Unity - Render Pipeline
Unity마스터

깃허브 블로그에서 이사시킨 포스트
참고
렌더 파이프라인의 설명에 앞서, 왜 컴퓨터 그래픽을 계산하는 데에 있어 GPU가 사용되는 것인지 짚어 넘어가야한다.
게임에서 표현되는 3D 화면은 어떤 식으로 구현되는지 알아본다. 게임 화면을 구현하는 데에는 CPU 보다 GPU가 더 많이 관여한다. 왜 그럴까?
GPU와 CPU
CPU = 컴퓨터의 핵심 부품. 뇌에 해당한다. 복잡한 직렬 처리용으로 쓰임
GPU = 기존에는 없었던 부품. 컴퓨터 그래픽을 표현하기 위해 사용된다. 단순한 병렬 처리용으로 쓰인다
> CPU는 프로세서가 몇개 없다. 하지만 GPU는 성능이 안좋은 프로세서가 수 천개 있다
왜 CPU가 아니라 GPU를 씀?
그래픽 처리 과정은 단순한 문제를 엄청 많~이 풀어내는 과정이다CPU= 대학교수
GPU= 사칙연산 배운 초등학생
대학교수에게 산술문제 1000개 시키는 것보다 초등학생 1000명에게 각각 한 문제 시키는게 훨씬 빠름(효율문제)
GPU (Graphic Processing Unit)
GPU가 동작하는 방식
GPU는 순차적인 계산에 유리 하지 않다. 병렬계산에 유리함
3D 사물의 정보 구성
Polygon mesh<-triangle<-vertex( normal, color ...etc)
Vertex Data: 많은 정보가 저장되는 정점이다 (Normal- 정점이 어느방향을 보는지 표현하는 데이터, 법선)
정점 데이터(vertex data)-> 삼각형 -> 쭉 연결되어 폴리곤 메쉬가되고, 폴리곤 메쉬에 쉐이더 작업을 통해 우리가 보는 3d 사물이 된다.
정점의 수많은 데이터들에 대한 계산, 실시간 변화해가는 화면 상의 데이터들을 행렬 계산해가는게 GPU의 역할.
SIMD(Single Instruction Multiple Data)
이러한 하나하나의 계산을 Thread(쓰레드) 라고 하고 한 개의 조각당 하나의 코어를 통해 계산되고, 여러개의 코어가 있으면 여러개의 조각을 한번에 처리 함 --> 하나의 명령어로 여러개의 조각을 계산
용도에 따라 SIMD로 하기에는 쓰레드가 너무 많아졌다. 효율을 위해 개선한게
SIMT(Single Instruction Multiple Threading)
CUDA / OpenCL 등등이 있다.
군대로 치면 명령(쓰레드)을 병사 한 명 한 명(코어) 에게 하달하던게(=SIMD), 하나의 분대의 병사 수에 맞게 명령을 분대 단위(하나의 쓰레드 그룹,이를 Warp라고 한다)로 내려주고, 그 분대 안에서 다시 명령을 나눠서 SIMD처럼 되게 한 것
Latency 문제 해결
명령 받은거 처리하고 다음 명령 기다리다가 붕 뜨는 시간(지연시간-Latency=메모리 불러오는 시간) 생긴다
그러지 않고 다른 워프를 물고와서 또 계산 시작(Latency 감소)
cpu는 이걸 지 근처에 캐쉬메모리를 둬서 해결함(cp병)
렌더 파이프라인
Randering Pipeline(Graphics Pipeline). 업계에서는 5 단계를 보통 표준으로 한다
컴퓨터에서 GPU를 사용해 어떻게 그래픽을 구현하는 지 나타내는 과정을 렌더 파이프라인이라고 한다.
렌더 파이프라인의 5단계
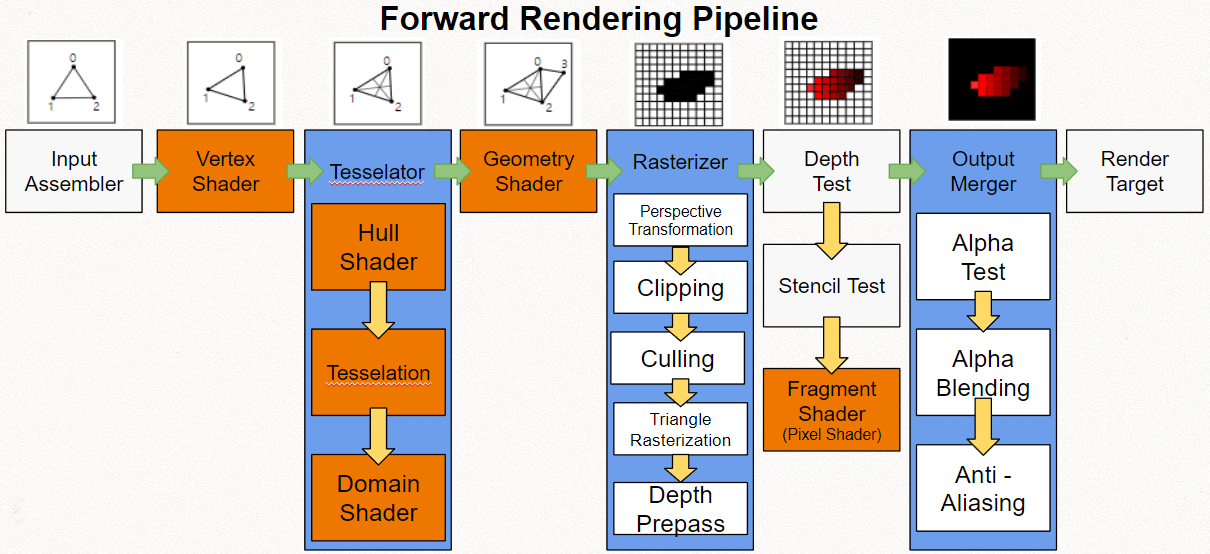
- 입력조립
- 정점셰이더
- 레스터라이저
- 픽셀셰이더
- 출력병합
API
업계에서 자주 쓰이는 렌더 파이프라인은 DirectX, OpenGL, Vulcan 이 있다
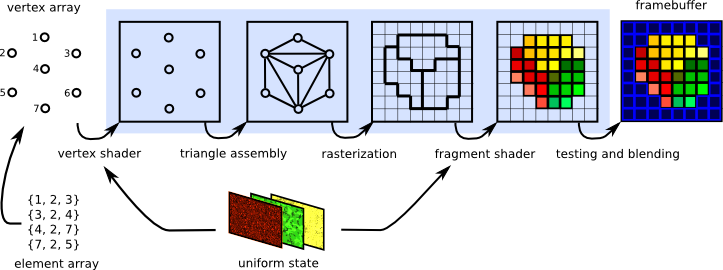
1. 입력조립(input assambly)
-
데이터화 된 배열을 계산하는 단계다.
-
그래픽스 API 초기화
병목현상을 방지한다. CPU가 "야 gpu 일감왔다" 하는 과정이다. 정점들의 정보들을 Vertex buffer로 저장하여 처리한다
진행 단계 : CPU -> 드로우콜 -> 커맨드큐(드로우콜 저장) -> GPU가 꺼내서 처리
드로우콜**(Draw call)
CPU가 프레임마다 "야 우리 지금 이걸 화면에 표시해야됨. 빨랑 그려라" GPU에게 명령으로 호출한다
- 드로우 콜에 들어가는 정보들 =
Mesh,Texture,Shader,Trasform,Alpha blending, etc.
원리 설명
드로우콜의 정보(Storage Data -> CPU Memory:L1~L3 cache,RAM)를 커맨드 큐(GPU Memory:vram)에 저장한다.
렌더링을 위해서는 텍스처, 정점, 쉐이더 등의 정보들을 뭘쓸지 순차적으로 GPU에게 알려줘야 한다.
이런 정보들을 담은 테이블 = **Render States(렌더 상태)** 라고 하고 각각의 테이블 정보들은 포인터로 GPU 메모리의 위치를 저장한다.
이후 cpu가 render states 를 변경하라는 명령을 gpu에게 보내고 나서, gpu에게 메쉬를 그리라는 명령을 보낸다.
이걸 **DP Call**(Draw Primitive Call) 이라고 한다.
GPU는 DP Call을 받으면 Render States의 정보들을 바탕으로 메쉬를 렌더링한다.
한 프레임에서 옵젝 하나 완성
CPU가 "GPU야 Render States 변경해" 라고 하면서 또 메쉬의 정보들을 넘겨준다.
그러고 나서 DP Call을 주면 GPU는 또 그린다. 이런식으로 한프레임 한프레임의 메쉬가 그려진다.
이렇게 하나의 옵젝을 그릴때마다 바뀌는 위의 과정들을 뭉뚱그려 Draw Call이라고 한다.
커맨드 큐에 드로우콜들을 저장 함으로써 CPU와 GPU는 비동기로 작업이 가능하다!
드로우 콜 -> 커맨드큐 의 중간 과정에 커맨드 버퍼가 존재하는데, 이는 API마다 방식이 다르다
근데, 드로우 콜이 많아도 너무 많아서 CPU 병목현상이 생긴다.
이를 위해서 드로우콜 호출 횟수 줄여야된다.
옵젝 수를 줄이는게 도움이 된다.
유니티의 경우
Batch- 넓은 의미의 드로우콜Set pass- 쉐이더로 인한 렌더링 패스 횟수.
10개의 옵젝, 한 개의 머테리얼 -> Set Pass =1
10개의 옵젝, 10개의 머테리얼 = 10 Set Pass
Set pass가 CPU 성능 잡아먹는다.
2. 정점 셰이더(vertex shader)
- 삼각형을 그리기 위한 꼭짓점(Vertex)들 처리
Vertex Data들을 통해 조립된 옵젝을 공간변환 수행, 정점들의 위치를 클립 공간으로 옮김
공간변환 - 모델,뷰,투영 변환 (행렬연산)
-
모델 변환(Model Transform)
먼저 모든 옵젝은 자기만의LOCAL SPACE에서 정점이 표현된다. 원점은 피벗.
렌더링 하고자 하는 옵젝을 모델 행렬에 계산하여WOLRD SPACE에 옮긴다.
표현하고자 하는 장면의 공간에 옵젝을 불러오는 과정.
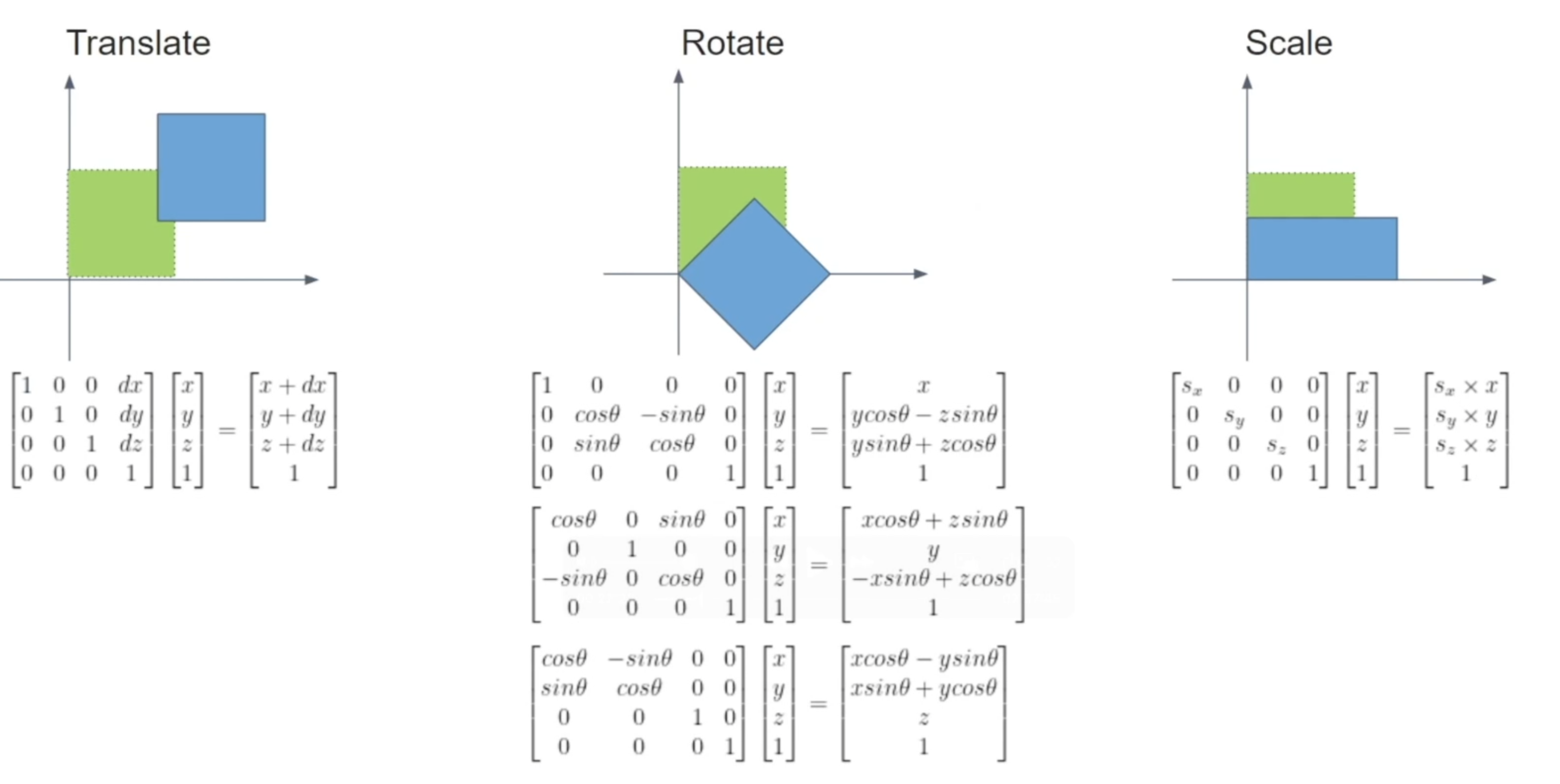
이 과정에서 이동, 회전, 크기 변환이 이루어진다 -
뷰 변환(View Transform)
카메라를 기준으로 옵젝의 정점들을 변환한다.
카메라 공간인뷰 공간(View SPACE)으로 변환. -
투영 변환(Projection Transform)
모니터 화면에 그려내기 위한 정점 위치인투영 공간에 변환.
직교 투영(원근감 없음)원근 투영(원근감 있음)
이 모든 과정은 변환에 해당하는 행렬들과 오브젝트의 정점들의 행렬을 계산해서 처리한다.
연산단계를 줄이려면, 변환 행렬끼리 결합법칙(Matrix Combining)을 이용해 축소하면 된다. 유니티에서는 Transform 컴포넌트가 해당 정보들을 계산하는 역할을 담당한다
3.레스터라이저 (Rasterizer)
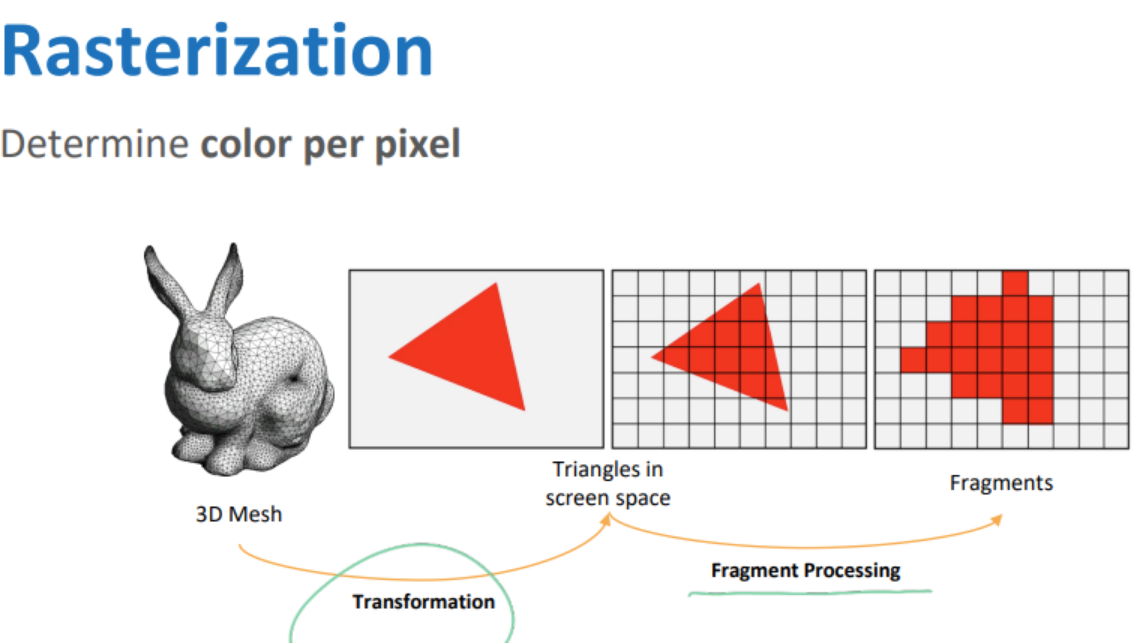
화면 출력 해상도의 특정 픽셀에 출력을 고정시키는 역할을 하는 단계다.
화면으로 옵젝을 옮겼으니, 이걸 이제 픽셀화를 함.
하나하나의 픽셀은 fragment(조각). 프로그래밍이 불가능한 단계
보간(Interpolation)도 이 단계에서 진행됨.
FXAA, SMAA 등등의 anti aliasing과 Anisotropic filtering (비등방성 필터링)도 있음.
클립 공간
- 카메라의 시점이 있는 공간 (시야에 의한 제한과 원근법에 의한 차이 존재)
카메라 시점(View port)으로 보이는 오브젝트(클립 공간)를 직육면체(NDC-정규화)로 압축한다.
~1<X and Y<1, 0<Z<1
클리핑 Cliping
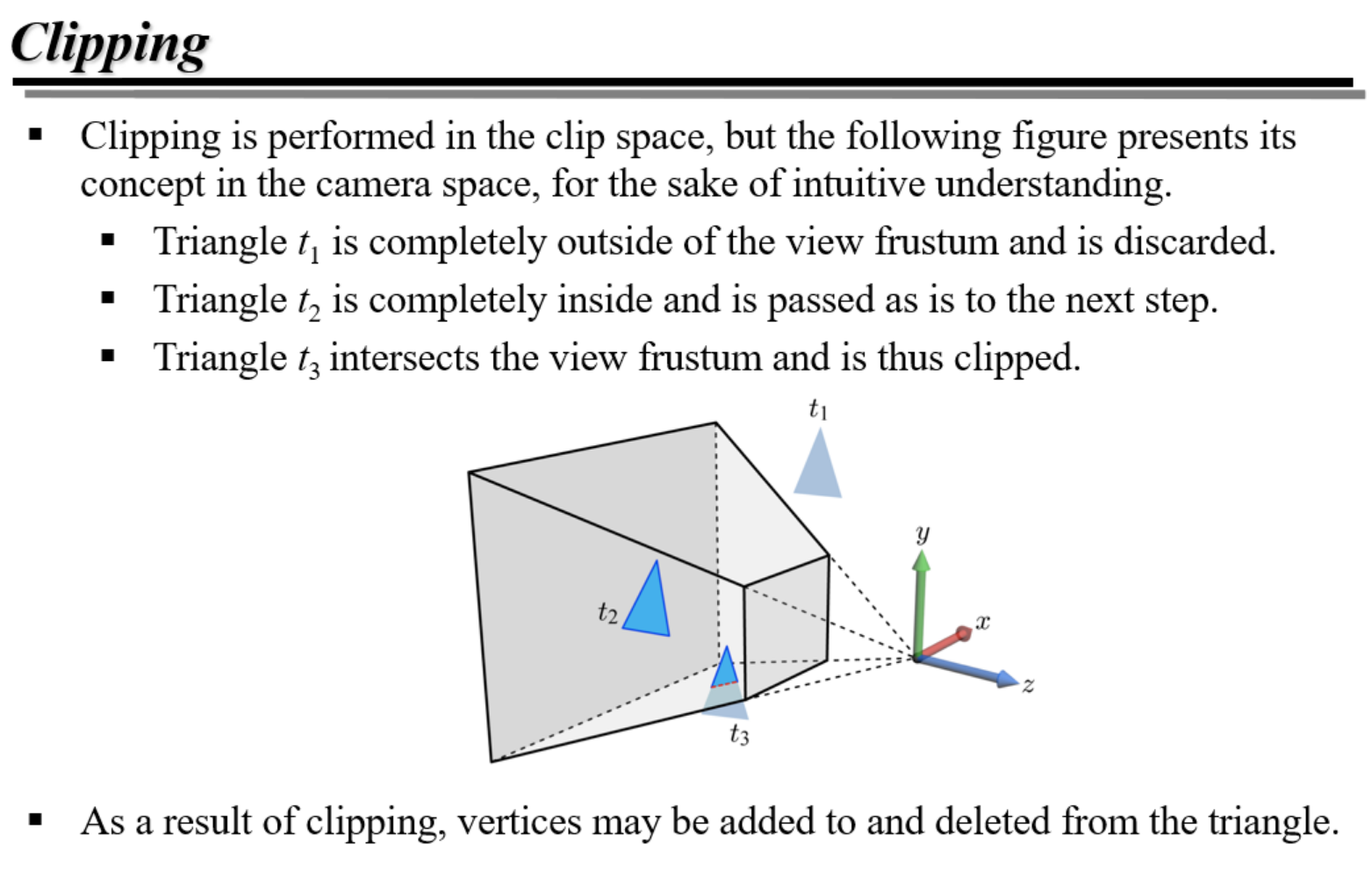
- 압축하는 과정에서 공간을 벗어나는 부분은 잘라낸다.
- 화면에서 가까운 면은
near clip, - 먼 면은
far clip. - 두 면을 포함한 육면체를
절두체(frustrum)이라고 함.
후면 컬링 (Culling)
렌더링 안해도 되는 정보들을 솎아내는 작업
- BackFace Culling(후면 선별) - 뒷면
triangle의 법선(normal)과 카메라 방향의 벡터 내적을 통해 구한다 < 0(코사인 값이 90도를 넘어간다) - Frustrum Culling(시각절두체 선별) - 딱 시야에 안보이는 것들
triangle의 법선(normal)과 카메라 방향의 벡터 내적을 통해 구한다 = 0 (90도 수직이라 코사인이 값이 0) - Occlusion Culling(차폐 선별) - 앞에 무언가 가린경우.
depth buffer (Z buffer)를 통해 알 수 있다
뷰포트 변환
3차원 이였던 좌표를 2차원 화면의 좌표로 바꾸는 변환
x,y좌표를 모니터 화면(해상도)에 맞게 좌표를 바꿈. 창모드, 전체화면과 같이 해상도가 달라질 일이 있는데, 그런 해상도에 맞추는 작업이다
스캔 변환
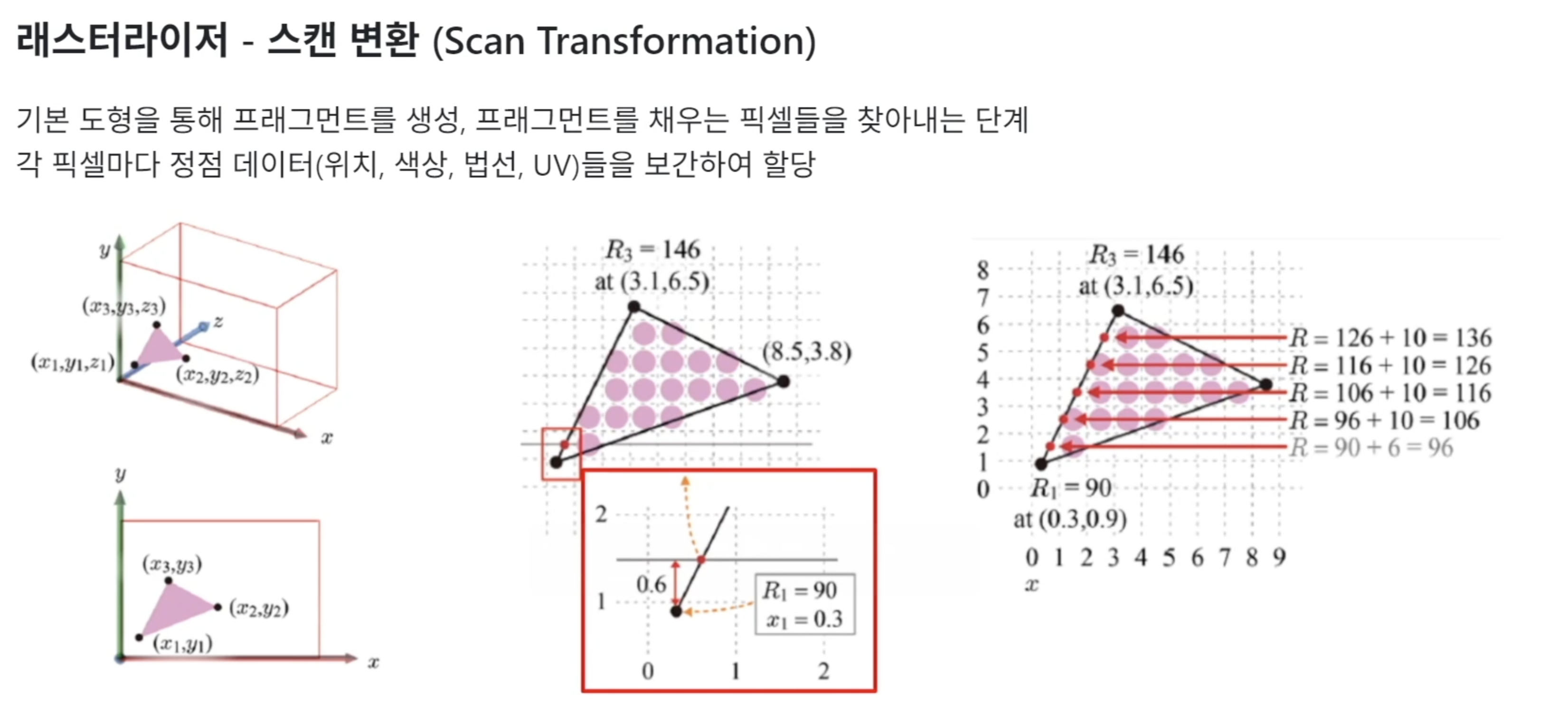
fragment 생성 후 fragment에 해당하는 픽셀들을 찾아
정점 데이터를 보간하여 할당하는 단계(안티엘리어싱,비등방성필터링 등의 알고리즘 기법들도 이곳에서 적용된다)
안티 앨리어싱
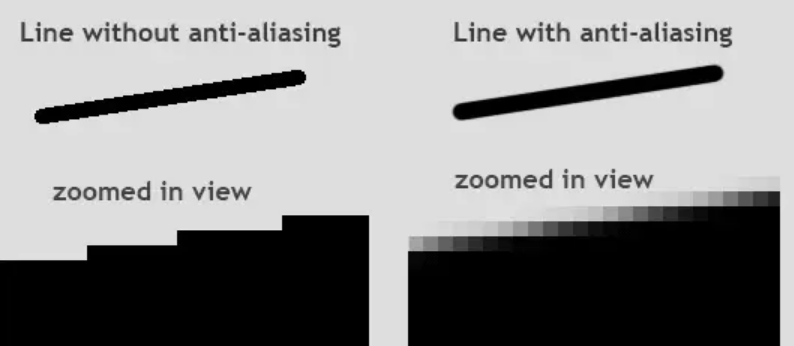
비등방성 필터링

4. 픽셀 셰이더
픽셀에 Opacity, Lighting, Shadow, Coloring 하는 단계
픽셀 셰이더
픽셀마다 픽셀 셰이더를 한 번씩 호출함. 깊이, 색상 값 을 계산하여 전달.
텍스쳐
질감을 표현하는 이미지
픽셀에 색상을 추가함.
노말맵
표면의 법선을 표현하는 방법
그림자를 입히기 위해 씀.
높이맵(Height Map)

효과는 좋으나, 연산이 많이 필요하기 때문에 요즘에는 잘 안쓴다고 함
라이트
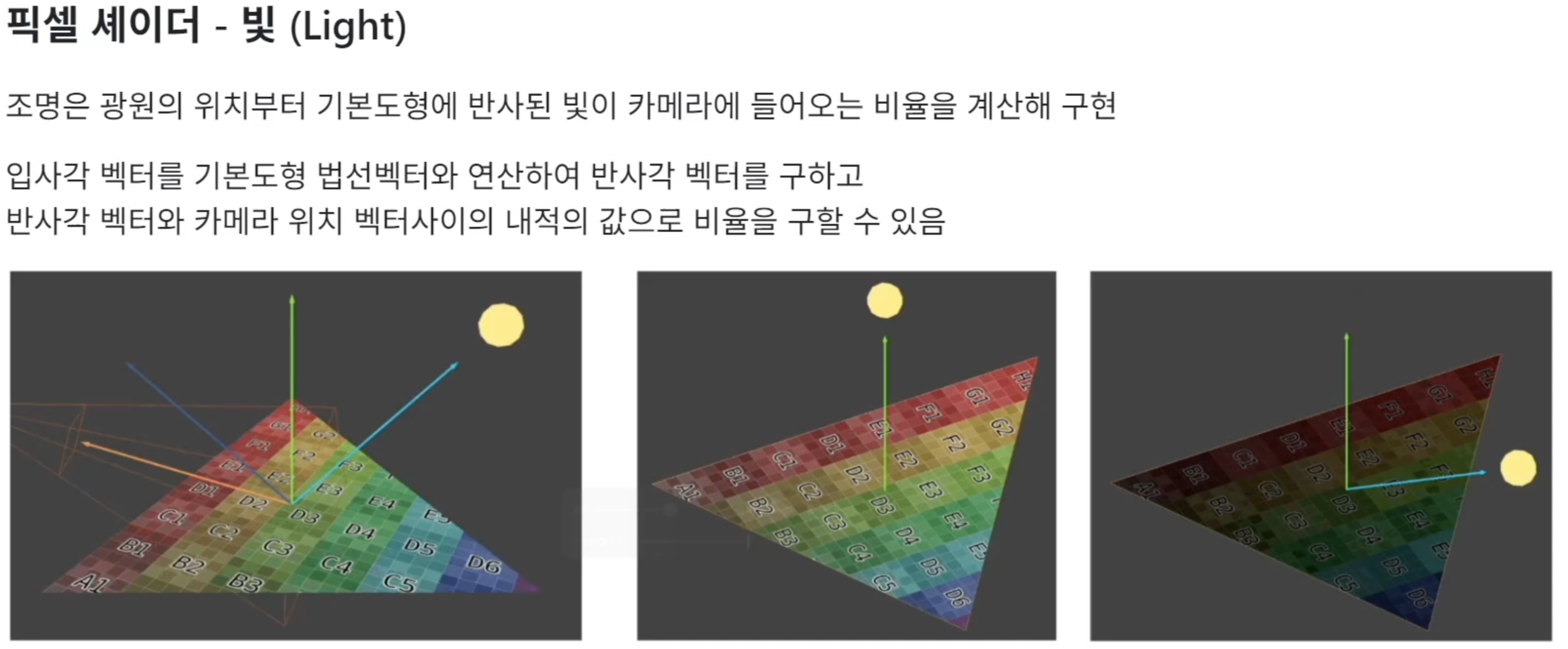
광원이 표면에 반사되어 카메라에 빛이 들어오는 것을 계산하여 표현
입사각 벡터(광원 -> 표면) X 표면의 법선 벡터(외적) = 반사각 벡터
반사각 벡터 와 카메라 위치 벡터의 내적을 통해 구함(스칼라)
가급적이면 직접적인 빛 연산을 피해야 한다. 연산량이 매우 크다. 보통은 빛을 구워서(Bake) 사용한다
5. 출력 병합
겹쳐있는 픽셀이 있나 확인. 연산한 다음 최종적인 픽셀의 색을 혼합하여 결정.
깊이 버퍼
픽셀에서 앞뒤에 뭐가 있나 확인하기 위한것. 겹치면 가리거나 투명도 조절할 수 있도록 함.
알파 블렌딩
투명도를 표현하기 위한 방법. 오브젝트가 서로 겹치면 색상을 혼합함.
스텐실 테스트
최종적으로 만들어진 픽셀을 화면에 표시를 할 지 말지 결정하기 위해 사용됨. 여기에 마테리얼을 새로 입혀서 다른식으로 표현할 수도 있다. 예를들어, 벽 뒤에 있는 적을 표시할 때 쓸 수 있다
