싸피의 특화 프로젝트를 진행하면서 약 16만건의 데이터를 빠르게 넣었던 방법을 공유해보고자 한다.
백엔드 역할을 맡으며 자연스럽게 데이터도 만들어줘야 했다.
Pandas를 사용해서 데이터 전처리 작업을 수행하고 약 16만개의 행을 가진 부동산 매물 데이터를 RDBMS에 넣어야 했다.
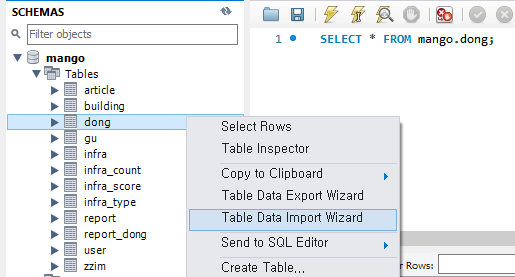
우리는 AWS의 RDS(MySQL)을 메인 DB로 선택해서 사용중이었고 Workbench를 통해 RDS 엔드포인트에 접속하여 사용중이었다.
이전에 465개의 행을 가진 법정동 데이터는 Workbench의 기능 중 Table Data Import Wizard를 통해 insert 해주었다. 이때, 3분 이상이 걸렸다.
하지만 이번에 내가 넣어야 하는 부동산 매물 데이터는 165000+개의 행과 14컬럼을 가진 데이터이다.
생각만해도 얼마나 오래걸릴지 감도 안온다...
그래서 대량의 데이터를 빠르게 DB에 넣을 방법이 필요했다.
터미널을 통한 데이터 import
구글링을 통하여 터미널 창에서 csv 파일을 읽어 와서 데이터를 넣는 방법을 발견하였다.
하지만 해당 방법은 local에 띄운 MySQL만 가능한 방법이어서 다음의 절차를 따르기로 했다.
- 로컬 MySQL에 RDS와 똑같은 테이블을 만들고, 터미널을 통해 데이터를 집어넣는다.
- 해당 테이블의 데이터를 sql파일로 export 시킨 후, 이것을 AWS RDS 엔드포인트에 MySQL Workbench로 접속한 뒤, sql을 실행시켜 준다.
해당 방법이 데이터가 많아도 매우 간단하고 빠르게 데이터가 넣어지는것을 기존에 확인 했었기 때문에 해당 방식을 사용하기로 했다.
1. 로컬 데이터베이스에 집어넣기
터미널 창을 킨 뒤, 로컬에 있는 mysql 서버에 접속해주었다
$ mysql -uroot -p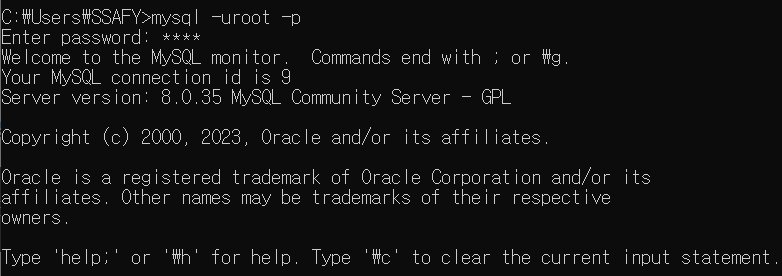
다음으로, local_infile을 확인해준다. OFF가 되어있으면 ON으로 바꿔줘야한다.
해당 설정은 내 로컬컴퓨터에 있는 csv파일을 읽어오기 위한 설정이다.
$ set global local_infile = 1;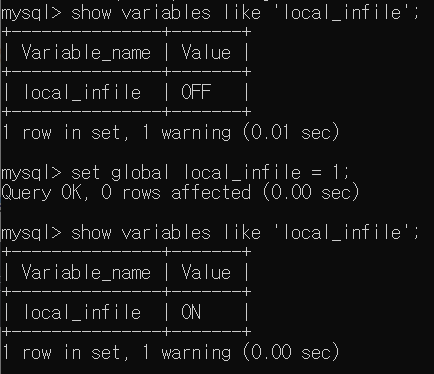
local_infile이 ON이 되었으면 mysql 서버에서 local file을 읽어 올 수 있게 C:/ProgramData/MySQL/MySQL Server 8.0/Uploads 경로에 내가 사용할 csv 파일을 넣어주자.
이후에 아래를 실행시키면 데이터가 해당 테이블에 들어가게된다.
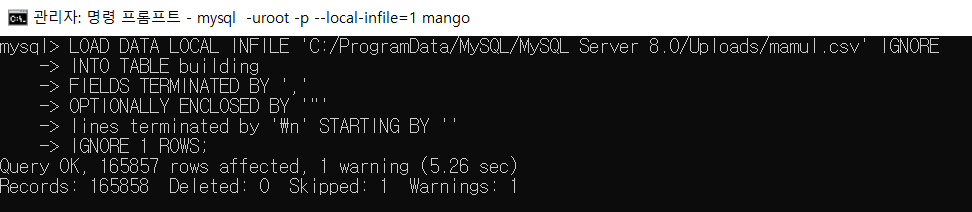
165000+개의 데이터를 넣는데, 5.26초가 걸렸다.
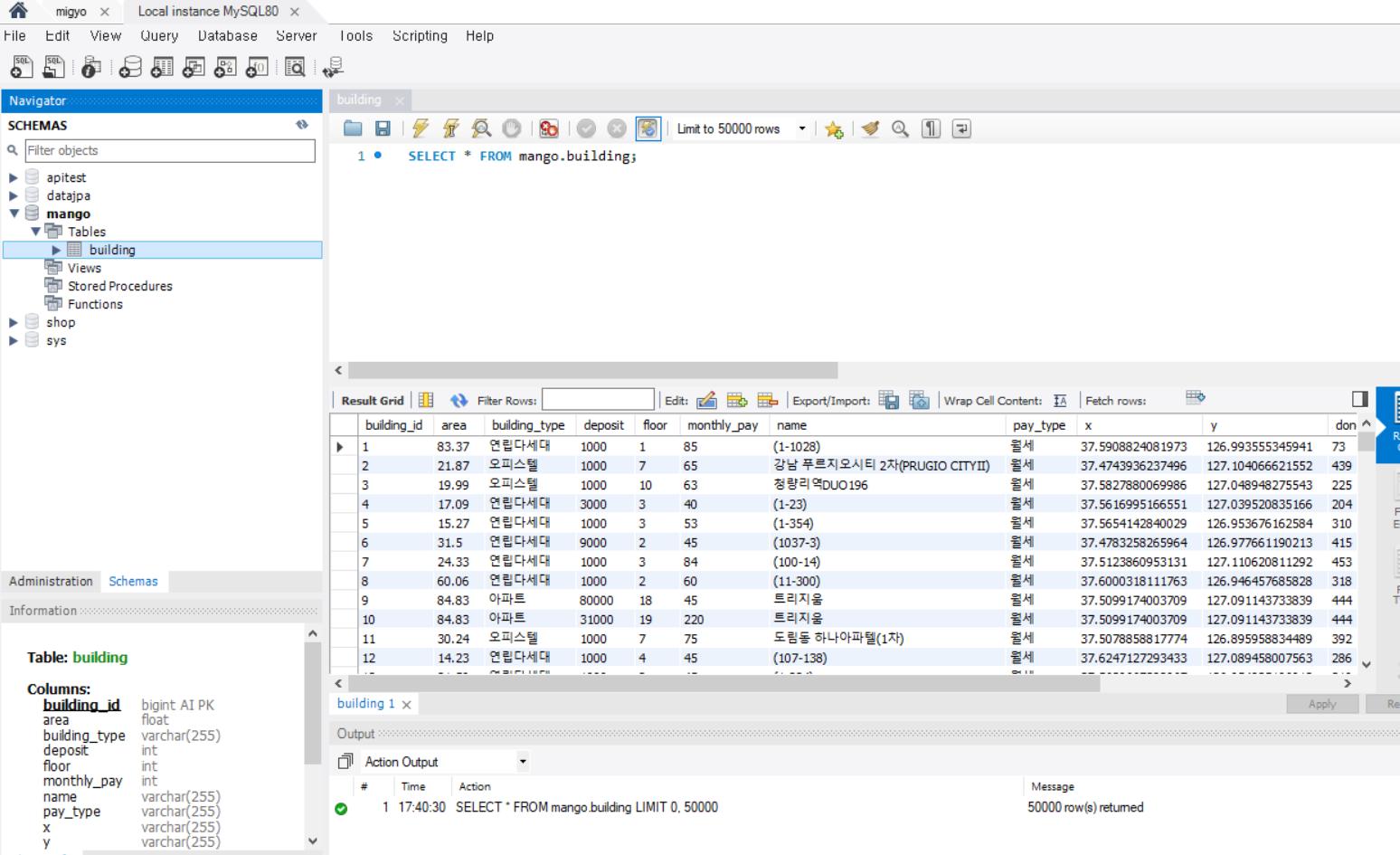
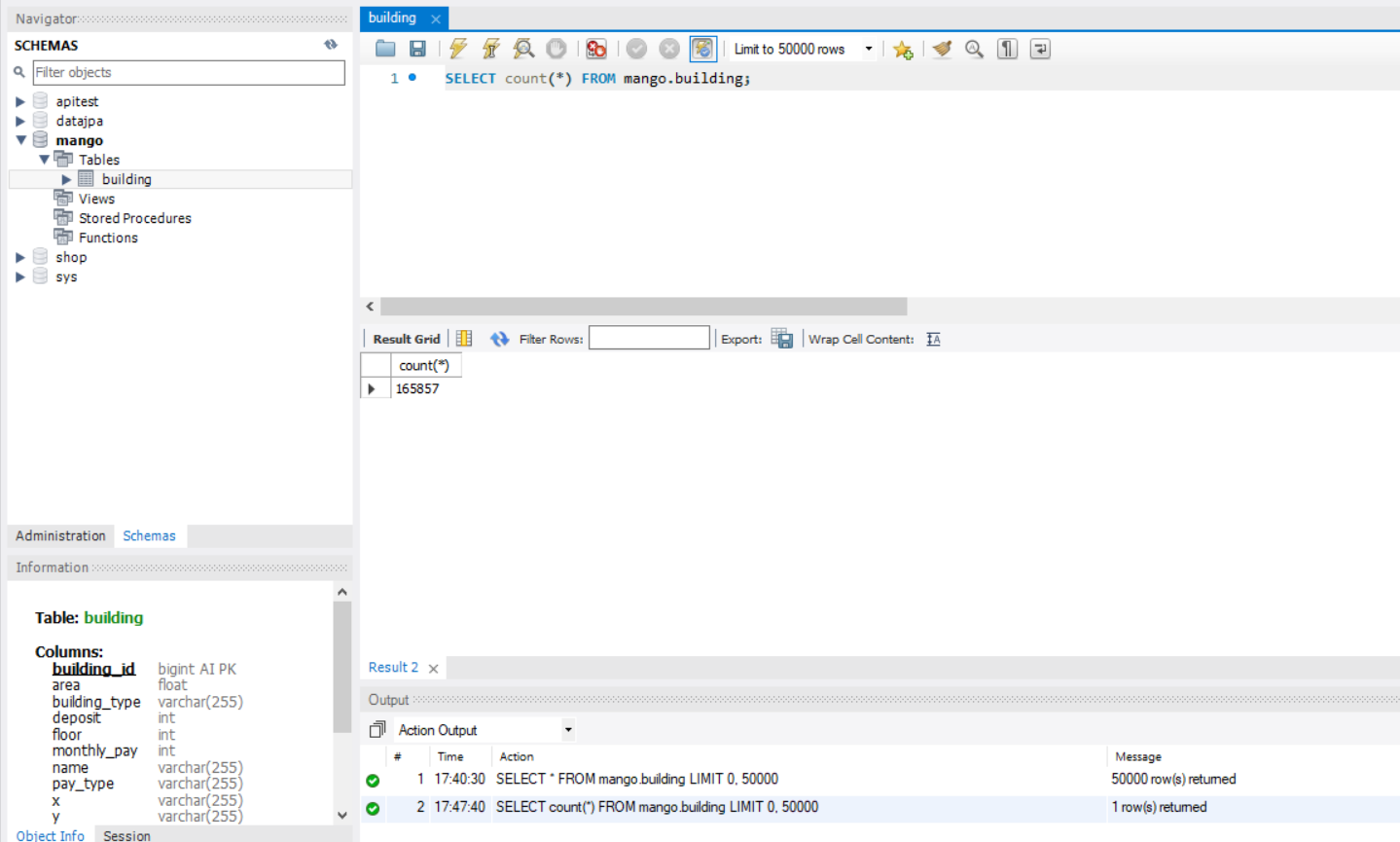
데이터가 잘 들어가있다.
2. export 시킨 후, AWS RDS에 접속하여 쿼리문을 실행시키기
로컬의 데이터베이스 테이블에 잘 들어갔으니 해당 데이터를 export 시켜보겠다.
결과로 아래의 sql 파일을 얻었다.
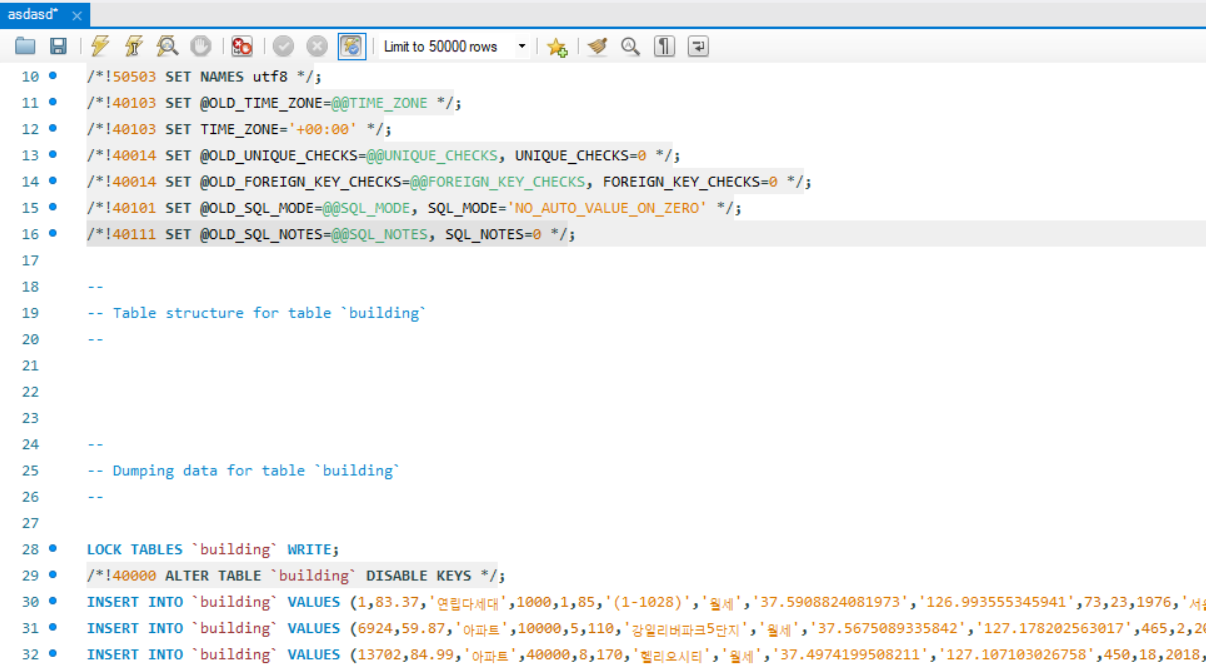
AWS RDS에 MySQL Workbench로 접속 후, 해당 sql파일을 실행하였다.
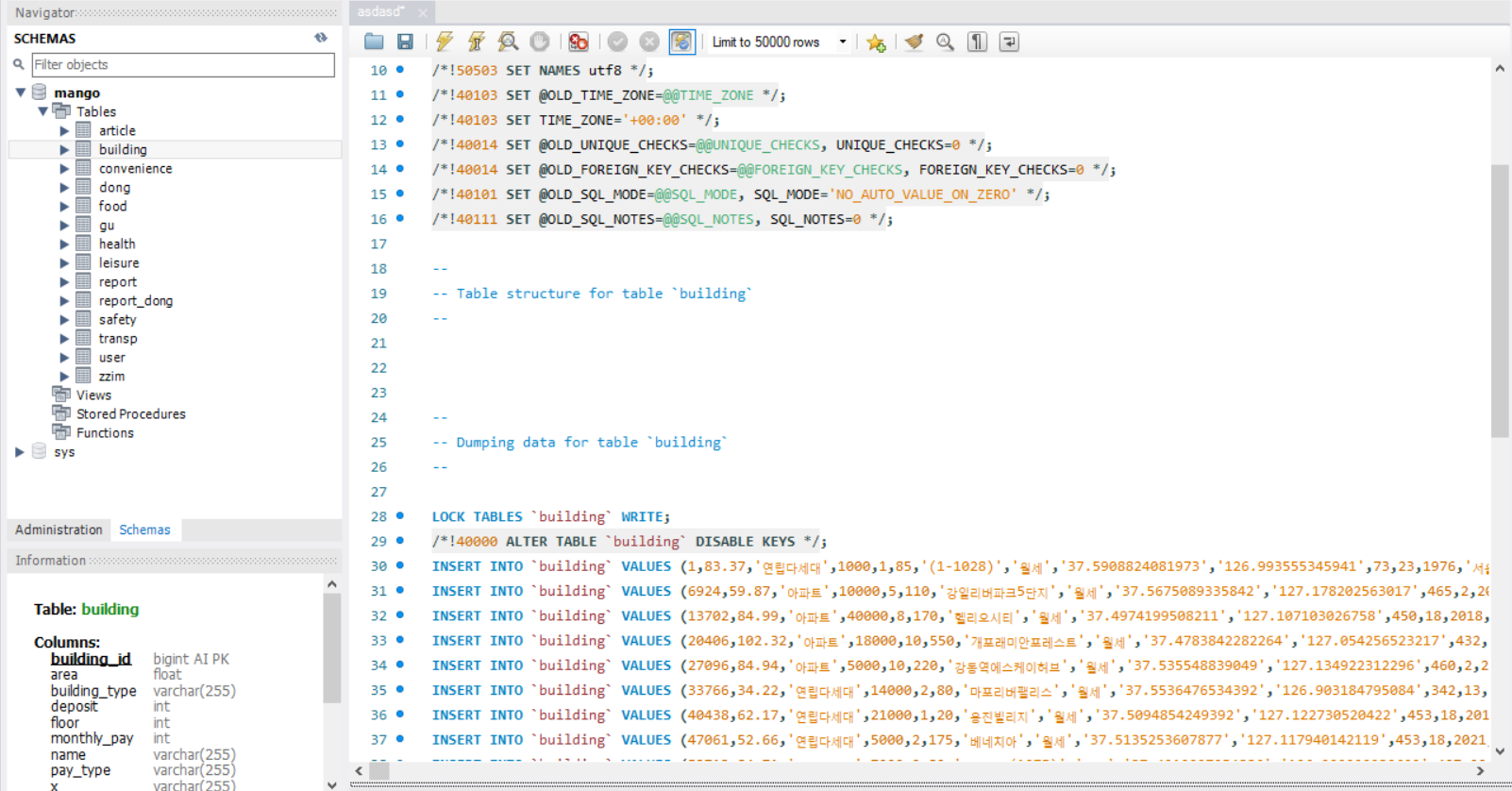
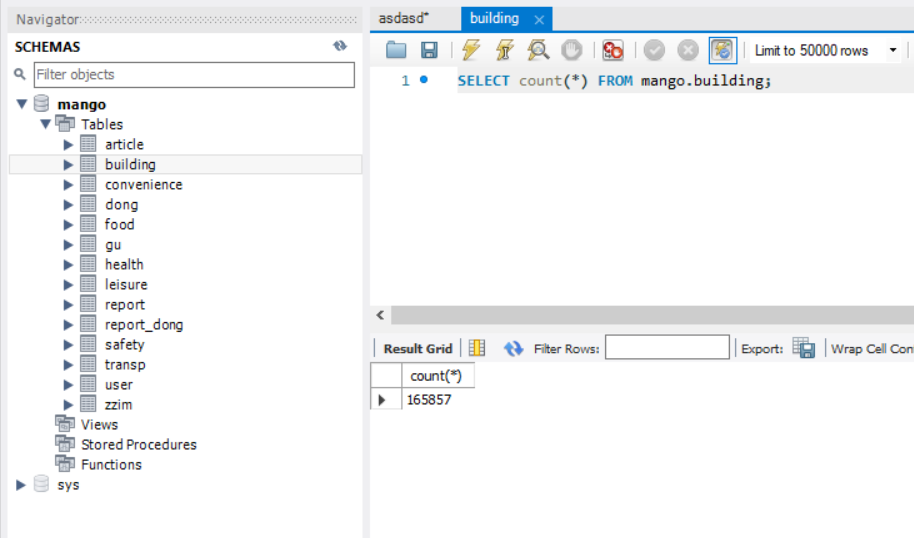
매물 데이터가 RDS에 잘 반영되었다!
