LSTM은 기존 RNN 모델의 gradient vanishing 문제를 해결하기 위해 제안된 모델이다.
기본적으로 거의 비슷한 구조를 가지고 있지만 크게 두 가지 차이가 있다.
- hidden state를 hidden state와 cell state로 나누었다.
- cell state는 타임 스탭 t 까지의 정보를 담고 있다.
- hidden state는 타임 스탭 t에서의 출력에 필요한 정보를 담고 있다.
- cell state를 구할 때 덧셈 연산을 통해 구한다.
여기서 2번에 의해 역전파 과정에서 계속 곱만 하던 RNN과 달리 덧셈 연산을 추가함으로써 gradient 손실을 방지한다.
LSTM의 구조
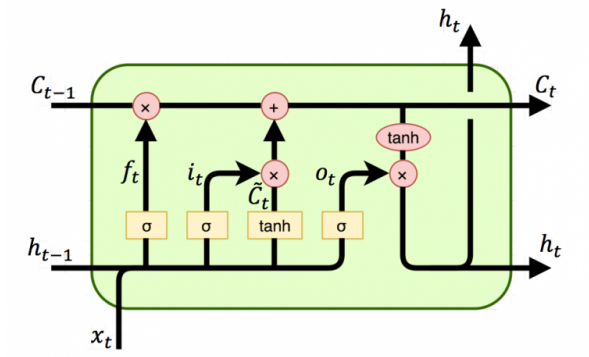
LSTM은 다음과 같이 구성된다.
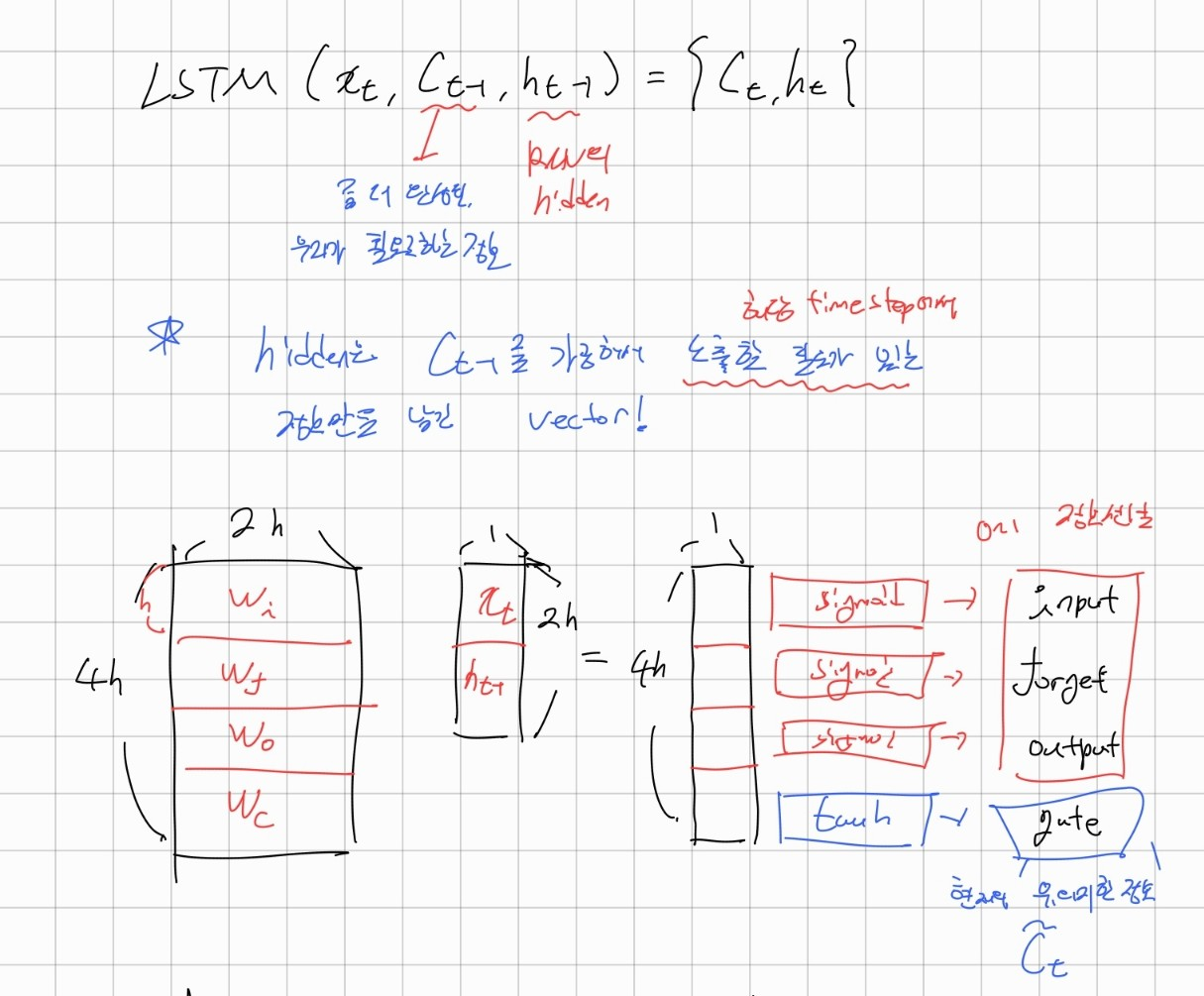
LSTM은 크게 4 가지 gate가 중요한 역할을 한다.
, forget gate : 얼마나 과거의 정보를 반영할지(=잊을지) 결정
, input gate : 현재 정보를 얼마나 반영할지 결정
, output gate : 현재 타임 스탭 t에서의 정보 중 중요한 것 추출
, gate gate : 현재 time step이 가지고 있는 정보 gate
이들은 각각 로 추출되며 그림으로 나타내면 다음과 같다. (편향은 그림에선 생략되었다.)
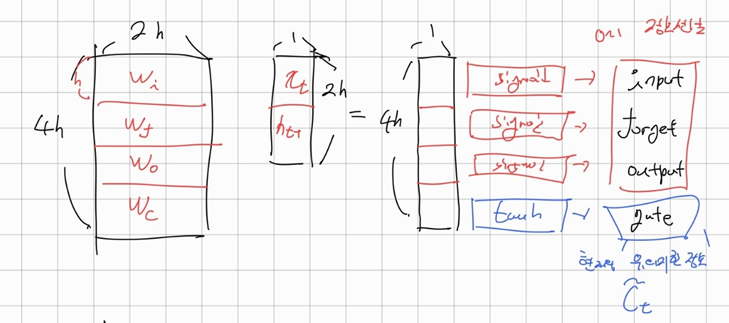
이때 는 sigmoid를 이용하여 0~1 사이의 값을 가지게 되며 이게 추출의 의미를 가진다.
반면 는 tanh를 이용하여 중요한 정보를 담게 된다.
LSTM의 연산
이제 출력에 필요한 와 여태까지의 정보를 담고 있는 를 구하기 위해 LSTM에서 실행되는 gate 연산을 살펴보면 다음과 같다.

타임 스탭 t까지의 정보 를 구하기 위해 t-1 까지의 모든 정보들 중 forget gate로 잊을 것을 잊고, 현재 정보 를 input gate를 이용해서 반영한다.
즉, 는 타임 스탭 t 까지의 정보가 담기게 된다.
이를 이용해서 를 구하게 되는데, 타임 스탭 t까지의 정보에서 output gate를 이용해서 현재 출력에 관여될 만한 정보를 추출하게 된다.
실제 타임 스탭 t에서의 출력값은 와 의 연산을 통해 만들어지게 된다.
즉, 는 타임 스탭 t에서 출력에 필요한 정보가 담기게 된다.
참고자료
https://www.boostcourse.org/ai330/lecture/1455691?isDesc=false
