해당 글은 kakao tech의 발표 내용을 듣고 일부를 재구성하여 정리한 글입니다.
발표 자료
https://www.youtube.com/watch?v=4wwsyiLmVkA&list=PLwe9WEhzDhwG1H81qHrjc05sj75cGa1fi&index=14
1. 온디바이스 AI
왜 온디바이스를 쓰는가?
- Low Latency - 서버 LLM 보다 빠른 응답이 필요한 경우
- Privacy - 서버 LLM으로 다루기 어려운 데이터
어떻게 쓰는가?
- 정해진 기능만 사용 (실시간 번역, 요약, 문장 자동완성)
- 서버 AI와의 하이브리드 접점
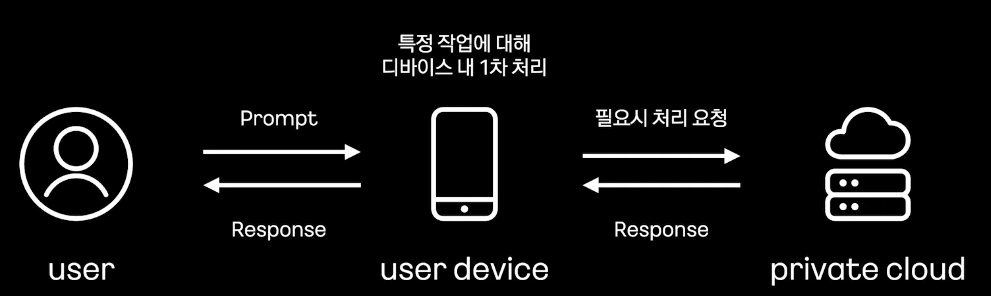
최신 스마트폰 기준 약 3B 모델까지 디바이스 내에서 안정적으로 구동 가능
-> 현재 kanana nano 오픈 소스 기준 2.1B 있음
2. 카카오의 온디바이스 AI
온디바이스 AI가 잘할 수 있는 또 하나의 영역
= Function calling
위 문장에 대한 근거는 Meta에서 발표한 MobileLLM 논문 (1B 이하의 모델이 llama 7B 수준의 function calling 능력 보임)
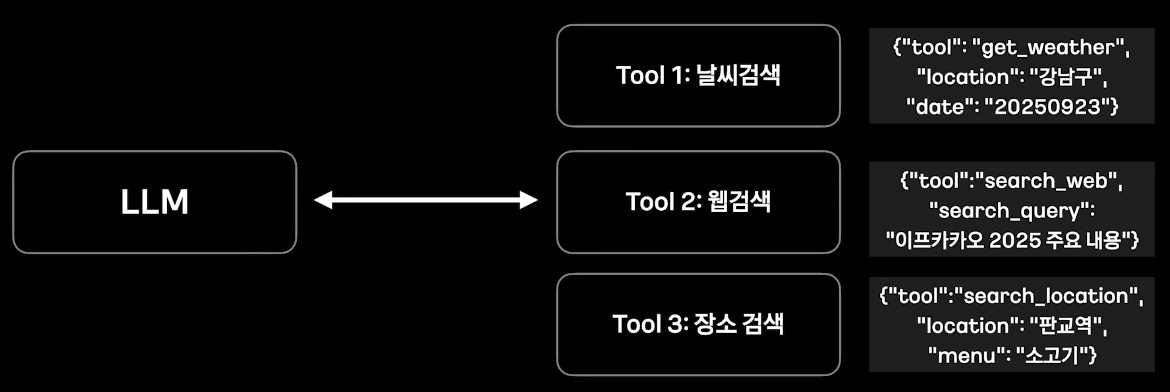
Function calling을 어떻게 쓰는가?
- 서버 AI가 필요한 순간, 연결을 위한 Function calling

이런 Function calling이 가능하다면 사용자의 대화를 기반 서비스 가능

언제 서버 AI가 필요한가? = 어떤 도메인들이 있는가?
- 정보검색
- 탐색 (쇼핑, 로컬)
- 할 일 관리
3. 모델 학습 전처리 과정
3-1. 어떻게 프로세스를 구성할 것인가?
문제 상황
- 하나의 모델에서 도메인 별로 사용자에게 제안을 하는 쿼리가 달라야 한다
= 하나의 모델이 여러 형태의 output을 만들어 낼 수 있어야 한다
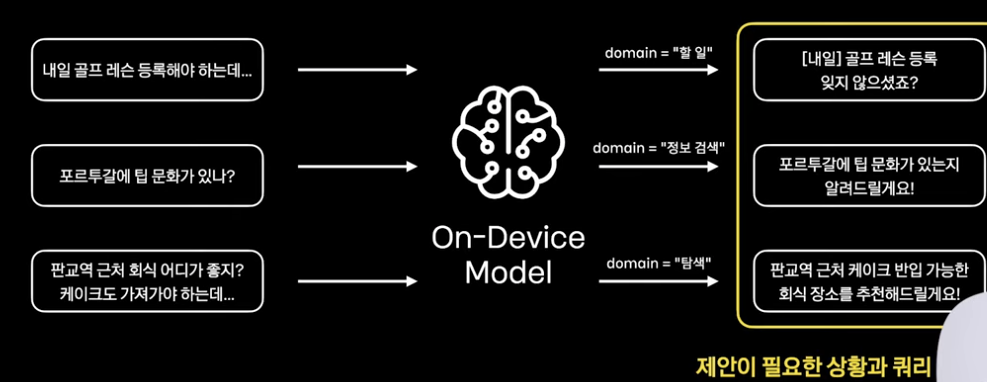
해결책
CoT를 활용 + 다른 도메인 모두 같은 생각 과정 거치기
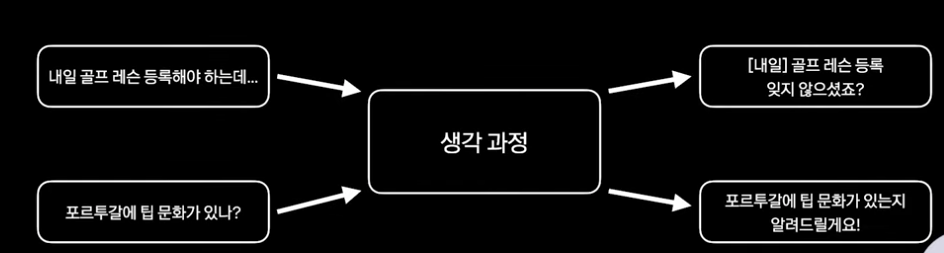
이러한 해결책의 이유로는
1. 대화로부터 바로 제안을 만들어내는 과정은 어렵다 -> CoT (생각 과정)이 필요하다.
2. 도메인 별로 다른 생각 과정을 거친다면 작은 모델이 학습하기엔 어렵다 -> 같은 형식의 생각 과정으로 추론 시작
결론
모든 도메인이 공통된 생각 과정을 위해 같은 형식을 가지는 맥락을 추출하고 그 이후 쿼리 생성
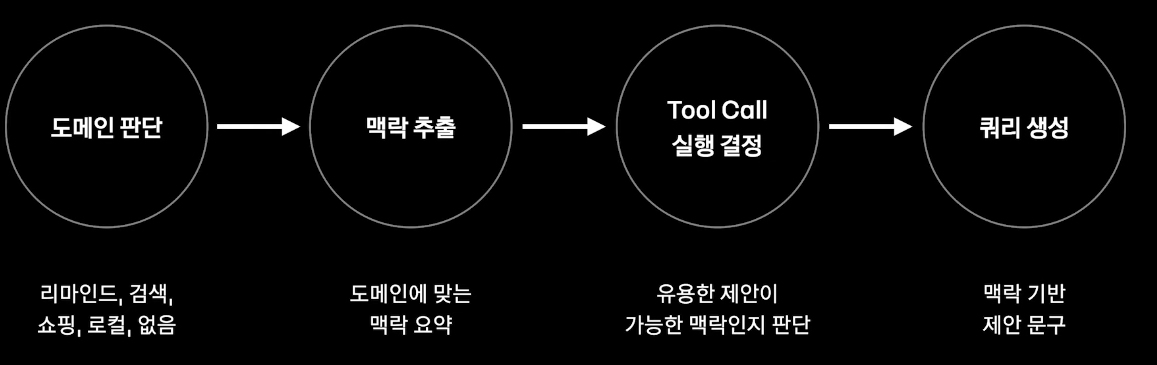
3-2. 맥락 추출 능력 학습
문제 상황
- 도메인이 갑자기 추가되거나 빠지는 경우에도 맥락을 추출할 수 있어야 함

해결책
- 맥락 추출은 도메인에 관계 없이 학습할 수 있으므로, 도메인이 없는 데이터를 추가해서 맥락 학습 데이터의 개수를 맞춤
(이건 내가 예전에 했던 오타 교정 프로세스와 비슷함)
3-3. 학습 데이터 구축
학습 데이터는 기반은 SNS 대화 데이터 활용
input 가공
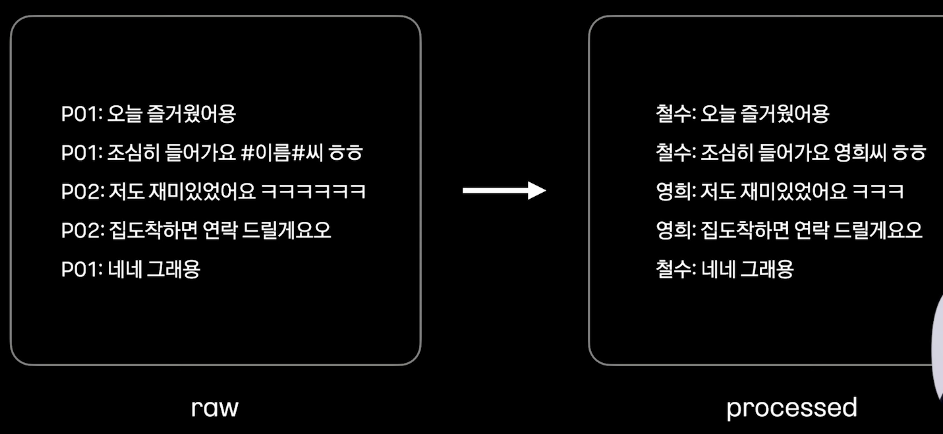
이때, 실제 상황과 동일하게 이름 부여 및 길어지는 것 방지하기 위해 정규화 (ㅋㅋㅋㅋㅋㅋ -> ㅋㅋㅋ)
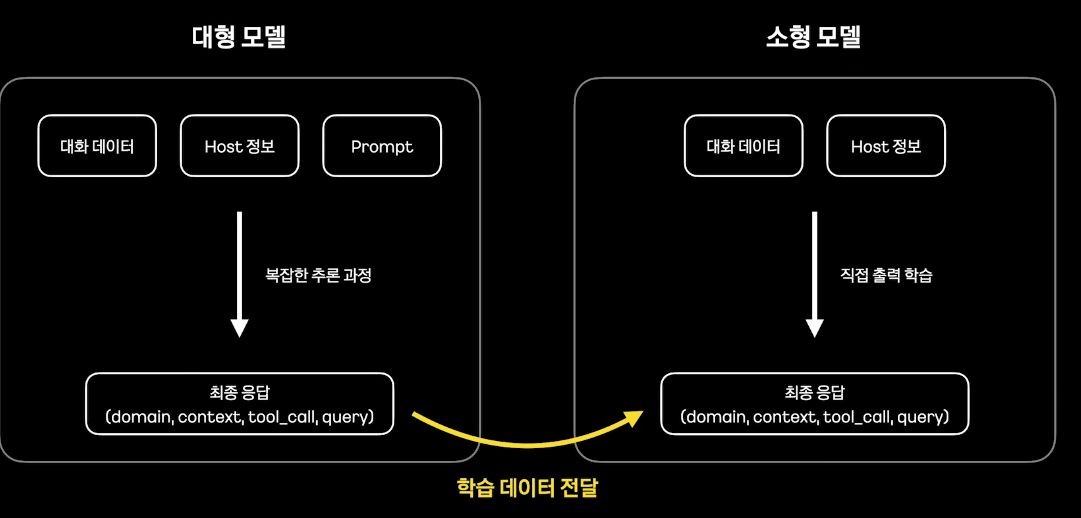
output 가공
대형 모델로 만든 정답으로부터 학습 데이터 구축
여기서 핵심은 host가 누구냐에 따라 모델 output이 달라지게 된다는 점
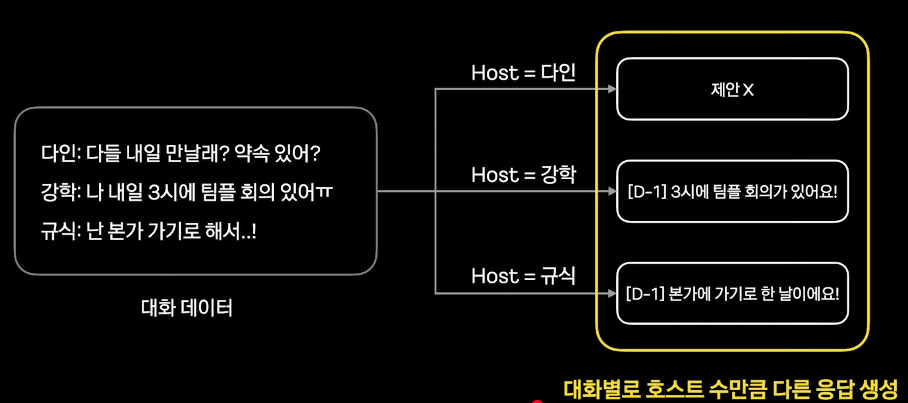
-> 같은 대화 데이터에서 호스트 정보만 바꿔가면서 모델 응답 생성
-> 학습 데이터 증강 및 호스트
3-4. 어떻게 학습 데이터 생성 모델(대형 모델)을 평가했는가?
맥락 추출 능력의 평가 지표 F4 (llm as a judge 활용)
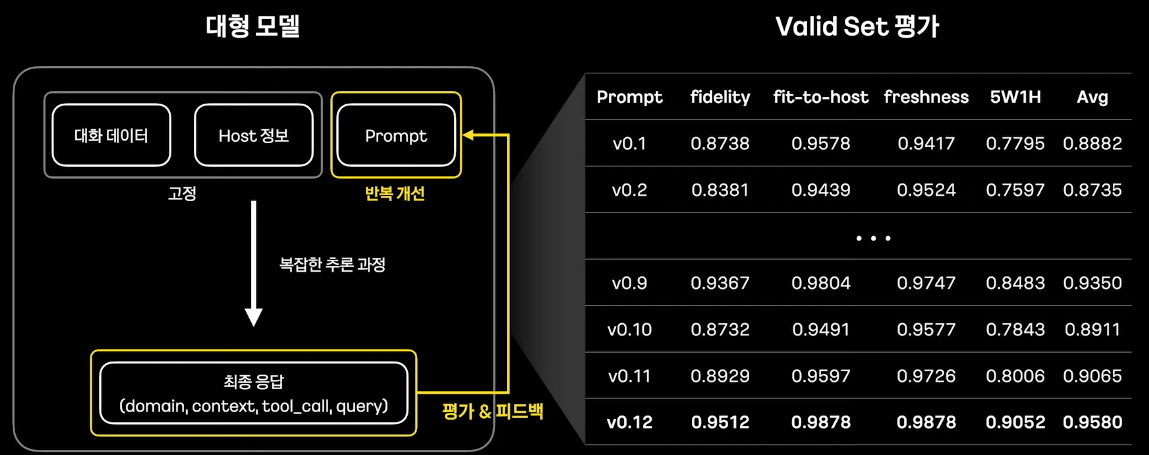
- 왜곡이 있는지
- 맥락이 원본 대화 왜곡했는지?
- Host 정보 반영
- 핸드폰의 주인의 호스트와 일치하는지
- 최신 정보 반영
- 대화가 최신 사항인지?
- 육하원칙 준수
- 뽑을 수 있는 6하원칙 요소를 뽑을 수 있었는지
4. 모델 학습 과정
4-1. 어떤 모델을 사용했고, 데이터는 어떤 걸 썼는가?
어떤 모델?
-> kanana nano 를 베이스로 활용
- 이러한 이유는 타 모델 대비 한국어 맥락 추출 성능 높음
- 타 모델에 비해 좋았던 이유는 '한국어로 학습'했기 때문
어떤 학습 데이터?
- 에서 만든 SNS 학습 데이터 활용
4-2. 모델 최적화
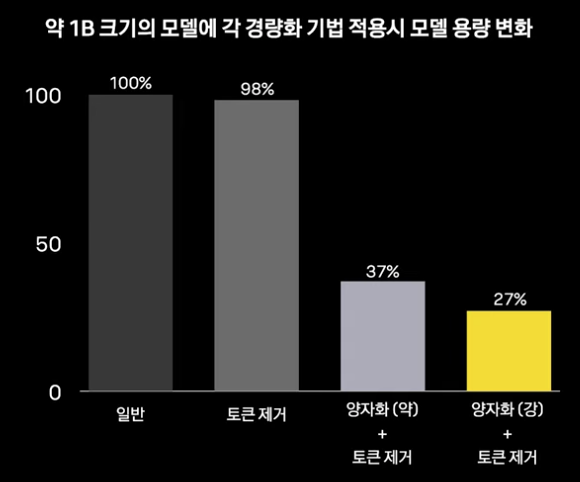
양자화 적용
모델 토큰 제거
- 외국어 및 사용량이 적은 영어 토큰 제거
- 모델 embedding 부분에 있어서의 경량화
Early Stop
- Domain이 '없음'까지 출력된 것을 확인하면 모델 출력 중단
4. 결과
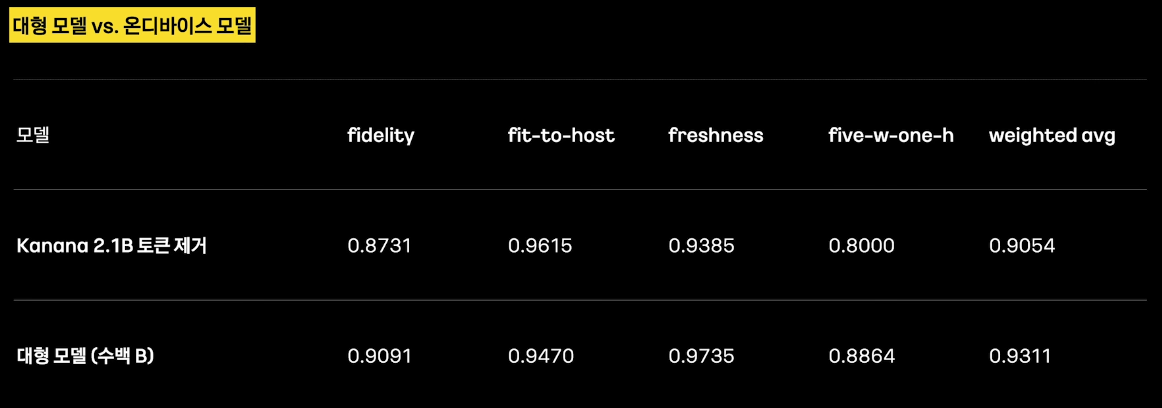
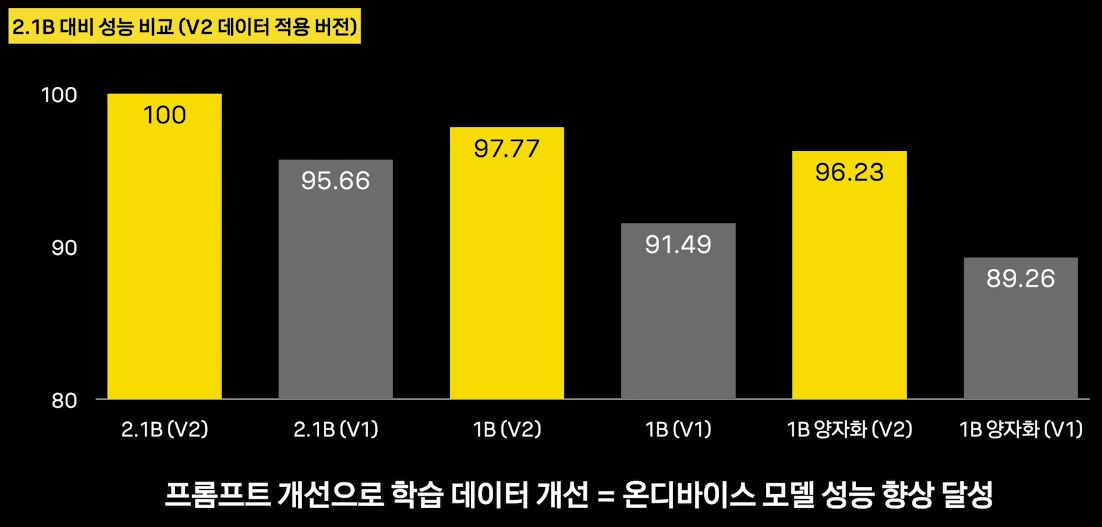
대형 모델과 온비다이스 모델 성능 비교
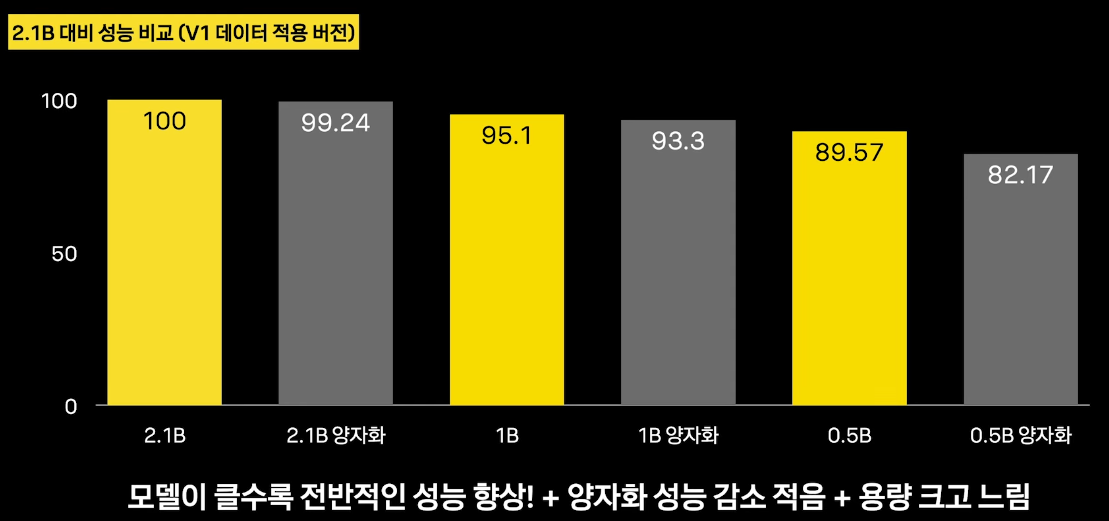
출력 예시

5. Future Work
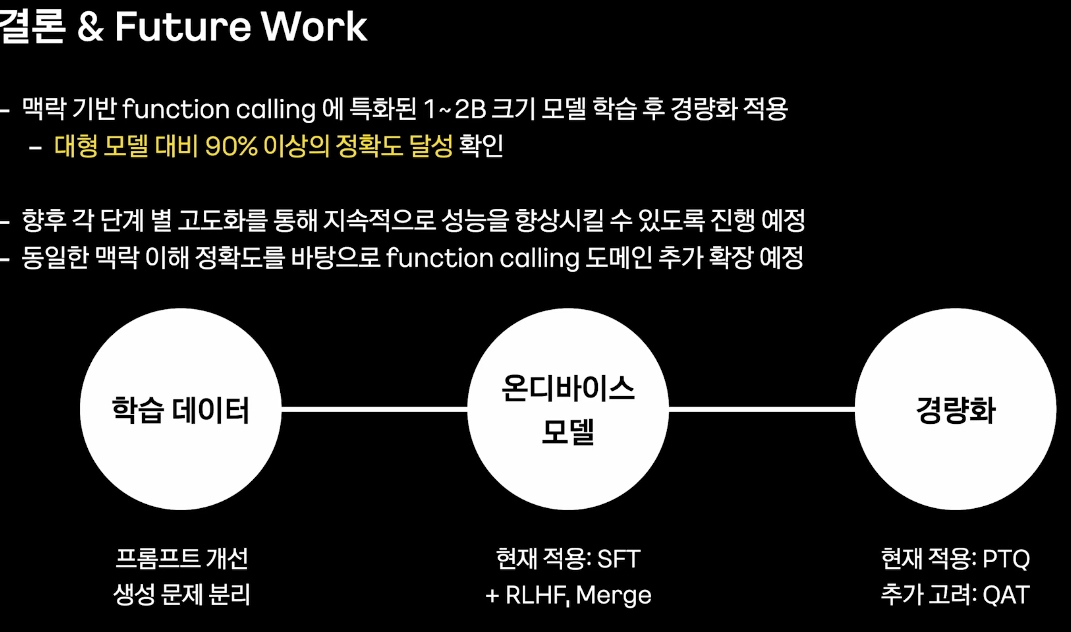
궁금한 점
- 도메인 판단 -> 맥락 추출 -> Tool calling 실행 결정 등의 프로세스인데, 결과의 출력 예시를 보면 domain 없음인데 context까지 출력이 다 나왔는지?
- 모델의 입력의 범위는 어떻게 설계 되었는지?
