해당 글은 아래 참고자료를 보고 일부를 정리한 내용이다.
참고 자료
https://rlhfbook.com/c/06-policy-gradients#ref-schulman2015high
언어모델 RLHF에서 자주 쓰이는 알고리즘들은 policy-gradient 기반 강화학습 알고리즘
대표적으로 REINFORCE, PPO, GRPO 등이 있다.
해당 글에서는 각각의 알고리즘에 앞서 근간이 되는 Policy Gradient 알고리즘에 대해 살펴보고, Vanila Policy Graident, REINFORCE, PPO, GRPO 순으로 살펴본다.
Policy Gradient 알고리즘
강화학습 알고리즘은 state와 action으로 이루어진 trajectory에서 보상을 최대화 하도록 설계 되어 있다.
에이전트의 목표는 Return 이고, Return은 미래에 받을 보상의 총합이다.
γ 는 할인율을 뜻한다.
Return
Return G에 대한 식은 아래와 같다.
Gt=Rt+1+γRt+2+⋯=k=0∑∞γkRt+k+1.(1)
Value function
value function의 의미는 현재 state에서 시작했을 때, 앞으로 얻을 수 있는 return의 기댓값이다.
해당 return G와 value function의 관계는 아래와 같다.
V(s)=E[Gt∣St=s].(3)
Policy gradient 알고리즘의 기대 return에 대한 목적 함수
J(θ)=s∑dπθ(s)Vπθ(s),(4)
여기서 d는 policy가 만들어내는 state 방문 분포이다.
즉, 위 식의 의미는 policy가 만들어내는 state의 방문 분포를 고려한 value function의 기댓값이고, 이는 우리가 최대화해야 하는 값이다.
RLHF에서의 함수 계산
모든 상태에 대해 계산할 수 없으므로, 현재 policy에서 rollout (sampling)하여 근사적으로 계산한다.
- 데이터셋에서 prompt x 샘플링
- policy를 이용해 completion y 생성
J^(θ)=B1i=1∑BR(xi,yi),(5)
Policy Gradient 최적화
expected return J에 대해 아래를 수행하면 우리는 optimal한 값을 찾을 수 있다.
θ←θ+α∇θJ(θ)(7)
이제 gradient를 어떻게 계산하는지가 남았다.
Gradient 계산하는 방법
목적 함수를 다시 쓰면 아래와 같이 쓸 수 있다.
J(θ)=Eτ∼πθ[R(τ)],(8)
trajectory τ=(s0,a0,s1,a1,…) 에 대해
이때 Return은 R(τ)=∑t=0∞rt 이다.
이를 이용해 목적 함수를 다시 쓰면 아래와 같이 쓸 수 있다.
J(θ)=∫τpθ(τ)R(τ)dτ(9)
trajectory는 연속이 아닌 이산이므로 저렇게 쓸 수 있는게 맞나? 싶었는데, 관용적으로 이렇게 쓴다고 한다.
어쨋든 위 식의 의미는 policy πθ에 대해 trajetory가 발생할 확률 에 대한 해당 trajectory에서 발생하는 보상의 기댓값으로, 우리가 구하고자 하는 총 보상과 같은 의미다.
우리의 파라미터 θ에 대해 trajetory가 발생할 확률에 대한 식은 아래와 같이 표현된다.
pθ(τ)=p(s0)t=0∏∞πθ(at∣st)p(st+1∣st,at),(10)
이제 각각의 요소들을 이용해서 미분을 할 것이다.
우선 식 (7)에서 우리가 구해야하는 gradient다.
∇θJ(θ)=∫τ∇θpθ(τ)R(τ)dτ(11)
R(τ) 는 주어진 θ에 대해 독립이므로 위와 같이 표현될 수 있다.
이제 남은 건 ∇θpθ(τ) 다. 이는 식 (10)을 이용해 구할 수 있다.
이를 조금 더 쉽게 구하기 위해 합성함수의 미분을 활용한다.
∇θlogpθ(τ)⟹∇θpθ(τ)=pθ(τ)∇θpθ(τ)=pθ(τ)∇θlogpθ(τ)(from chain rule)(rearranging)(12)
이걸 그대로 식 (11)에 대입하면 아래와 같다.
∇θJ(θ)=∫τ∇θpθ(τ)R(τ)dτ=∫τpθ(τ)∇θlogpθ(τ)R(τ)dτ=Eτ∼πθ[∇θlogpθ(τ)R(τ)](13)
이를 조금만 더 정리해보자. 식 10에 log를 취하면,
logpθ(τ)=logp(s0)+t=0∑∞logπθ(at∣st)+t=0∑∞logp(st+1∣st,at)(14)
∇θlogpθ(τ)=t=0∑∞∇θlogπθ(at∣st)(15)
θ에 대해 p(s)는 독립이라 제거, 상태 천이 확률 p도 θ와 독립이므로 제거.
llm의 상태 천이 확률은 항상 1이다.
이렇게 정리한 걸 마무리로 식 (13)에 다시 대입하면 이제 우리가 구하고자 하는 policy gradient가 완성 된다.
∇θJ(θ)=Eτ∼πθ[t=0∑∞∇θlogπθ(at∣st)R(τ)](16)
이쯤에서 식의 의미를 한번 정리하고 가자.
- 기댓값의 의미 : 자주 나오는 trajectory 일수록 반영 크게
- 시그마의 의미 : trajectory의 각 action의 gradient 합 (credit assignment - reward에 전체 action이 모두 기여했다고 가정)
- ∇θlogπθ(at∣st)의 의미 : 해당 상태에서 action의 확률을 높이는 방향
- R(τ)의 의미 : reward가 높은 trajectory는 더 크게 반영 (가중치)
전체적인 의미
reward가 높은 trajectory에서 등장한 action들이 일어날 확률을 증가시키는 것
생각해보면 llm의 gradient에 가중치만 붙은 거라고 해석할 수 있다. 다만, 차이점은 llm은 확률을 높이는 쪽으로만 학습을 하지만 강화학습은 확률을 증가, 감소하는 쪽으로도 학습
1. Vanilla Policy Gradient
우리가 위에서 구한 Policy Graident를 그대로 활용하는 것이다.
∇θJ(θ)=Eτ[t=0∑T∇θlogπθ(at∣st)Rt](19)
한계
gradient update 과정에서의 분산이 너무 크다는 것이다.
이런 문제가 발생하는 이유는
- rollout randomness
- 적은 수의 rollout 샘플로부터 return G를 추정
- sampling randomness
- 이 rollout 샘플들은 temperature sampling
- sparse reward
- 보상이 0 또는 1과 같은 경우 (결과가 달라지는 경우가 많기 때문에 각 보상의 움직임도 커진다)
baselines
분산이 높은 문제를 해결하기 위해 값을 정규화하는 다양한 기법을 baselines이라고 한다.
baseline은 여러 방식으로 사용되는데, 해당 행동이 상태의 평균 가치에 비해 얼마나 좋은지를 평가하는 방식으로 작동한다.
가장 간단한 baseline은 batch reward의 평균이나 이동평균을 활용하는 것이다.
baseline은 action과 독립적이어야 한다. action과 종속적이라면 gradient의 방향이 바뀐다.
2. REINFORCE
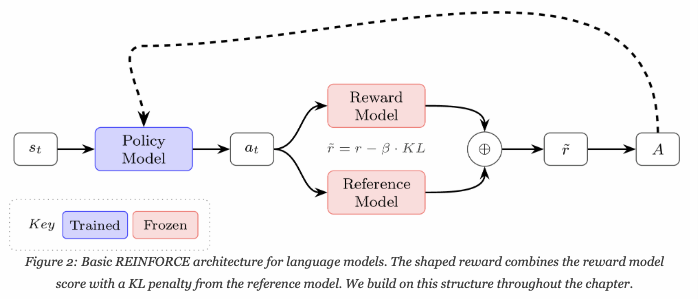
REINFORCE는 그냥 Vailla Policy Gradient의 특정 구현이다.
REward Increment = Nonnegative Factor X Offset Reinforcement X Characteristic Eligibility.
Nonnegative Factor = Learning rate (step size)
Offset Reinforcement = baseline (학습을 안정시키기 위해 빼는 값)
Characteristic Eligibility = credit assginment (어느 토큰이 기여를 했는가)
이를 식으로 표현하면 아래와 같은데, 이는 결국 우리가 얘기하던 목적 함수와 같은 형태이다.
Δθ=α(r−b)e(21)
다만 위에서는 단순히 G를 썼다면 여기서는 baseline을 빼서 학습을 안정적으로 하게 한다.
∇θJ(θ)=Eτ∼πθ[t=0∑T∇θlogπθ(at∣st)(Gt−b(st))],(22)
3. PPO
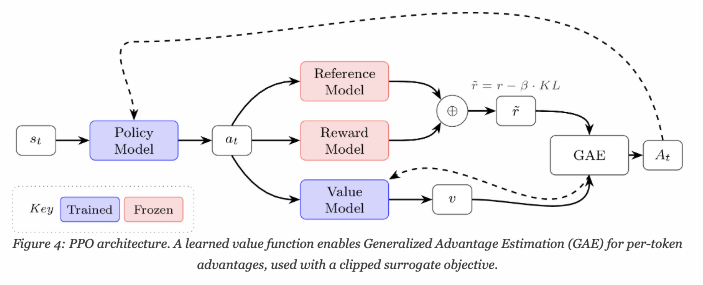
기본 Policy Gradient에서의 목적 함수
J(θ)=Eτ∼πθ[R(τ)],(8)
PPO에서의 목적 함수
J(θ)=Et[min(Rt(θ)At, clip(Rt(θ),1−ε,1+ε)At)],Rt(θ)=πθold(at∣st)πθ(at∣st).(29)
여기서 기존에 보던 식과 달라진 점은 아래와 같다.
- importance sampling (정책 비율)
- Clip
그 중 현재 policy를 이전 policy로 나누는 이유는 importance sampling 때문이다.
importance sampling
- 원래 A 분포에서 평균을 구하고 싶은데, 실제 샘플은 B 분포에서 뽑았을 때, 가중치로 A 분포의 평균처럼 보정하는 방법.
- 우리가 지금 구하고 싶은 건 현재 policy 기준의 기댓값인데, 샘플은 이전 policy에서 나왔다 그래서 보정을 해줘야 하고, 정책 비율 값이 importance weight이다.
- 데이터를 샘플링하면서 과거에 적게 나온 것들은 적게 반영되므로 이를 높여줘야 하고, 현재에 많이 나온 것들 또한 높여줘야 함.
importance sampling을 기본적으로 쓰는 이유는 data reuse에서 장점이 있기 때문이다.
Clip에 대해서는 R이 극단적인 값으로 가게 될 경우 gradient의 분산이 너무 커져서 학습이 어렵기 때문에 이를 완화하기 위해서 사용한다.
일반적으로 1~4번의 gradient step이후 이전 정책을 update 하는게 관행이다.
REINFORCE 식 학습 흐름
매 iteration 마다 아래 반복
1. 현재 policy로 샘플 뽑음
2. reward 계산
3. 업데이트
PPO의 학습 방식
1. 어떤 시점의 policy로 데이터를 모음
2. 같은 배치를 가지고 여러 번 gradient step 진행
-> 이렇게 하는 이유는 데이터를 여러 번 생성해야 하기 때문
결국 이게 하려는 건 old policy로부터 만든 sample을 가지고 업데이트
Value Functions and PPO

PPO 에서는 value function을 이용해서 advantage를 구한다.
At=Gt−V(st)
즉, 우리가 학습해야 하는 대상은 policy model 과 value model이므로 각각의 gradient 가 존재한다.
value 모델의 loss는 MSE를 사용하며 이때 target을 만드는 방식은 MC가 있고 GAE가 있는데, 위 그림은 MC 방법이다. (Monte Carlo가 value function의 target이 token마다 동일하다면 GAE는 토큰마다 다르다.)
4. GRPO
![업로드중..]()
GRPO는 다른 답보다 얼마나 좋았를 판단한다.
PPO의 Advantage 계산 과정에서 value function을 없애고 group reward expectation을 활용하는 것으로 바꾼 것
이게 2가지 문제를 해결하는데
-
LM backbone의 value function을 학습해야했는데 이 어려움을 피할 수 있다. (value function 학습엔 아직 best practice가 없다고 한다)
-
value function을 제거함으로써 메모리 이득
GRPO의 Advantage
Ai=std(r1,r2,⋯,rG)ri−mean(r1,r2,⋯,rG).(34)
GRPO의 경우 advantage를 하나의 프롬프트에서 나온 여러 Completion의 평균 점수보다 얼마나 잘했는지로 계산한다.
GRPO의 Advantage의 trade-off
Advantage는 gradient의 크기를 결정한다. GRPO의 경우 각 점수들의 통계값으로 Advantage를 계산하면서 trade-off가 생긴다.
식 34와 같이 계산할 경우 만약 모든 답이 좋은 점수를 받았거나 모든 답이 나쁜 점수를 받았을 경우 Advantage가 굉장히 커진다.
후자는 바람직할 수 있지만 전자의 경우 쉬운 문제가 더 크게 학습되므로 원하는 상황은 아니다.
일부 논문에서는 이러한 편향을 없애기 위해 표준편차를 제거하곤 한다.
하지만 이 또한, 대부분은 틀리고 일부만 맞는 경우 (표준편차 작음)는 중요한 신호인데, 이 신호가 약해질 수 있다.
GRPO의 목적 함수
J(θ)=G1i=1∑G(min(πθold(ai∣s)πθ(ai∣s)Ai,clip(πθold(ai∣s)πθ(ai∣s),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)).(32)
여기서 G는 하나의 프롬프트에 해당하는 여러 개의 completion의 수이다.
