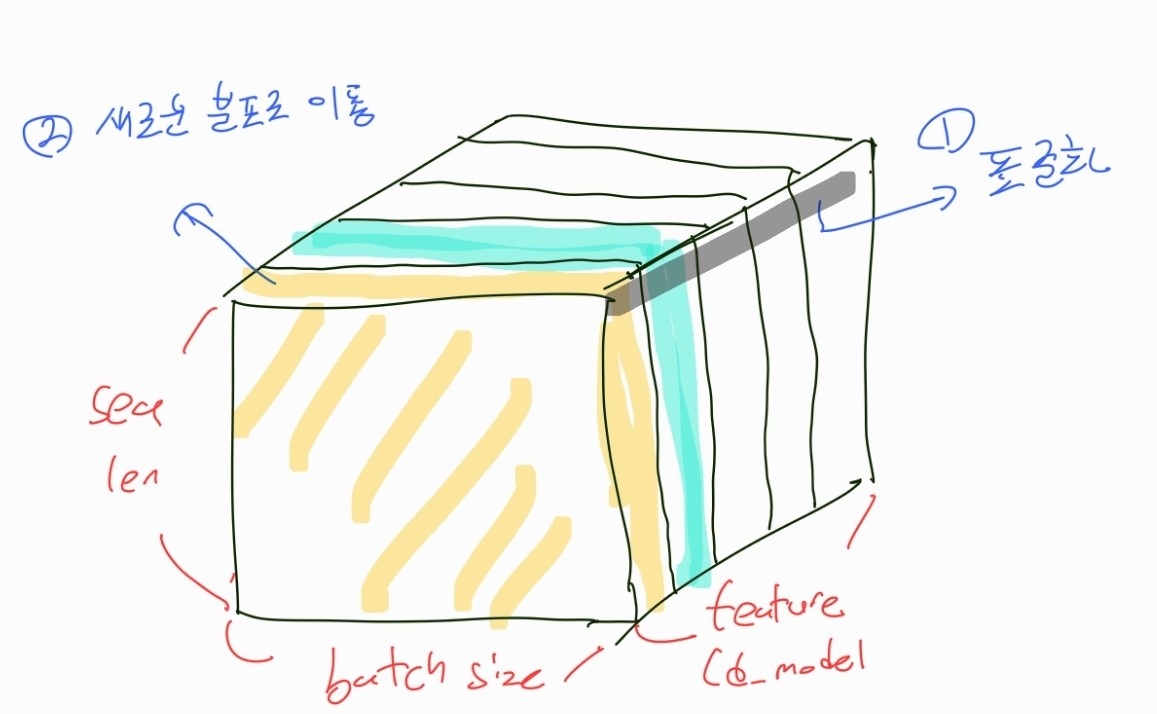
즉, layer normalization은 batch size와 관계 없이 하나의 단어 차원에서만 작동한다는 것을 알 수 있다.
아래 그림과 같이 세로축인 feature 차원에 대해 표준화를 진행한다.
주의점
여기서 공부할 때 헷갈릴 수 있는 점이 있다.
아까 normalization에서는 크게 두 단계의 과정을 거친다고 했다.
- 표준화 시켜주기
- 학습된 파라미터로 표준화 시킨 값 적절한 위치로 옮겨주기
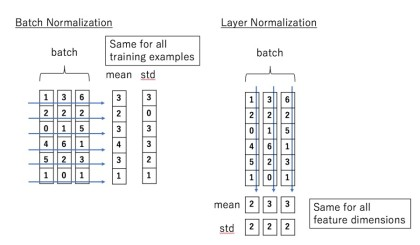
Batch Normalization의 경우에는 batch 단위로 표준화를 시키고 batch 단위로 분포를 이동시킨다.
하지만 !!
layer Normalization 에서는 feature 단위로 표준화를 시키지만 분포를 이동시키는 건 featrue 단위로 일어나지 않고, sequence length와 batch 단위로 일어난다.
이는 transformer 코드를 보면 이해할 수 있다.
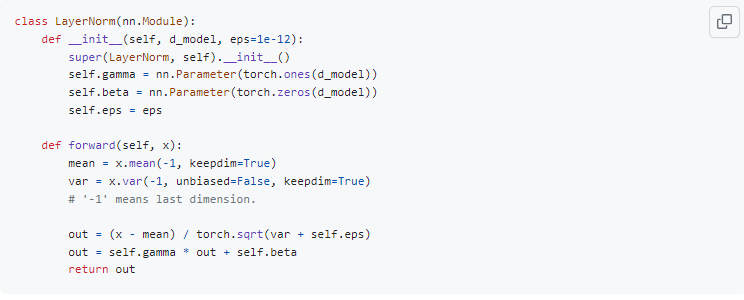
여기서 우리가 표준화를 시킨 후 새로 학습하고자 하는 값은 단어의 차원 수 (d_model)만큼 있다.
그림을 예시로 들어보면 참고로 이 그림에서 d_model은 5개이다.
실제로 표준화는 5개를 대상으로 하지만, 막상 표준화된 값들을 새로운 분포로 이동시켜 줄 때에는 5개의 파라미터를 이용하여 모든 데이터들 중 첫 번째 차원을 가지는 애는 첫 번째 파라미터로, 두 번째는 두 번째 파라미터로 표준화 시켜주는 것을 확인할 수 있다.
아래 그림에서 같은 색(노란색, 파란색) 으로 가진 애들은 모두 다 같은 gamma와 beta 값을 가지고 연산된다.
한 마디로 feature를 하나의 축으로 나머지 hyperplane를 보고 학습을 시키는 것