MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈
1.MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈 #1

1. 발생 배경 프로젝트를 진행하면서 5만개 이상의 메타데이터를 삽입할 필요가 생겼다. 기존의 메타데이터 삽입 과정은 아래와 같았다. 5개의 메타데이터를 저장하기 위해서는 클라이언트 단에서 5번의 삽입 api를 호출하여 진행하였다. 서버는 개별적인 메타데이터를 jp
2022년 2월 2일
2.MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈 #2
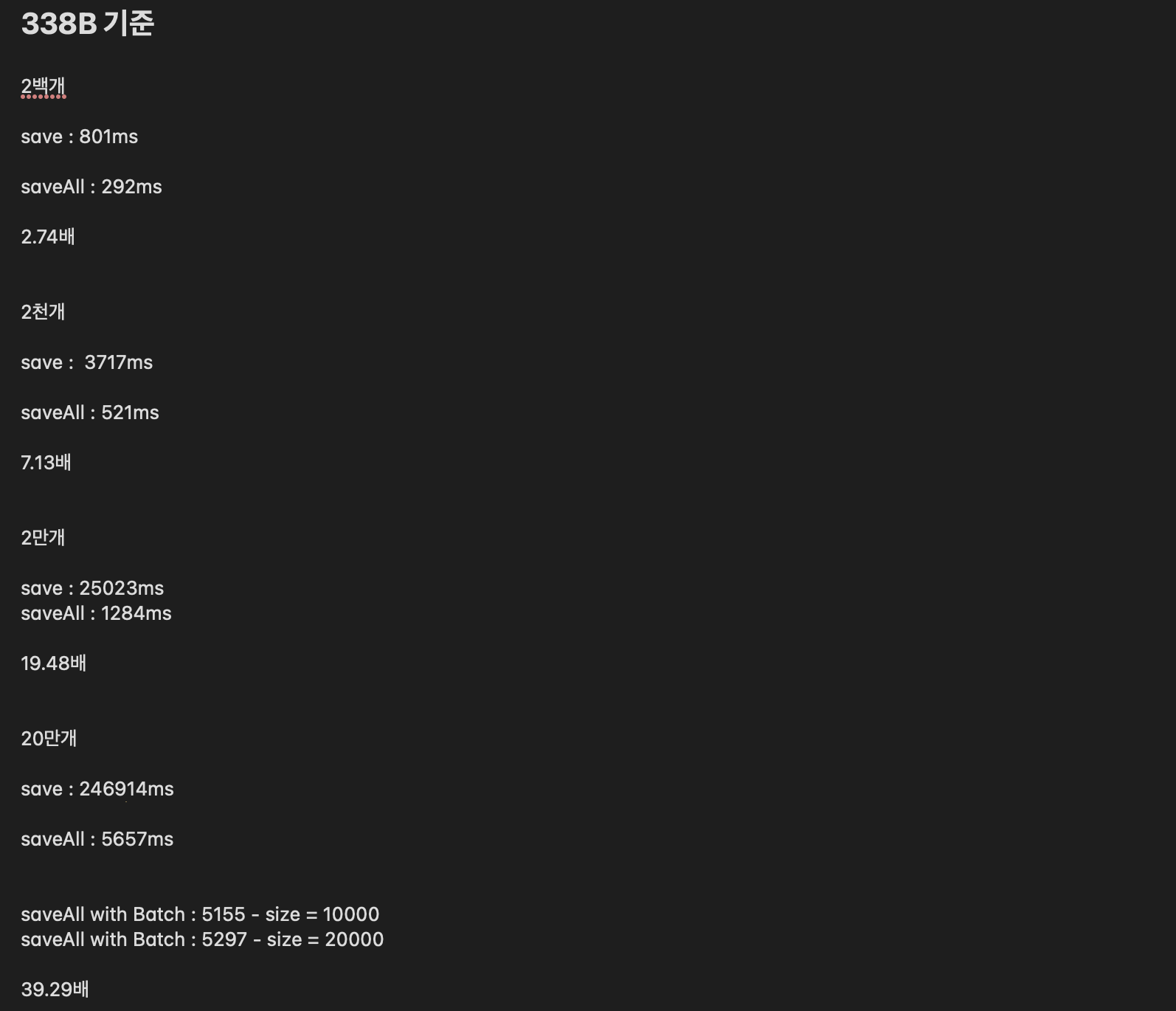
saveAll을 통한 성능 개선
2022년 3월 25일
3.MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈 #3
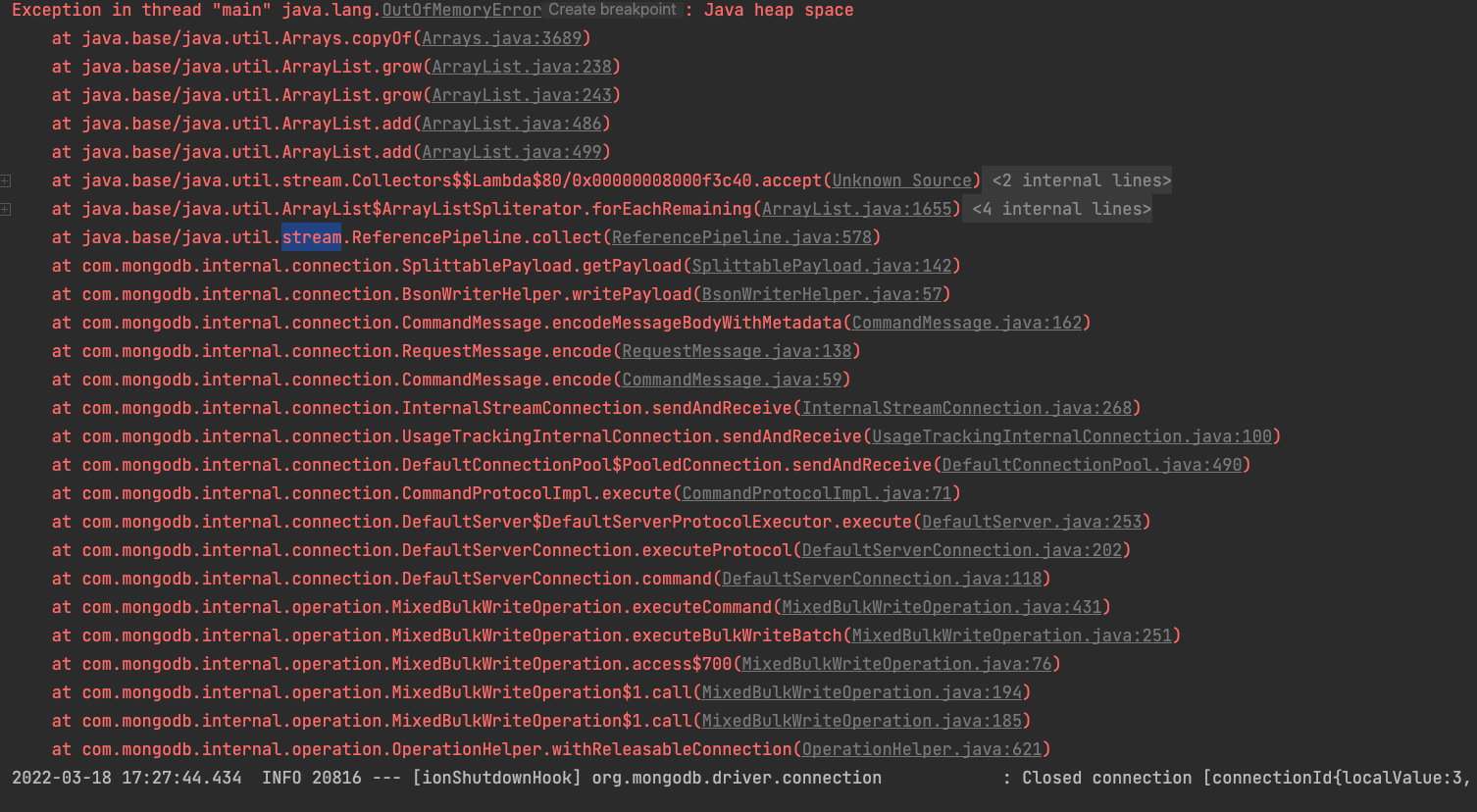
이전에 20만개의 데이터 삽입 시의 문제점은 looping을 통해 진행되는 save가 데이터의 리스트 크기만큼 DB에 접근해 발생하는 네트워크 overhead 였습니다.이를 해결하기 위해 매번 DB에 접근한게 아니라, Batch insert 방식으로 list로 한번에
2022년 3월 25일
4.MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈 #4
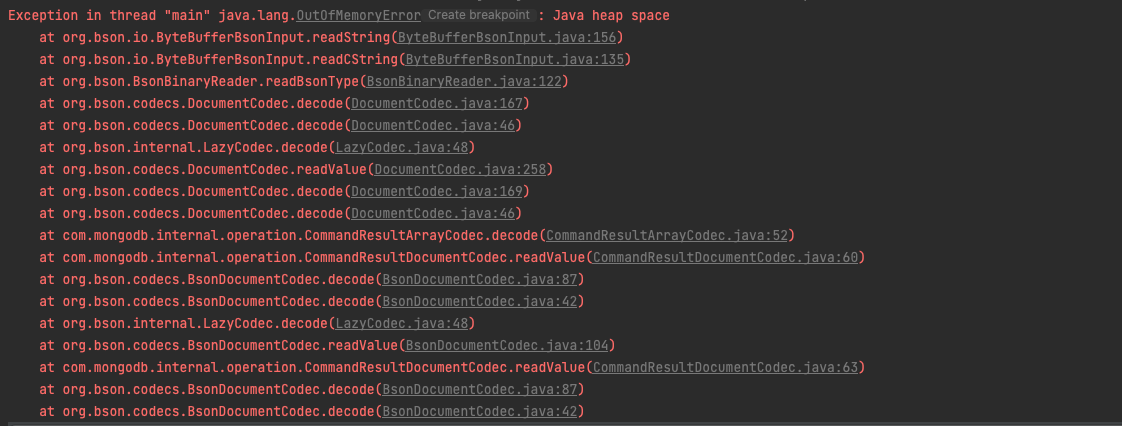
지난 이슈는 200만개의 데이터를 saveAll 메서드를 통해 수행하던 중 OOM을 만났고 해결한 문제를 말씀드렸습니다. Chunk_size로 데이터 리스트를 분할하여 문제를 해결할 수 있었던 경우였습니다!자세한 내용은 \[이슈정리다시 한번더 언급하겠습니다. 'Mong
2022년 3월 25일