Word2Vec은 sparse한 one-hot vector로 단어를 표현하는 대신 더 적은 차원의 dense vector로 단어를 표현하는 방법이다.
이 방법은 단순하지만 강력한 가정을 기반으로 단어를 학습한다.
가정 : 단어의 의미는 주변 단어가 결정한다.
영어 시험을 볼 때 자주 들었던 말인데, 그걸 그대로 구현한 느낌이 드는 방법이라 감탄스럽다.
Word2Vec
우선 word2vec은 간단한 신경망을 이용하여 만들 수 있다.
결론부터 말하면 신경망의 가중치 행렬이 Word2Vec의 테이블이 된다.
input과 output으로는 모두 단어의 one-hot vector가 들어간다.
상황을 통해 이해해보자.
(input, output) = ('나는','학교에'), ('선생님은','학교에')
학습 데이터는 이렇게 두 쌍이 있다고 하자.
(여기서는 이해를 위해 학습 데이터를 각각 한번씩 학습시킨다.)
이때, '나는'은 [0,0,0,1], '선생님은'은 [0,1,0,0], '학교에'는 [1,0,0,0]이라는 표현을 가진다고 하자.
그리고 W1과 W2는 각각 가중치 행렬이다.
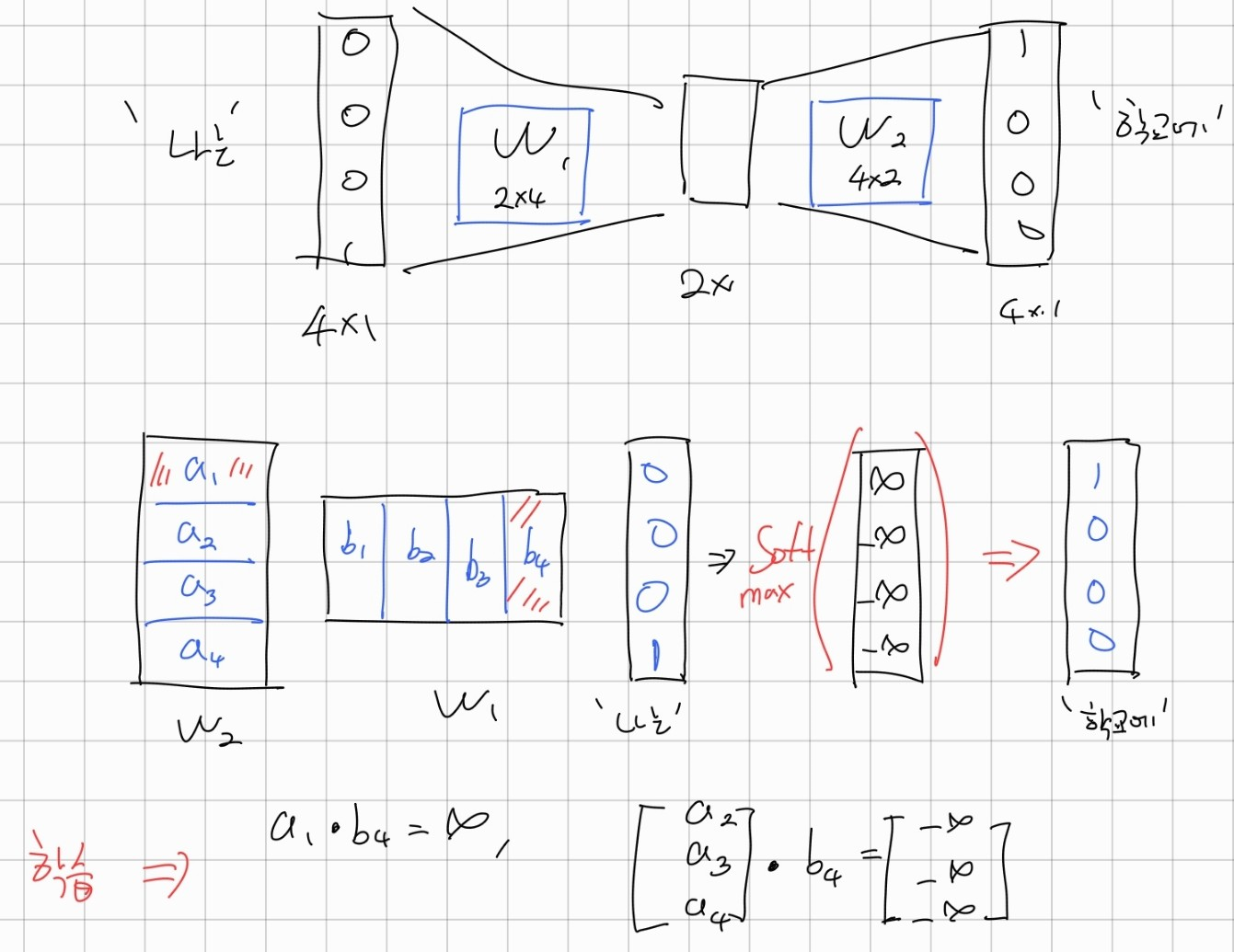
'나는'이라는 one hot vector가 들어가게 되면 b4 벡터에 매칭된다.
이때, 결국 softmax의 결과값이 [1 0 0 0] 이 나와야 하므로 a1과 b4의 내적은 무한대가 되도록 학습이 된다.
내적은 유사도를 의미하기도 하므로,
b4의 입장에서는 a1과 가장 가까워지고 a2, a3, a4와 가장 가깝게 학습이 된다.
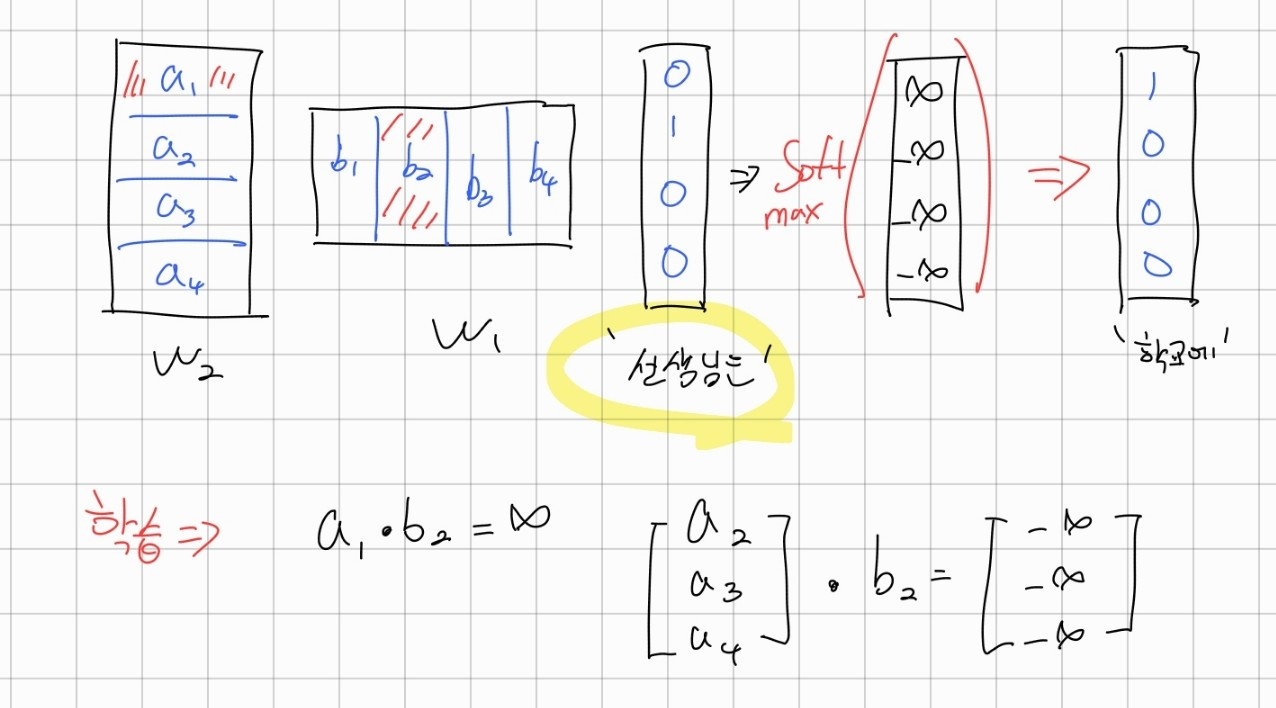
'선생님은' 이라는 단어는 b2 벡터에 매칭되고 위와 똑같이 a1과 가까워지고 나머지와는 멀어지는 학습 과정을 거친다.
즉, 동일하게 '나는'과 '선생님은'은 모두 동일하게 학습을 거치므로 각각에 대응하는 b2벡터와 b4벡터는 같아지게 된다.
따라서 W1 가중치 행렬의 각 열벡터는 단어의 의미를 담고 있게 된다.
마찬가지로 W2에서도 학교에에 대응되는 a1 벡터도 학습이 되어 W2도 동일하게 단어의 의미를 담고 있지만 일반적으로 W1을 word2vec 테이블로 사용한다고 한다.
Word2Vec 방법
Word2Vec은 단어의 표현을 학습하기 위해 학습 데이터를 만들어야 하는데 크게 두 가지 접근 방식이 있다.
1. Skip-Gram
중심 단어에서 주변 단어를 예측하는 방식
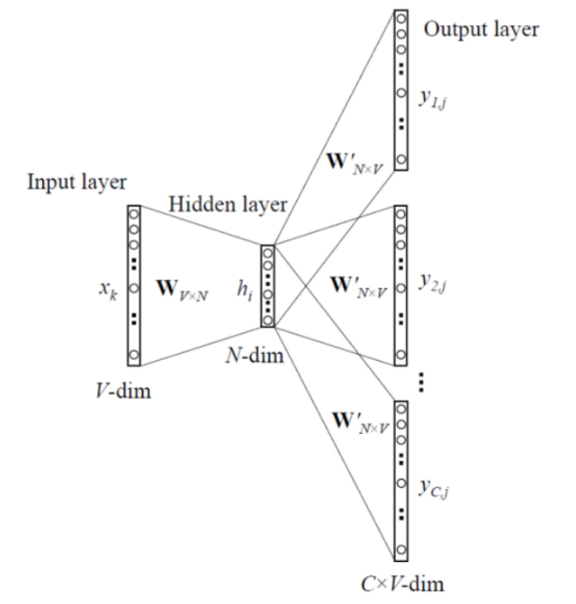
목적함수 (maximize) :
: 가능한 pair 조합 수
: t 번째 단어
-> 가능한 pair 조합에서의 예측 확률을 최대화 하는 것
이때 log(p(w|w)) 이 부분을 cross entropy를 활용하여 계산한다.
2. CBOW
주변 단어에서 중심 단어를 예측하는 방식
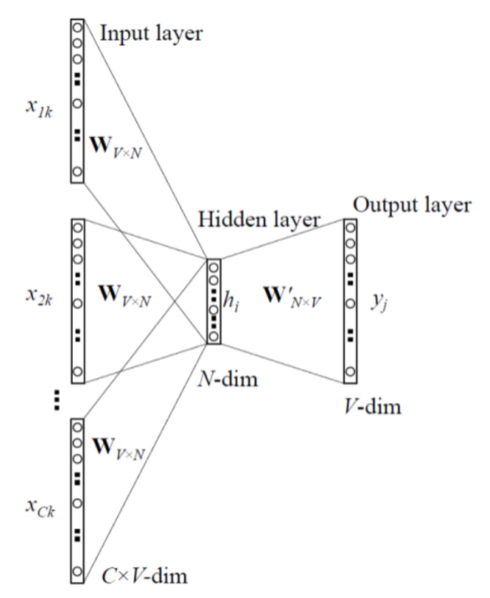
여기서 주의할 점은 입력 벡터를 만들 때 주변 단어들의 임베딩의 평균값으로 구한다는 점이다.
그리고 마찬가지로 cross entropy를 활용한다.
Learning startgy
Word2Vec를 효율적으로 학습시키기 위해 몇 가지 트릭을 사용한다.
1. Huge networks
우리가 학습하고자 하는 matrix는 |V| X dimension의 크기를 가진다. 우리는 이러한 matrix를 2개 학습하게 된다.
이렇게 큰 사이즈를 효율적으로 학습하기 위해 두 방법을 사용한다.
-
Treating common word pairs or phrases as single "word"
-> 비슷한 단어들 정규화 -
Subsampling frequent words
-> 굉장히 큰 corpus에서 빈번하게 등장하는 단어들은 학습을 조금 덜 시켜도 된다.
t : 하이퍼 파라미터
f(w_i) : corpus에서의 w_i의 term frequency
P(w_i) : w_i 가 학습에서 제거될 확률
2. Negative sampling
해당 단어가 나올 확률을 구하기 위해서 우리는 softmax를 취했는데, 이때 전체 Vocab에 대한 합이 있어야 하므로 분모에서만 |V|만큼의 시간복잡도 소요
-> 이걸 t개의 negative와 1개의 정답만 이용해서 softmax 분모값 계산
3. Hierarchical Softmax
참고자료
https://reniew.github.io/22/
https://simonezz.tistory.com/35
https://heytech.tistory.com/352
https://wikidocs.net/69141
https://www.youtube.com/watch?v=s2KePv-OxZM
