
본 글의 내용은 Operating Systems: Three Easy Pieces의 Concurrency: Introduction 챕터를 정리한 것입니다.
☑️ 개요
-
스레드는 단일 실행 프로세스에 대한 새로운 추상화라고 할 수 있다. 단일 실행 지점이라는 기존의 관점 대신에, 둘 이상의 실행 지점(명령어를 가져와 실행하는 여러 대의 PC)이 존재하는 것이다.
-
스레드는 동일한 주소 공간을 공유할 수 있으며, 동일한 데이터에 액세스 가능하다. 사실 이 특징을 제외하면 프로세스와 매우 유사하다.
-
각 스레드마다 개인 레지스터 세트가 존재하므로,
다른 스레드로 실행이 전환될 때는 Context Switching이 이루어져야 한다. -
이때, 레지스터 상태를 저장하고 복원한다는 점에서 프로세스와 매우 흡사하다.
-
스레드는 스레드의 상태를 저장하기 위해 TCB(Thread Control Block)가 필요하며,
프로세스와의 가장 큰 차이점은 Context Switching 시 주소 공간이 유지된다는 것이다. (즉, 페이지 테이블을 교체할 필요가 없다)
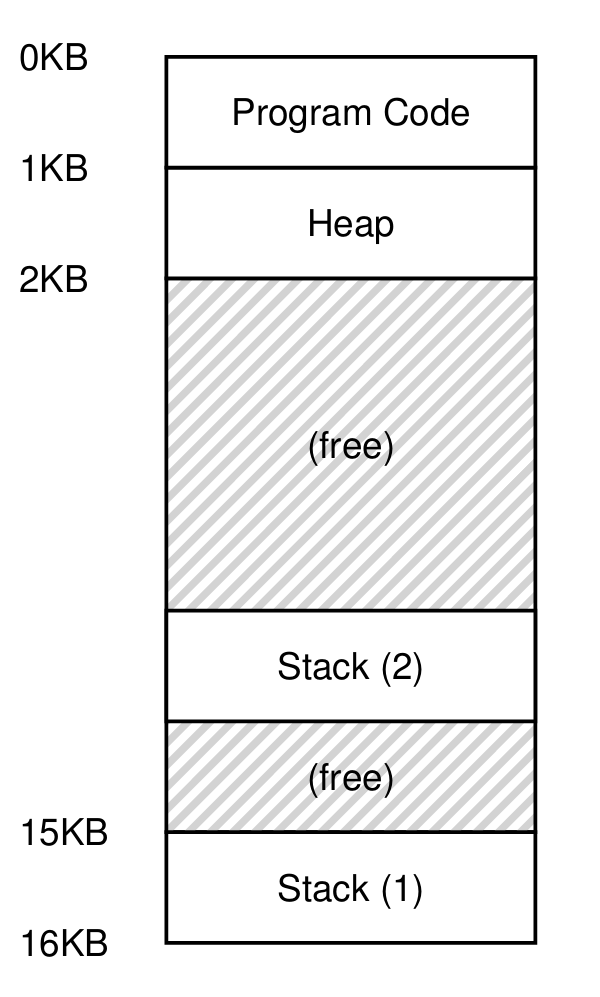
(여러 개의 스택이 존재하는 멀티스레드 환경)
☑️ 왜 스레드를 사용하나요?
-
병렬 처리 (Parallelism)
-
단일 스레드 프로그램을 여러 CPU에서 작업을 나눠 실행하는 것을 병렬화라고 한다.
-
최신 하드웨어에서 프로그램을 더 빠르게 실행할 수 있는 일반적인 방법이다.
-
-
I/O로 발생하는 Blocking 회피
-
I/O 요청이 발생했을 때 그저 기다리기 보다 추가 I/O 요청을 발행하거나 다른 작업을 수행하기를 원할 수도 있다.
-
I/O 요청을 한 스레드가 기다리는 동안 CPU 스케줄러가 다른 스레드로 switching 하는 것이 효율적이다.
-
-
즉, 스레딩은 여러 프로세스가 했던 역할과 유사하게 단일 프로그램 내에서 다른 작업과 입출력을 겹쳐서 수행할 수 있게 해준다. 그 덕에 많은 서버 기반 앱이 스레드를 활용한다.
-
결론적으로 위에서 언급된 두 특징은 멀티 프로세스에도 적용되는 얘기지만,
스레드는 주소 공간을 공유하기 때문에 데이터를 쉽게 공유한다는 차별성을 가진다.
☑️ 예시: 스레드 생성
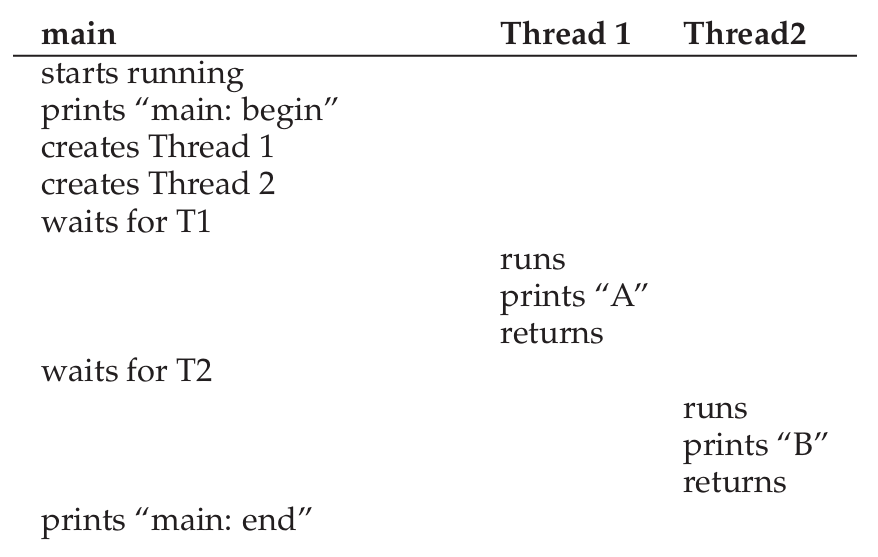
-
위 예시에서는 두 스레드가 생성되고, print 함수를 호출한 뒤 종료된다.
-
이때 두 스레드 중 어떤 것이 먼저 실행될 지는 스케줄러가 정한다.
-
그렇기에 스레드의 동시성을 활용할 때 생기는 문제는 스케줄러에 있다.
-
스레드가 먼저 생성된다고 항상 먼저 실행되는 것은 절대 아니기 때문이다.
먼저 실행될지 아닐지는 스케줄러가 결정한다.
☑️ 복잡도 증가: 공유 데이터

-
위 코드를 두 스레드가 실행하면, 우리는
counter변수가 2천만이 되기를 예상할 것이다. -
하지만 실제로 실행해보면 2천만에 못 미치는 결과를 얻게 된다. 왜 그럴까?
☑️ 통제 불가능한 스케줄링

(변수에 1을 더하는 어셈블리 코드)
-
위 상황을 이해하려면 컴파일러의 코드 시퀀스를 이해해야 한다.
-
위 어셈블리 예제에서,
counter변수가0x8049A1C라고 하자.
그럼 해당 값은eax레지스터에 저장되고,ADD명령어를 통해 1이 더해진다.
이후 결과값이 다시0x8049A1C주소에 저장된다. -
이 과정이 두 스레드에서 실행된다고 할 때,
스레드 A가ADD명령어까지 실행하고 switching 된다고 가정해보자. (timer interrupt 발생) -
그럼 스레드 B는 이전 값을
eax레지스터에 다시 복원시키게 되고, 앞서 더해진 값이 무의미해지게 된다. -
여기서 설명한 것을 Race condition
(보다 구체적으로 표현하면 data race)라고 하는데,
코드의 실행 타이밍에 따라 결과가 달라지는 것이다.
이러한 예측 불가한 가능성을 indeterminate라고 한다. -
또한 이 race condition이 발생할 수 있는 영역을 critical section이라고 한다.
critical section은 공유 변수에 액세스하는 코드 영역으로,
두 개 이상의 스레드에서 동시 접근되서는 안 된다. -
결국 이 상황에서 우리가 원하는 것은 mutual exclusion(상호 배제)인 것이며,
이 속성을 지키는 것이 critical section에서 하나의 스레드만 실행되도록 보장한다.
💡 Atomic Operation
atomic operation은 컴퓨터 구조부터 동시성 코드, 파일 시스템, DB 관리 시스템, 분산 시스템에 이르기까지 가장 강력한 기본 기술 중 하나다.
작업을 원자 단위로 만든다는 아이디어는 “All or Nothing”이라는 말로 표현할 수 있다. 중간 상태가 표시되지 않고 모두 작업되거나, 아무 작업도 되지 않아야 한다.
때때로 많은 작업을 원자 작업으로 그룹화하려는 것을 트랜잭션이라고 한다. (DB에서 매우 중요한 개념)
동시성이라는 주제에서는 짧은 명령어 처리를 atomic한 실행 블록으로 변환하는 것에 그치지만, 결국 atomic하다는 것은 단순히 그런 것보다 큰 개념이라는 것을 유념해둘 필요가 있다.
☑️ 원자성
-
이런 동시성에 의한 충돌을 해결하는 한 가지 방법은 필요한 작업을 정확하게 수행하고, 뜬금없이 일어나는 중단을 배제하는 슈퍼 명령어를 사용하는 것이다.
-
만약 위 예제(어셈블리 명령어 3개 실행)의 명령어들이 atomic하게 하나의 단위로 실행된다고 가정해보자. 이것을 하드웨어가 지원하는 것이 정상적일까? 그렇지 않다.
-
대신 하드웨어는 synchronization primitives라는 몇몇 유용한 명령어를 제공한다.
☑️ 또 다른 문제: 대기
-
멀티 스레드에서 또 발생할 수 있는 문제는 특정 스레드가 계속 진행하기 위해서 다른 스레드의 작업이 완료될 때까지 기다려야 한다는 것이다.
-
예시로 프로세스가 디스크 입출력을 수행하며
sleep상태에 들어가면, 입출력이 완료 됐을 때 해당 프로세스를 깨워야만 계속 진행할 수 있다. -
그러므로 synchronization primitives로 동기화 문제를 해결하는 것 뿐만 아니라 잠자기/깨우기 작업을 지원하는 메커니즘도 필요하다. 이것을 위해 condition variable이 존재한다.
💡 주요 동시성 용어
Critical Section: 공유 리소스에 접근하는 코드 영역
Race condition: 여러 스레드가 동시에 Critical section에 진입한 상황. 동시에 공유 리소스를 업데이트하려는 시도가 괴상한 결과를 낸다.
Indeterminate: Race condition에 의해 발생하는 것으로, 상황에 따라 프로그램의 결과가 달라진다. 일반적인 컴퓨터 시스템은 결정론적(deterministic)이지 않다.
Mutual exclusion: 위 문제들을 방지하기 위해 mutual exclusion primitives를 사용해야 하며, critical section에 단일 스레드가 진입하는 것을 보장한다.
✅ 요약
-
스레드는 둘 이상의 실행 지점을 만들어주는 개념이다. 병렬 처리 및 IO blocking 회피가 가능해지기 때문에 고성능을 낼 수 있다.
-
프로세스와 굉장히 유사하며, context switching에도 주소 공간이 유지된다는 차이가 있다.
-
스레드는 주소 공간을 공유하며, timer interrupt에 의해 예측 불가능(indetermintate)하기 때문에 동시성 문제가 발생한다.
-
이 동시성 문제가 발생하는 구역을 Critical section이라고 하며, 문제를 해결하기 위해 mutual exclusion이 요구된다.
-
Mutual exclusion을 달성하기 위해 synchronization primitives 및 condition variable을 활용한다.
