참고 자료
https://www.youtube.com/watch?v=PmW_TMQ3l0I&list=PLoROMvodv4rOCXd21gf0CF4xr35yINeOy&index=5
일반적으로 LLM 모델 학습은 아래와 같은 세 단계를 거친다.
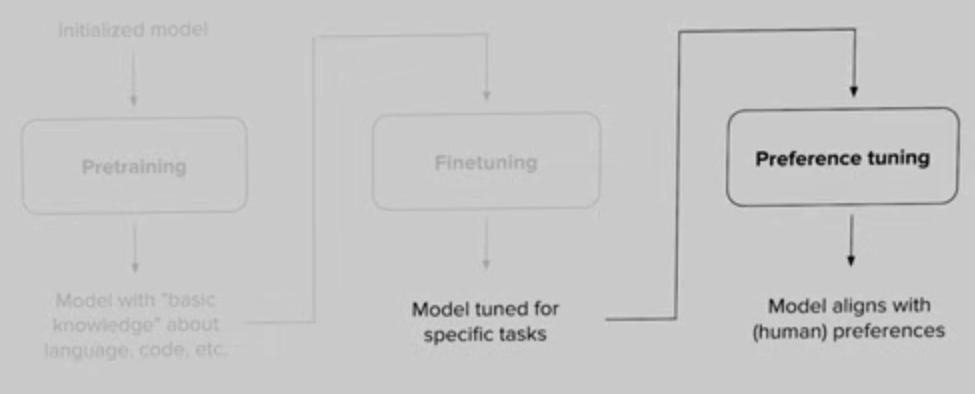
-
Pretraining
-> 모델에게 언어와 코드에 대한 basic knowledge 인식
-
Finetuning
-> 특정한 task를 잘 수행하도록 학습
-
Preference tuning
-> 단순히 task를 수행하는게 아니라 사람의 선호에 맞는 답변
(예를 들어, 인종 차별적인 답변 내놓는 것, toxic한 답변 x - RLHF 논문에 나옴)
SFT의 경우 목적은 어떤 것을 답을 해야 하는지가 되는데, 어떤 것을 답을 안해야 하는지는 배울 수 없다.
이걸 RL을 통해 배운다.
1. Preference data
Preference tuning을 위한 세 가지 종류의 dataset
-
pointwise
a = 0.4
b = 0.9
c = 0.1
d = 0.2
-
pairwise
a<b, c<b, ...
-
listwise
c < d < a < b
학습에서는 주로 pairwise를 사용
pointwise의 경우는 일관성 문제
listwise의 경우는 annotator가 하기 어렵고 시간이 많이드는 작업.
반대로 두 개를 비교하는 건 상대적으로 쉬운 작업
데이터셋 만드는 법
- 같은 프롬프트 x에 대해 두 번 inference를 통해 두 가지 다른 응답 (y1, y2) 얻기
- (x, y1), (x,y2)에 대해 Labeling
- llm-as-a-judge 주로 사용
- 이진 척도나 "훨씬 좋음", "좋음" 등 세분화 시킬 수 있지만 일반적으로는 이진 척도를 사용 (세분화는 사람 주관이 더 많이 반영되므로)
2. RLHF
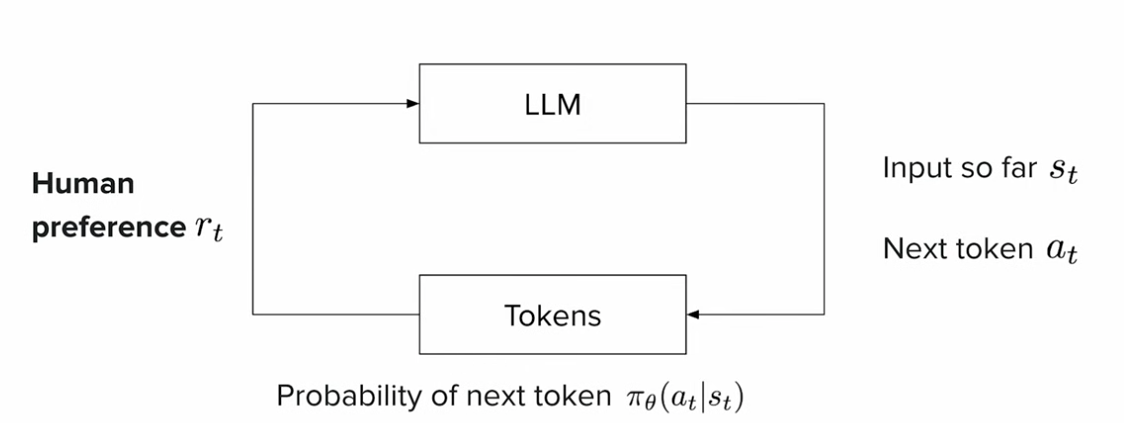
LLM을 강화학습에 대입해서 agent, state, policy, action를 정의하자면 다음과 같다.
πθ : agent = llm
θ = 모델 파라미터
st : state = 지금까지의 input
at : action = next token
π : policy = P(token | prompt + previous tokens)
rt : reward = human preference
Reward 모델의 loss function 유도

위 식은 우리가 가진 pairwise 데이터셋 즉, 하나의 input에 대한 2개의 output에 대해
응답 i가 응답 j 보다 선호될 확률을 시그모이드를 활용해 두 응답의 score 차이로 모델링하는 식이다.
Loss function
D={(xi,yw,i,yl,i)}i=1N,
P(yw,i≻yl,i∣xi)=exp(rϕ(xi,yw,i))+exp(rϕ(xi,yl,i))exp(rϕ(xi,yw,i))=σ(rϕ(xi,yw,i)−rϕ(xi,yl,i)).
P(D∣ϕ)=i=1∏NP(yw,i≻yl,i∣xi)=i=1∏Nσ(rϕ(xi,yw,i)−rϕ(xi,yl,i)).
MLE:argϕmaxP(D∣ϕ)=argϕmaxi=1∏Nσ(rϕ(xi,yw,i)−rϕ(xi,yl,i)).
=argϕmaxi=1∑Nlogσ(rϕ(xi,yw,i)−rϕ(xi,yl,i)).
따라서, 아래와 같이 쓸 수 있다.
LRM(ϕ)=−i=1∑Nlogσ(rϕ(xi,yw,i)−rϕ(xi,yl,i)).
LRM(ϕ)=−E(x,yw,yl)∼D[logσ(rϕ(x,yw)−rϕ(x,yl))].
3. Reward model
Reward model 학습
Reward model 은 대체로 LLM with classification head 형태.
input은 response 답변은 score로 나오게 학습

단 이때, 최소 100k개의 D 쌍 {x, y_w, y_l} 정도가 reward model 학습하는데 좋다고 함
