MongoRepository를 통한 대량 데이터 삽입시 발생한 이슈 #2
지난 이슈에 대한 회상....
이전에 5만개의 데이터를 처리 했을 때의 문제점은 클라이언트에서 요청하는 save API의 횟수였습니다.
즉 5만개라면 5만번의 API의 요청이 필요하고 이는 클라이언트와 서버간의 통신 측면에서 보았을때 굉장히 비효율 적입니다!
최종적으로, 데이터를 리스트로 받아 들여 5만개의 데이터를 한번의 API로 처리하는 방법으로 문제를 해결 할 수 있었습니다.
자세한 내용은 이슈정리 #1 의 글을 통해 확인하시면 될 듯 합니다 😊
문제는 해결되지 않았다..
사실 이전에 5만개의 데이터를 처리하면서 대량 데이터라고 말했던 것이 조금 부끄러워졌습니다 ..ㅎ
고객의 요청으로 삽입시 수용가능한 데이터의 크기가 점점 늘어나면서 최종적으로는 300만개까지 삽입을 처리하였고 처리과정에서 어떤 문제가 발생했는지 그리고 왜 300만개 까지만 확인 가능하였는지를 말씀드리겠습니다!
이번 글은 20만개 처리 시 발생한 문제를 기반으로 작성하겠습니다 ㅎㅎ
확인해주세여!
글을 보시기전 ! 삽입되는 데이터 하나의 크기는 330Byte 였으며,
필자는 맥북프로19 - (6코어, 메모리 16GB)의 데스크 탑으로 실행했음을 말씀드립니다 👌
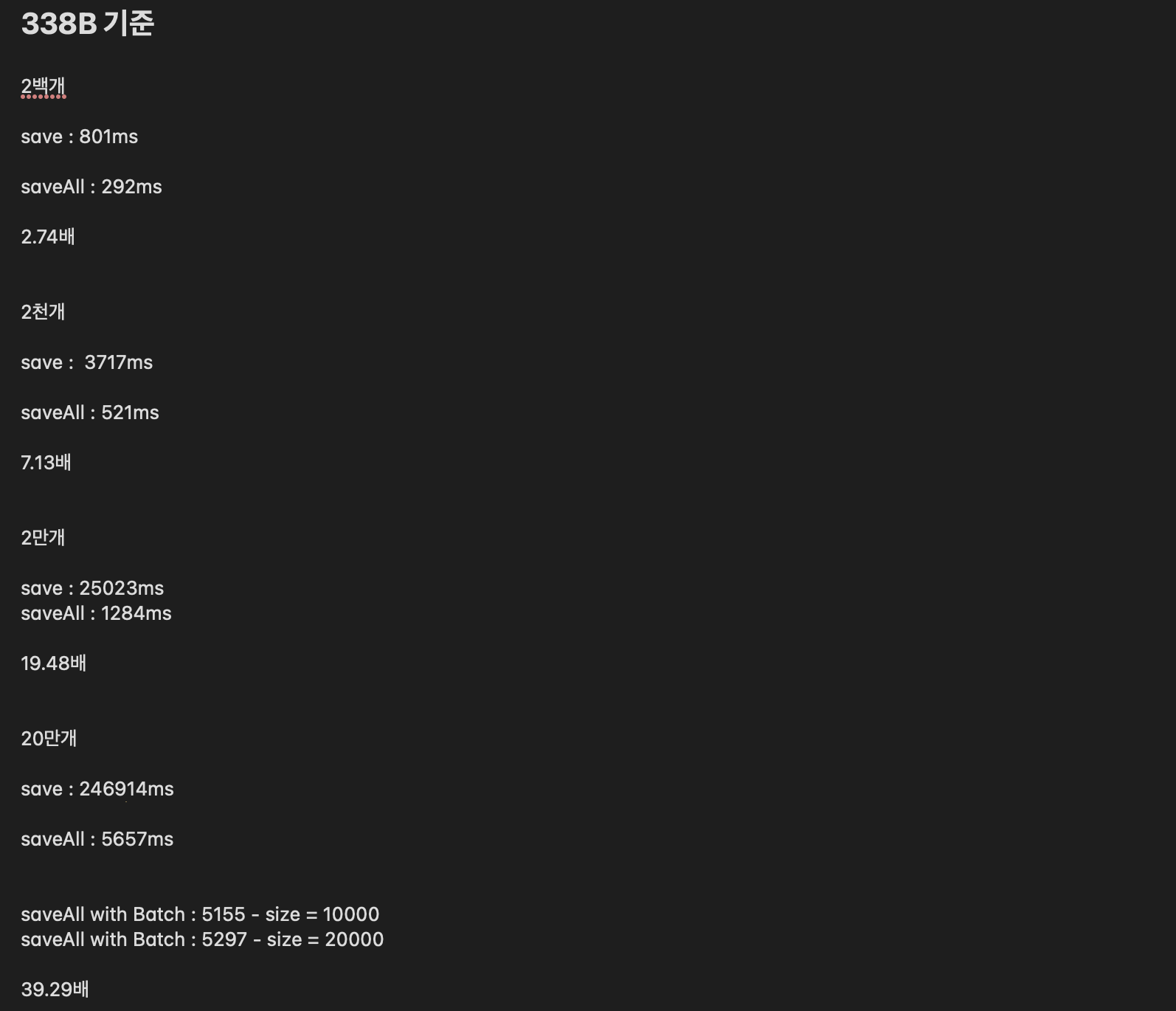
20만개 삽입시 4분이 넘어가는 소요시간
삽입되는 데이터의 갯수가 5만개에서 20만개로 늘어나면서 문제가 발생했습니다!
이전 포스트의 코드를 보고 오셨다면, 아마도 짐작하실 수 있으리라 생각합니다 ㅠㅠ
한번 더 지난 코드를 보겠습니다.
public void insertAll(MetaDataCreateAllRequestDto metaDataCreateAllRequestDto){
...
for(Document body : bodyList){
MetaData metaData = new MetaData().builder()
.projectId(projectId)
.body(body).build();
metaDataRepository.save(metaData);
}
...
}간략하게 설명하고자 하는 핵심 코드 위주로 설명하겠습니다.
먼저 결론만 말씀드리면, 위 코드로 삽입을 진행했을 시 246914ms 즉 4분이 살짝 넘는 시간이 소요 됨을 확인했습니다..
이대로는 문제가 있다고 생각해 원인을 분석하기 위해 save method의 내부 로직을 확인하였습니다.
한번 같이 확인하고 가겠습니다 😭
/*
* (non-Javadoc)
* @see org.springframework.data.repository.CrudRepository#save(java.lang.Object)
*/
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null!");
if (entityInformation.isNew(entity)) {
return mongoOperations.insert(entity, entityInformation.getCollectionName());
}
return mongoOperations.save(entity, entityInformation.getCollectionName());
}간략하게 설명 해드리겠습니다.
먼저 save에 사용되는 entity가 새로운 값인가 아닌가에 따라 크게 2가지 로직으로 구분이 됩니다.
isNew() 함수는 entity의 @Id의 필드값의 존재 유무를 확인합니다! null이거나 0이면 isNew()가 true를 반환하고 insert 함수를 호출합니다.
반대로 값이 존재하면 false를 반환하여 save 함수를 호출함을 확인했습니다.
저는 삽입되는 데이터가 어차피 @Id의 필드값 null이기에 insert를 계속 따라가다 보았습니다.
insert 내부 로직은 또 doInsert() 로 연결되어 있었습니다.
doInsert()의 코드를 확인해 보겠습니다.
protected <T> T doInsert(String collectionName, T objectToSave, MongoWriter<T> writer) {
BeforeConvertEvent<T> event = new BeforeConvertEvent<>(objectToSave, collectionName);
T toConvert = maybeEmitEvent(event).getSource();
toConvert = maybeCallBeforeConvert(toConvert, collectionName);
AdaptibleEntity<T> entity = operations.forEntity(toConvert, mongoConverter.getConversionService());
entity.assertUpdateableIdIfNotSet();
T initialized = entity.initializeVersionProperty();
Document dbDoc = entity.toMappedDocument(writer).getDocument();
maybeEmitEvent(new BeforeSaveEvent<>(initialized, dbDoc, collectionName));
initialized = maybeCallBeforeSave(initialized, dbDoc, collectionName);
Object id = insertDocument(collectionName, dbDoc, initialized.getClass());
T saved = populateIdIfNecessary(initialized, id);
maybeEmitEvent(new AfterSaveEvent<>(saved, dbDoc, collectionName));
return maybeCallAfterSave(saved, dbDoc, collectionName);
}doInsert() 에서는,
MongoDB에 들어가는 entity를 초기화 하고, insertDocument() 메서드를 통해 삽입되는 과정이 계속 진행되었습니다.
🤨 즉 insert시 DB에 매번 접근하여 document를 삽입하고 있음을 확인했습니다...
아 혹시 궁금해 하시는 분들을 위해 insert가 아닌, save는 entity의 버젼을 확인해 업데이트를 진행합니다 ^^

⭐️ 해결방법은 saveAll()을 이용한 Bulk Insert !
이러한 네트워크 overhead를 해결하기 위해 매번 DB에 접근한게 아니라, Bulk insert 방식으로 document list로 한번에 저장해야겠다고 생각했습니다.
이 문제의 해결방안은 saveAll() 인데요! 이 역시, 내부 로직을 확인해 보겠습니다.
@Override
@SuppressWarnings("unchecked")
public <T> Collection<T> insert(Collection<? extends T> batchToSave, String collectionName) {
Assert.notNull(batchToSave, "BatchToSave must not be null!");
Assert.notNull(collectionName, "CollectionName must not be null!");
return (Collection<T>) doInsertBatch(collectionName, batchToSave, this.mongoConverter);
}제가 원하는 Bulk insert를 진행하고 있음을 확인했습니다 !!
그럼, Bulk insert를 사용하기 위해 saveAll()을 사용한 최종 코드를 확인해 보겠습니다!💁
public void insertAll(MetaDataCreateAllRequestDto metaDataCreateAllRequestDto){
...
for(Document body : bodyList){
MetaData metaData = new MetaData().builder()
.projectId(projectId)
.body(body).build();
metaDataList.add(metaData);
}
metaDataRepository.saveAll(metaDataList);
...
}🥇 결론
실제로 saveAll을 통한 삽입 시 5초 만에 20만개의 메타데이터를 삽입하였고, 기존의 save에 비해 약 4분 정도의 성능 개선을 확인했습니다.
또, 현재 테스팅 시 가장 흔히 삽입 하는 개수인 약 200개정도의 데이터 크기에서는 50% 정도의 성능개선을 확인했습니다!
(튜닝 전 응답 속도 – 튜닝 후 응답 속도) x 100 / 튜닝 후 응답 속도 = 개선율(%)
- 200개 기준 save 평균 소요시간 : 500ms
- 200개 기준 saveAll 평균 소요시간 : 330ms
개선율 = 51%
개선율은 데이터의 크기가 커지면, 커질수록 증가하고, 20만개 기준시 4200% 정도의 개선율이 확인됩니다..
다음글 예고..
다음글은 saveAll을 이용해 삽입하던 중 200만개 이상시 발생한 문제점에 대하여 작성하겠습니다!
읽어 주셔서 감사합니다! 잘못된 점이 있다면 댓글로 남겨주세요 더 공부하겠습니다ㅠㅠㅠ
