해당 글은 밑바닥부터 시작하는 딥러닝 3권에 대한 글입니다.
1. 책 리뷰
이 책은 총 5장으로 이루어져 있으며 각각의 장에서 다루고자 하는 내용은 다음과 같다. (책에서는 각각을 '고지' 라고 표현하지만 이 글에서는 장이라고 표현한다.)
1장 - 미분 자동 계산
해당 장에서는 이 책에서 만드는 프레임워크인 dezero의 핵심적인 개념을 만들어나간다. 여기서 square함수 같이 인수가 하나인 함수의 순전파, 역전파가 구현된다.
2장 - 자연스러운 코드로
1장에서 인수가 하나인 함수를 다뤘다면 이제는 인수가 2개 이상인 +나 * 등의 함수에 대한 순전파, 역전파를 다룬다.
또한, dezero를 이용하는 사용자가 편하도록 취급하는 자료형을 늘린다.
3장 - 고차 미분 계산
2장까지는 단순 미분만 다루었다면 뉴턴 최적화와 같이 이계도함수가 필요한 방법을 위해 고차 미분을 다룬다.
4장 - 신경망 만들기
3장까지는 0차원 ndarray 즉, 스칼라(혹은 1차원 벡터)에 대한 순전파, 역전파를 다루었는데, 이를 확장하여 n차원 벡터와 행렬에 대한 순전파와 역전파를 다룬다.
dezero가 numpy 기반으로 만들어졌기 때문에, broadcasting 등을 신경쓰는데 이 점이 흥미롭다.
5장 - Dezero의 도전
이 프레임워크의 목적인 신경망을 다루기 위한 기초적인 작업은 4장까지 다루고 5장에서는 CNN, RNN 등의 응용적인 부분을 다룬다.
해당 리뷰에서는 내용을 모두 다루기보다는 핵심적인 밑바닥부터 신경망 구성까지의 개념을 어떻게 설계해나가는지에 대해 다룬다.
우선 핵심이 되는 개념 혹은 클래스를 살펴보면 다음과 같다.
Variable
- 데이터를 담고 있는 상자 (데이터의 형태는 언제나 np.ndarray이다.)
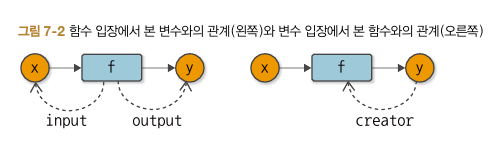
Function
- Variable 상자 안에서 ndarray 데이터를 꺼내 목적에 맞게 계산한 후 다시 ndarray 데이터를 Variable 객체로 포장해서 내보내는 것
- Input : Variable 객체
- Output : Variable 객체
Variable과 Function의 관계를 그림으로 표현하면 다음과 같이 표현할 수 있다.
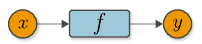
변수라는 상자에 값이 들어가면 함수는 그 포장을 벗기고 목적에 맞게 계산하여 상자에 다시 포장하여 내보낸다.
위 그림과 같이 Variable과 Function의 계산 관계를 표현한 그래프를 계산 그래프라고 한다.
앞으로는 위 그림과 같이 Variable은 동그라미, Function은 네모로 취급한다.
위 그림을 이어 붙이면 다음과 같이 합성함수도 표현할 수 있다.

역전파(backpropagation)
위에서까지 본 그림은 순전파(forward)의 과정이다.
신경망에서 자주 쓰이는 최적화 방법인 경사하강법 등의 방법을 이용하기 위해서는 우리는 각각의 파라미터들의 최종 출력값(Loss)에 대한 gradient를 알아야 한다.
컴퓨터가 gradient를 계산하는 방법으로 수치 미분도 쓰이긴 하지만, 많은 파라미터들의 gradient를 모두 구하기에는 적합한 방법이 아니다.
그래서 모두가 알고 있듯 dezero도 역전파 개념을 사용한다.
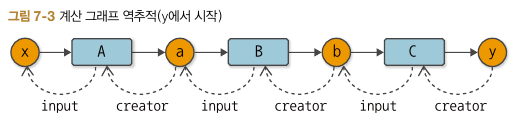
역전파는 chain rule을 기반으로 한 방법으로 위 그림 기준 dy/dx = dy/db * db/da * da/dx 임을 이용한다.
이때, dy/db = C'(b), db/da = B'(a), da/dx = A'(x) 이므로 다음과 같은 그림이 성립한다.

정리하자면, 계산 그래프의 역방향으로 미분값을 곱해주어 전달하면 각 변수들의 gradient를 구할 수 있는 것이다.
이걸 코드로 구현하기 위해 각각의 Function은 자신이 gradient를 전달할 input Variable과 이전까지의 gradient를 받아올 output Variable을 기억해야만 한다.
또한, 역전파가 한번에 끝날 수 있게 Varaible도 자신이 어떤 Function으로부터 나왔는지 기억해야 한다.
즉, Function과 Variable은 계산 그래프의 역순으로 갈 수 있게 서로의 관계를 기억해둬야만 한다.
따라서 다음과 같은 참조 관계가 있다면 재귀 또는 반복문 방식을 이용하여 역전파를 구현할 수 있다.
가변 길이 인수
이제까지는 단순히 하나의 input과 output을 가진 함수를 봤다.
input이 2개인 sum 함수와 같은 여러 개의 input을 가진 함수들을 다루기 위해서 Function 클래스에서 기존에 단일 변수로 다루던 Variable 객체를 list 또는 tuple로 다루기 시작한다.
그리고 가변 인수 * 를 이용하여 input이 몇 개든 다룰 수 있게 확장한다.
다만, 가변 인수가 되면서 복잡한 계산 그래프가 생기게 되는데 예를 들면 아래와 같다.
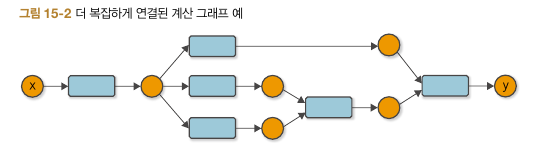
이 포스트에서는 역전파 함수를 자세히 다루진 않았지만 위 그림과 같은 경우 역방향으로 순서 없이 가게 되면 각 경로가 함수에 도달하는 순서가 달라져 x는 gradient를 여러 번 업데이트 하게 된다.
이를 해결하기 위해 단순 재귀 혹은 bfs 방식으로 구현했던 역전파 알고리즘에 우선순위를 만들어 해결한다.
(이렇게 책에서는 단순히 해결하면 될 것 같았던 문제들도 새로운 문제를 야기시켜 기존 개념과 잘 일치시켜야 한다.)
변수 사용성 개선
여태까지 함수의 input과 output은 항상 Variable로 고정되어 있었다. 하지만 매번 Variable 객체에 데이터를 넣어서 사용하기엔 불편하다.
따라서 함수의 input을 Varaible에서 ndarray로도 확장한다. 그리고 이를 넘어서 int와 float와도 연산이 가능하게 함수들을 정의한다.
2. 후기
책을 읽다보면 수학처럼 하나의 법칙을 발견하면 자연수 -> 정수 -> 유리수 -> 실수 -> 허수로 세계관을 확장시켜 나가는 dezero를 볼 수 있다. 책 제목처럼 정말 밑바닥부터 하나씩 만들어가는 것에서 재미를 느낄 수 있고, 새로운 개념을 하나씩 추가할 때마다 기존 dezero의 규칙을 지켜가는 저자의 설계를 보면 더욱 재밌다.
이 책을 읽으면서 프레임워크 설계는 어떻게 해야 하는지 배울 수 있었고, Define by Run 방식의 딥러닝 프레임워크가 어떻게 계산 그래프를 구축하고 역전파를 하는지 자세히 배울 수 있었다.
또한, 책에서 수치 미분, 파이썬 메모리 처리 방식, 클래스 문법, dot 언어, 뉴턴 최적화 등의 다양한 개념도 배울 수 있었다.
가장 좋았던 건 밑바닥부터 개념을 쌓아나가면서 거대한 프레임워크를 만든 경험을 통해 나름의 성취감과 자신감을 얻을 수 있었다는 것이다.
개인적 회고
처음에 책을 빨리 끝낼 생각에 내용을 수동적으로 읽고 생각 없이 코드만 따라치고 동작만 확인하면서 공부했다. 그런데 어느 순간부터 저자가 문제라고 생각하는 부분에 공감을 하지 못했고, 갑자기 왜 이 문장이 나왔는지 맥락을 놓치기 시작했다. 그러다가 결정적으로 책의 코드를 따라치던 중 ',' 하나를 못봤었는데, 디버깅이 너무 오래 걸렸다. 내가 처음부터 만든 프레임워크에서 디버깅이 이렇게 오래 걸리는 것을 보며, 또한, 단순한 ',' 부분이 핵심적인 문제를 해결한 것이었다는 걸 알고 중간 쯤 공부한 책을 처음부터 공부했다.
코드와 같이 학습하는 책은 어느 순간 코드를 따라치다가 동작이 이해가 안된거나 동작이 마냥 신기하다면 처음부터 다시 정리하면서 보는게 가장 빠르다는 것을 다시 한 번 배울 수 있었다.
이와 더불어 프로그래밍에서는 내가 여태까지 만든 함수나 클래스의 역할, 입출력의 범위가 명확하지 않으면 새로운 개념을 추가할 때 굉장히 헷갈린다는 점을 다시 느낄 수 있었다 !
