※ sprint의 application.properties에 database 연결(localhost:3306/database이름?~ 이 된다)
spring.datasource.url=jdbc:mysql://localhost:3306/task_agile?useSSL=false&autoReconnection=true
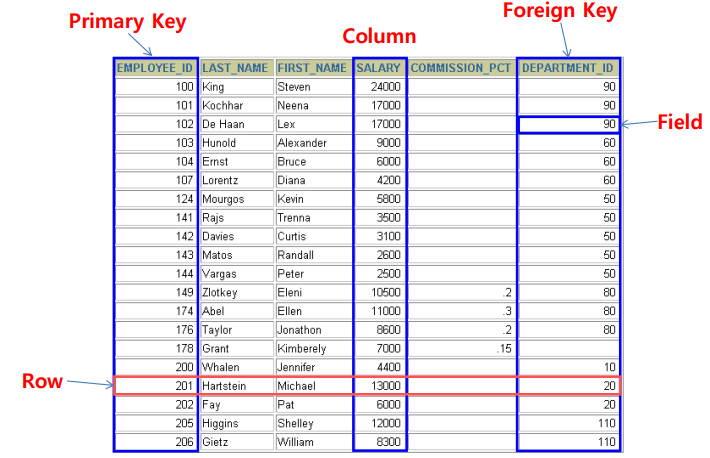
RDB 용어
- Row(행, tuple) : 2차원 구조를 가진 테이블에서 가로 방향으로 이루어진 연결된 데이터
- Column(열, attribute) : 2차원 구조를 가진 테이블에서 세로 방향으로 이루어진 하나하나의
특정 속성 - Field : 칼럼과 행이 겹치는 하나의 공간
- Primary Key(PK) : 유일하게 테이블의 각행을 식별(NOT NULL과 UNIQUE조건을 만족)
- Foreign Key(FK) : 열과 참조된 열 사이의 외래키 관계를 적용하고 설정
Oracle DB 객체(Objects)
Database
DB 목록 보기/현재 사용하는 DB 보기
show databases;
select database();
현재 DB의 table 목록 보기
show tables;
DB 생성/삭제/사용
-
생성
create database DB이름; -
삭제
drop database DB이름; -
사용
use DB이름;
Table 정의하기(DDL)
DDL(Data Definition Language, 데이터 정의어) : RDB의 구조를 정의
데이터와 데이터간의 관계 정의를 위한 언어로, 데이터베이스 내에서 테이블과 같은 데이터 구조 또는 객체(object)를 생성, 변경, 삭제하는데 사용됨
| 명령어 | 설명 |
|---|---|
| CREATE TABLE | 테이블 생성 |
| ALTER TABLE | 테이블 구조변경 |
| DROP TABLE | 행과 테이블 구조를 삭제 |
| RENAME | Table, view, sequence, synonym의 이름 변경 |
| TRUNCATE | Table의 모든 행을 삭제하고 table의 저장공간을 해제 |
Table 생성(CREATE) 및 변경(ALTER)
- CREATE : DB 객체 생성 및 테이블, 뷰, 인덱스를 정의하거나 스키마, 함수 등을 정의
- 테이블 생성시 테이블 생성과 함께 제약조건 정의 가능
- ALTER : 기존에 존재하는 DB 객체를 변경, 테이블 컬럼 추가, 이름 변경 등 테이블의 구조를 변경
CREATE TABLE 테이블명 (열 정의1, 열 정의2, ...);
ALTER TABLE 테이블명 하부명령- 예시
CREATE TABLE table이름 (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
...
PRIMARY KEY(id);
)
create table user (
id INT(11),
username VARCHAR(64) not null,
email_address VARCHAR(128) not null,
password VARCHAR(32) not null,
first_name VARCHAR(64) not null,
last_name VARCHAR(64) not null,
created_date DATETIME not null,
PRIMARY KEY(id)
);
// 자동 속성 값 초기화
ALTER TABLE user AUTO_INCREMENT=1;
// 기존 컬럼에 자동증가 속성 추가
ALTER TABLE user MODIFY id INT NOT NULL AUTO_INCREMENT;
// 자동 속성 및 pk 값을 갖는 신규 컬럼 추가
ALTER TABLE user ADD COLUMN column_name INT(9) NOT NULL AUTO_INCREMENT PRIMARy KEY FIRST; // 쿼리 성공 표시 Query OK, 0 rows affected (0.13 sec) Records: 0 Duplicates: 0 Warnings: 0
create table team(
id int(11) not null,
user_id int(11),
archived tinyint(1),
created_date datetime,
primary key(id)
);
alter table team add index fk_user_id_idx (user_id);
create table board(
id int(11) not null,
name varchar(128),
user_id int(11),
team_id int(11),
archived tinyint(1),
created_date datetime,
primary key(id),
foreign key(user_id) references user (id),
foreign key(team_id) references team (id)
);
create table card_list (
id int(11),
board_id int(11),
user_id int(11),
name varchar(255),
position int(11),
archived tinyint(1),
created_date datetime,
primary key(id),
foreign key(user_id) references user (id),
foreign key(board_id) references board (id)
);
create table card (
id int(11) not null,
user_id int(11),
card_id int(11),
file_name varchar(255),
file_path varchar(255),
file_type int(11),
archivee tinyint(1),
created_date datetime,
primary key(id),
foreign key(user_id) references user (id),
foreign key(card_id) references card (id)
);
create table board_member(
board_id int(11),
user_id int(11)
);
alter table board_member add foreign key(board_id) references board (id);
alter table board_member add foreign key(user_id) references user (id);
board_member foreign key 지정하기
create table attachment (
id int(11) not null,
user_id int(11),
card_id int(11),
file_name varchar(255),
file_path varchar(255),
file_type int(11),
archivee tinyint(1),
created_date datetime,
primary key(id),
foreign key(user_id) references user (id),
foreign key(card_id) references card (id)
);
create table activity (
id int(11) not null,
user_id int(11),
card_id int(11),
board_id int(11),
type tinyint(1),
detail json,
created_date datetime,
primary key(id),
foreign key(user_id) references user (id),
foreign key(card_id) references card (id),
foreign key(board_id) references board (id)
);
create table assignment (
card_id int(11),
user_id int(11),
foreign key(user_id) references user (id),
foreign key(card_id) references card (id)
);- 위 명령어 결과

Table 삭제(DROP/TRUNCATE),
DROP TABLE table이름;
TRUNCATE [TABLE] table이름;
- DROP : 테이블 구조 자체가 삭제
- 테이블에 관련된 index, 제약조건, trigger, 권한도 모두 삭제
- ROLLBACK 불가
- 테이블 자체가 없어지기 때문에 테이블 구조 확인 불가 및 복구 불가능
- TRUNCATE : 테이블의 공간 해제 방식으로 구조는 남기고 table의 모든 row를 삭제하는 방식.
- 테이블과 관련된 구조, 종속 객체, 권한에 영향을 주지 않음
- ROLLBACK 불가
- 빠르고 효율적이다.
- Redo log에 이전 데이터에 대한 정보를 남기지 않기 때문에 한번 삭제된 데이터는 복구가 불가능
- DELETE(DML) : TRUNCATE와 같이 모든 row를 삭제하지만, 행 단위(row by row)로 수행되기 때문에 이전 할당된 영역이 빈 공간으로 남아있게 된다.
- ROLLBACK 가능
- Trigger가 걸려있다면 각 행이 삭제될 때 실행된다.
- 행이 많을 경우 많은 시스템 자원을 소모할 수 있다.
Table 이름 재지정(RENAME)
ALTER TABLE old_table_name RENAME new_table_name;
RENAME TABLE old_table_name TO new_table_name;
RENAME TABLE products TO products_old,
products_new TO products;테이블 내의 데이터 조작하기(DML)
DML(데이터 조작어, Data Manipulation Language) : 데이터베이스 사용자 또는 응용 프로그램의 데이터 검색, 등록, 삭제, 갱신 등의 처리를 위한 언어
| 명령어 | 설명 |
|---|---|
| CREATE TABLE | 테이블 생성 |
| ALTER TABLE | 테이블 구조변경 |
| DROP TABLE | 행과 테이블 구조를 삭제 |
| RENAME | Table, view, sequence, synonym의 이름 변경 |
| TRUNCATE | Table의 모든 행을 삭제하고 table의 저장공간을 해제 |
Table에 데이터 넣기(insert)
insert into table이름(name, age) values ('hong', 11);
insert into table이름(name, age) values ('hong', 11), values('kim, 12), values ('park', 13);
' 넣고 싶다면 \' 사용
Table에 데이터 넣기(UPDATE)
Table 데이터 삭제(DELETE)
Table 내의 데이터 조회(SELECT)
SELECT 문법 작성 순서 및 실행 작동 순서
문법 작성 순서 실행 작동 순서
select 컬럼명 ⑧
from table이름 ①
WHERE 조건식 ④
GROUP BY 컬럼명 ⑤
HAVING 조건식 ⑦
ORDER BY 컬럼명 ⑩
② : ON, ③ : JOIN,
⑥ : CUBE | ROLLUP,
⑨ : DISTINCT, ⑪ : TOP| 문법 작성 순서 | 실행 작동 순서 | 실행 작동 순서 설명 | |
|---|---|---|---|
| ① | SELECT | FROM | 조회할 table에 접근 |
| ② | FROM | (ON➡JOIN➡) WHERE | 필요한 record 추출 |
| ③ | WHERE | GROUP BY | 컬럼에 따라 그룹화(주로 통계를 낼 때 사용) |
| ④ | GROUP BY | (CUBE/ROLLUP➡) HAVING | (집계함수➡) 그룹화 한 컬럼에 조건문으로 filter |
| ⑤ | HAVING | SELECT (➡DISTINCT) | 여기서부터는 선택된 data를 가공(➡중복 제거) |
| ⑥ | ORDER BY | ORDER BY (➡TOP) | 정렬(➡상위 N개 보여주기) |
문법 작성 순서 : SELECT ➡ FROM ➡ WHERE ➡ GROUP BY ➡ HAVING ➡ ORDER BY
실행 작동 순서 : FROM ➡ (ON➡JOIN) ➡ WHERE ➡ GROUP BY ➡ CUBE | ROLLUP ➡ HAVING ➡ SELECT ➡ DISTINCT ➡ ORDER BY ➡ TOP
SELECT, FROM, WHERE
-
ALL : 생략 가능
-
DISTINCT : 중복 하나만 남기고 제거(속도가 느려질 수 있어 사용하는 것을 자제해야한다.)
- mysql/oracle
SELECT DISTINCT 컬럼 FROM 테이블; SELECT COUNT(DISTINCT 컬럼) FROM 테이블; # 컬럼 범주 개수 조회 SELECT DISTINCT EMP_NAME, POSITION FROM TB_EMP; -
as : alias, 별명을 부여. 아래 두가지 다 가능(as 생략 가능)
- mysql/oracle
SELECT EMP_NAME AS 사원명, POSITION AS 직책, ENT_DATE AS 입사일자 FROM TB_EMP; SELECT EMP_NAME 사원명, POSITION 직책, ENT_DATE 입사일자 FROM TB_EMP; -
산술 연산자 : () */ +-
- mysql/oracle
SELECT EMP_NAME, SALARY, (SALARY / 12 * 3) as 보너스 FROM TB_EMP; -
합성 연산자 : CONCAT(string1, strign2), ||, 컬럼과 문자, 다른 컬럼과 연결 시킴
- mysql
SELECT concat('A', 'B') # AB SELECT concat_ws('A', 'B', 'C') # BAC, center -> header -> footer 순서 SELECT concat_ws('A', IFNULL(NULL, ''), 'C') # AC, NULL이 존재하면 결과가 부정확하게 나올 수 있다.- oracle
SELECT EMP_NAME || '의 연봉은 ' || SALARY ||'원 입니다.' FROM TB_EMP;
ORDER BY, LIMIT
DISTINCT
JOIN(INNER/OUTER JOIN)
GROUP BY / HAVING
집계 함수(COUNT, SUM, AVG, MAX, MIN), CUBE, ROLLUP
※ ROLLUP : 맨 처음 명시한 컬럼에 대해서 GROUP BY로 묶은 각각의 소그룹 통계와 전체 통계를 모두 구함
GROUP BY ROLLUP(컬럼1, 컬럼2)
== GROUP BY 컬럼1, 컬럼2 UNION ALL GROUP BY 컬럼1 UNION ALL 모든 집합 그룹 결과
※ CUBE : GROUP BY절에 명시한 모든 컬럼에 대해 소그룹 통계를 계산
GROUP BY CUBE(컬럼1, 컬럼2)
== GROUP BY 컬럼1, 컬럼2 UNION ALL GROUP BY 컬럼1 UNION ALL GROUP BY 컬럼2 UNION ALL 모든 집합 그룹 결과
CASE(if)
SUBQUERY
예시 (프로그래머스)
이름이 없는 동물의 아이디, 프로그래머스
동물 보호소에 들어온 동물 중, 이름이 없는 채로 들어온 동물의 ID를 조회하는 SQL 문
SELECT ANIMAL_ID FROM ANIMAL_INS
WHERE NAME IS NULL;이름이 있는 동물의 아이디, 프로그래머스
동물 보호소에 들어온 동물 중, 이름이 있는 동물의 ID를 조회하는 SQL 문
SELECT ANIMAL_ID FROM ANIMAL_INS
WHERE NAME IS NOT NULL
ORDER BY ANIMAL_ID;NULL 처리하기, 프로그래머스
동물 보호소에 들어온 동물 중, 이름이 없는 채로 들어온 동물의 ID를 조회하는 SQL 문
SELECT ANIMAL_TYPE, IFNULL(NAME, "No name"), SEX_UPON_INTAKE FROM ANIMAL_INS
ORDER BY ANIMAL_ID;
SELECT animal_type, if(name is null, "No name", name), sex_upon_intake
from animal_ins
order by animal_id;없어진 기록 찾기, 프로그래머스
입양을 간 기록은 있는데, 보호소에 들어온 기록이 없는 동물의 ID와 이름을 ID 순으로 조회하는 SQL문
SELECT ANIMAL_ID, NAME FROM ANIMAL_OUTS
WHERE ANIMAL_ID NOT IN (
SELECT ANIMAL_ID FROM ANIMAL_INS
)
ORDER BY ANIMAL_ID;
SELECT OUTS.ANIMAL_ID, OUTS.NAME FROM ANIMAL_OUTS AS OUTS
LEFT JOIN ANIMAL_INS INS
ON (OUTS.ANIMAL_ID = INS.ANIMAL_ID)
WHERE INS.ANIMAL_ID IS NULL
ORDER BY OUTS.ANIMAL_ID없어진 기록 찾기, 프로그래머스
관리자의 실수로 일부 동물의 입양일이 잘못 입력되었습니다. 보호 시작일보다 입양일이 더 빠른 동물의 아이디와 이름을 조회하는 SQL문
SELECT INS.ANIMAL_ID, INS.NAME FROM ANIMAL_INS INS, ANIMAL_OUTS OUTS
WHERE INS.ANIMAL_ID = OUTS.ANIMAL_ID
AND INS.DATETIME > OUTS.DATETIME
ORDER BY INS.DATETIME;
SELECT INS.ANIMAL_ID, INS.NAME FROM ANIMAL_INS AS INS
LEFT JOIN ANIMAL_OUTS AS OUTS # RIGHT/INNER JOIN을 해도 상관없다.
ON INS.ANIMAL_ID = OUTS.ANIMAL_ID
WHERE INS.DATETIME > OUTS.DATETIME
ORDER BY INS.DATETIME;index 추가
index 목록 보기
// user 테이블의 index 목록 보기
show index from user;
