MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈 #3
지난 이슈에 대한 회상....
이전에 20만개의 데이터 삽입 시의 문제점은 looping을 통해 진행되는 save가 데이터의 리스트 크기만큼 DB에 접근해 발생하는 네트워크 overhead 였습니다.
이를 해결하기 위해 매번 DB에 접근한게 아니라, Batch insert 방식으로 list로 한번에 저장해야겠다고 생각했고 그 방법은 saveAll 메서드를 이용하여 해결가능했습니다.
자세한 내용은 이슈정리 #2 의 글을 통해 확인하시면 될 듯 합니다 😊
이번에도 문제는 계속되었다..
다시 한번더 언급하겠습니다.
'MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈' 시리즈에서는,
고객의 요청으로 삽입시 수용가능한 데이터의 크기가 점점 늘어나면서 최종적으로는 300만개까지 삽입을 처리하였고 처리과정에서 어떤 문제가 발생했는지 그리고 왜 300만개 까지만 확인 가능하였는지를 말씀드리겠습니다!
이번 글은 200만개 처리 시 발생한 문제를 기반으로 작성하겠습니다!
확인해주세여!
글을 보시기전 ! 삽입되는 데이터 하나의 크기는 330Byte 였으며,
필자는 맥북프로19 - (6코어, 메모리 16GB)의 데스크 탑으로 실행했음을 말씀드립니다 👌
200만개 이상 삽입시 발생하는 OOM 문제
삽입되는 데이터의 갯수를 200만개 이상으로 늘리면서 문제가 발생했습니다!
발생한 오류의 로그는 아래와 같은데요?!
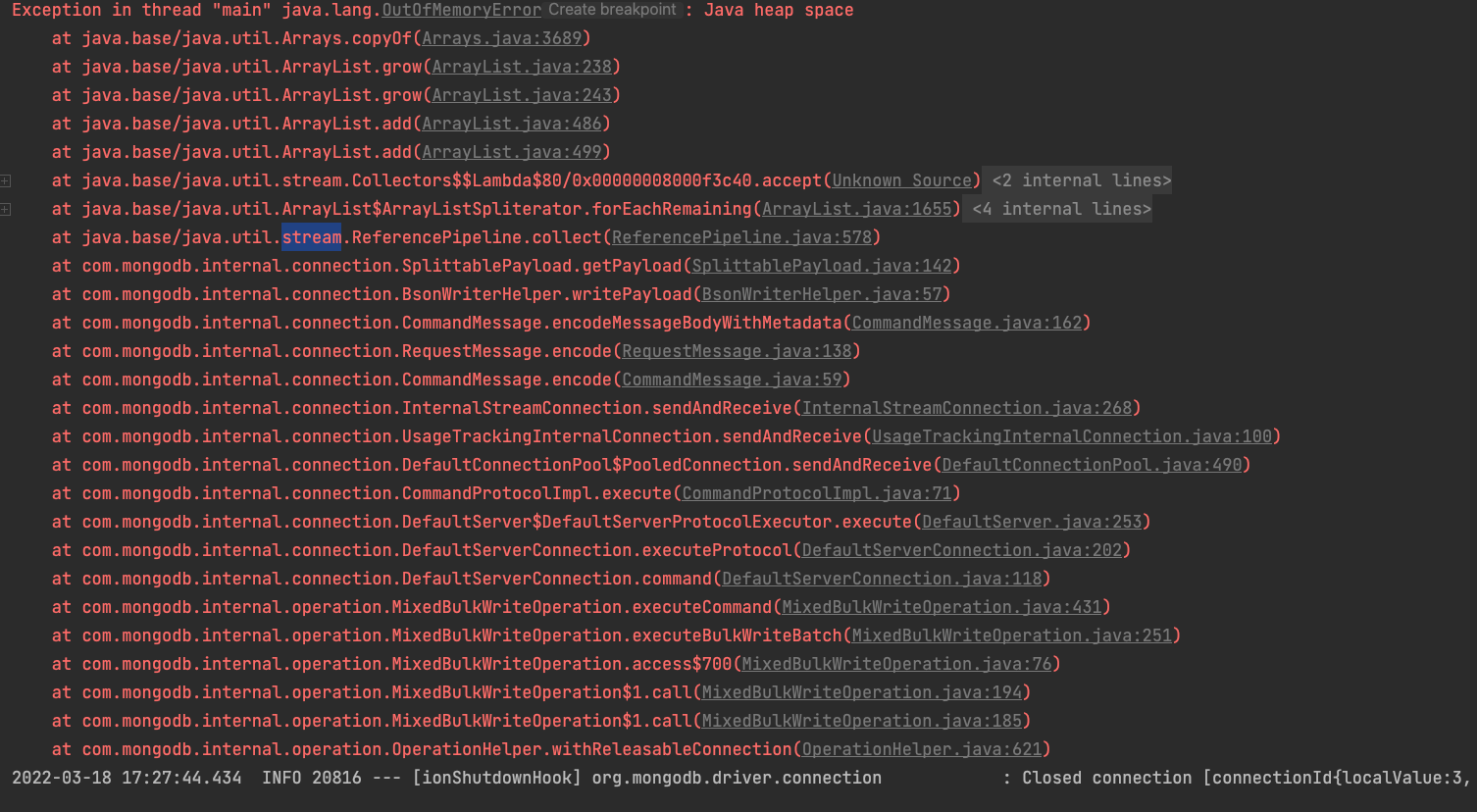
네 첫줄에서 확인이 가능하죠? ㅎㅎ
메인 스레드에서의 Out of Memory 문제가 발생한 것 입니다.
jvm의 heap 공간에서 메모리가 넘친것 같습니다 ㅠㅠ
왜 넘쳤을까요..? error log를 다시 한번 확인했습니다.
ArrayList의 크기가 계속 커지면서 발생한 OOM인것 같네요,,
Java에서는 ArrayList에 element를 add하려고 할 때, capacity가 배열의 길이와 같아지면 용량을 resize 합니다. 그리고 resize된 배열에 기존 elementData를 copy하는 과정으로 진행됩니다 😊
이런 원리로 ArrayList가 늘어나고 copy 하면서 최종적으로 오류가 발생했는 것 같습니다..
"다 좋다 이거야! 근데 왜? 언제? ArrayList에 element를 add하고 있는거지 ?? "
조금 더 에러 로그의 아래로 가보겠습니다.
💁 맨 밑에서부터 흐름을 한번 확인해 보겠습니다!
- saveAll을 통한 Bulk Write Opertaion이 정상적으로 호출 됨을 확인했습니다
- DB에 connection이 연결되고 saveAndReceive 과정이 진행되었습니다.
- BsonWriter 작업이 진행 중인걸 보아하니, DB의 Document 값이 java의 객체로 적혀지고 있는 것 같습니다.
- 그리고 이렇게 생성된 객체의 Stream을 collect를 통해 ArrayList로 합치고 있습니다.
- 합쳐지는 과정속에서 ArrayList의 크기가 계속 커지고 복사되고 커지고 복사되고 있습니다.
생각해낸 결론 :
아.. saveAll을 진행하면 정상적으로 DB에 잘 삽입된 객체들이 ArrayList의 형태로 반환되고, 그 과정속에서 동적 메모리의 크기가 jvm의 heap size를 넘어버렸구나...
그럼 어떻게 해 ?
MySQL과 JpaRepository를 사용한 경우 saveAll 이후, 반환되는 값을 거부할 수 있는 방법이 있다고 합니다...
하지만 제가 부족한 것인지 MongoRepository에서는 이를 거부하는 방법을 찾지 못했습니다.
결론은,
chunk 단위로 전체 dataList를 쪼개서 보내자.
그럼 반환 값도 작을테니 OOM 문제도 안생길 것이며 중간중간 GC가 적용되면 최종적으로 괜찮지 않을까..?
라는 결론에 도달했고 바로 테스트 해 보았습니다!
chunk단위로 나눈 코드
public void insertAll(MetaDataCreateAllRequestDto metaDataCreateAllRequestDto){
...
List<MetaData> metaDataList = new ArrayList<>();
for(Document body : bodyList){
MetaData metaData = new MetaData().builder()
.projectId(projectId)
.body(body).build();
metaDataList.add(metaData);
}
int chunk_size = 1000;
for (List<MetaData> batch : Lists.partition(metaDataList,chunk_size)) {
metaDataRepository.saveAll(batch);
}
...
}예상대로 위 코드로 삽입을 진행했을 시, 200만개에서 OOM이 발생하지 않음을 확인했습니다!!
🥇 정리!
DB에 데이터를 삽입하고 정상적으로 수행된 값들이 다시 반환되면서 OOM을 발생시킨 경우였습니다.
전혀 생각지도 못한 곳에서 발생한 오류라 당황스러웠는데요 그래도 하나하나 이유를 짚어보고 어떻게 해결할 지 고민해볼 수 있었던 재밌는 경험이었습니다. ㅎㅎ 👍😏😏
다음글 예고..
재밌는 경험은 무슨 ㅋㅋ..
300만개 넣으니깐 바로 터졌습니다 ㅎㅎㅎ
다음글에서는 300만개 삽입시 터진이유와 왜 300만개에서 더 늘리지 못했는지 그 이유에 대해서 작성하겠습니다 ^^
읽어 주셔서 감사합니다! 잘못된 점이 있다면 댓글로 남겨주세요 더 공부하겠습니다.
