요즘카페에서는 사용자가 이미 본 카페는 삭제하고, 카페들을 거의 다 보았을 때 새롭게 카페를 insert해준다.
이 unviewedCafe insert는 변경감지를 이용해 member수행된다.
 그래서 insert문이 하나씩 여러개 (112개) 나간다. ㅠ
그래서 insert문이 하나씩 여러개 (112개) 나간다. ㅠ
해결방법
개선하는 방법은 id생성이 identity방식인지의 여부에 따라 달라질 수 있다.
id가 identity방식으로 관리되면 hibernate에서는 batch insert를 막기 때문이다.
 할당될 id를 미리알 수 없기에 hibernate의 flush 방식인 쓰기지연과 맞지 않는다.
할당될 id를 미리알 수 없기에 hibernate의 flush 방식인 쓰기지연과 맞지 않는다.Statement.getGeneratedKeys()로 id를 얻어온 후 엔티티에 할당해주어야 하는데, identity방식으로는 쿼리 실행전에 미리 id를 조회해 할당할 수 없다.
sequence방식의 경우에는 미리 DB sequence를 조회해 id를 가져올 수 있다.
db의 id생성 방식 - identity, sequence, table방식이 있다.
db에 따라 지원하는 방식이 다르다.
mysql은 sequence방식을 지원하지 않지만, oracle은 sequence를 지원함.
sequence, table등의 방식으로 id를 생성한다면
hibernate의 지원을 받아 쿼리를 보내고, 채번의 효율을 위해 채번 테이블을 별도로 구성하는 방법을 사용할 수 있다.
identity방식을 사용하는 경우 hibernate가 아닌 다른 기술을 이용한다.
1 ) java로 데이터 접근하는 다른 기술들(jdbc, jooq...)을 이용
2 ) 네이티브 쿼리를 사용
정도의 선택지가 있다.
각 방식에 대해서 알아보자.
결과적으로는 이 중 identity id/ jdbc/ mysql을 사용하는 방법을 이용했다.
우리 프로젝트에서의 상황은 카페를 다 본 후 바로 빠르게 채워주어야 하는 작업이다. batch insert작업이지만 그 크기가 심하게 크지도 않고 batch작업의 스케줄링이 필요한 게 아니라 카페를 다 본 순간 바로 insert하는 작업이기에 spring batch는 고려하지 않았다.
id를 identity로 generate하지 않을경우
jdbc.batch_size옵션을 사용할 수도 있고, hibernate를 사용하는 spring data jpa, jpql 등도 다 사용할 수 있다.
아래 hibernate 공식문서에 나온 방법들을 모두 고려해 볼 수 있다.
hibernate batch docs
-
size를 설정하고 entitymanager로 쿼리를 persist하다가 해당 size마다 flush하는 방식.
-
jdbc_batch_size옵션을 적용한 후 spring data jpa로 saveAll()하는 방식.
등이 있다.
다만 이 방법이 무조건 빠르다고는 할 수 없다.
identity방식에 비해 id를 관리하는 성능이 안좋기에 insert의 효율성이 늘어나도 id채번 때문에 최종적인 성능은 낮을 수 있다.
id 생성방식에 따른 insert성능 비교
SEQUENCE나 TABLE 방식 id관리 보완
이 경우 id채번 자체를 batch로 해서 개선할 수 있다고 한다.
table방식 id채번 batch하기
identity방식으로 id생성할 경우
결론적으로는 추가적인 의존성을 필요로 하지도 않고, 충분한 성능 향상을 제공하는 jdbc를 이용했다. mysql에서 jdbc커넥터를 사용할 경우 쿼리를 재작성해 성능을 높여주는 bulk insert관련 옵션도 이용했다.
하나씩 나가던 insert쿼리가 아래처럼 multi-values 쿼리로 나가게 된다.
insert into test_data (created_at, uuid, id) values
('2020-11-22 19:28:05.79', '6c5fe953-ec38-4b26-b2f7-29a389cb8c03', 619988)
,('2020-11-22 19:28:05.79', '1959cb84-1dd5-42cc-95c1-8fd501881f1f', 619989)
,('2020-11-22 19:28:05.79', 'daf8073e-78ea-435c-ac36-ac0796c4c283', 619990)
,('2020-11-22 19:28:05.79', 'b98761f6-5f0b-448c-8f7f-aeffc22032d6', 619991)
,('2020-11-22 19:28:05.79', '9a740e9c-2249-4c05-9349-9118c5825755', 619992)
,('2020-11-22 19:28:05.79', 'd1b0e19c-9002-40d9-a43c-ae5e7293a7f4', 619993)
,('2020-11-22 19:28:05.79', '5ac02554-a877-4d1e-93b1-3f15bb58261c', 619994);
이 경우 hibernate의 영속성 컨텍스트를 통하지 않기에 영속성 컨텍스트와의 정합성을 맞춰야 할 상황도 있다는 걸 생각해야 한다.
jdbc의 batchUpdate
jdbc의 batchUpdate를 사용할 경우 db와의 통신 횟수를 줄임으로써 성능을 개선할 수 있다.
batchUpdate를 사용하는 기본적인 예시를 공식문서에서 확인해보자.
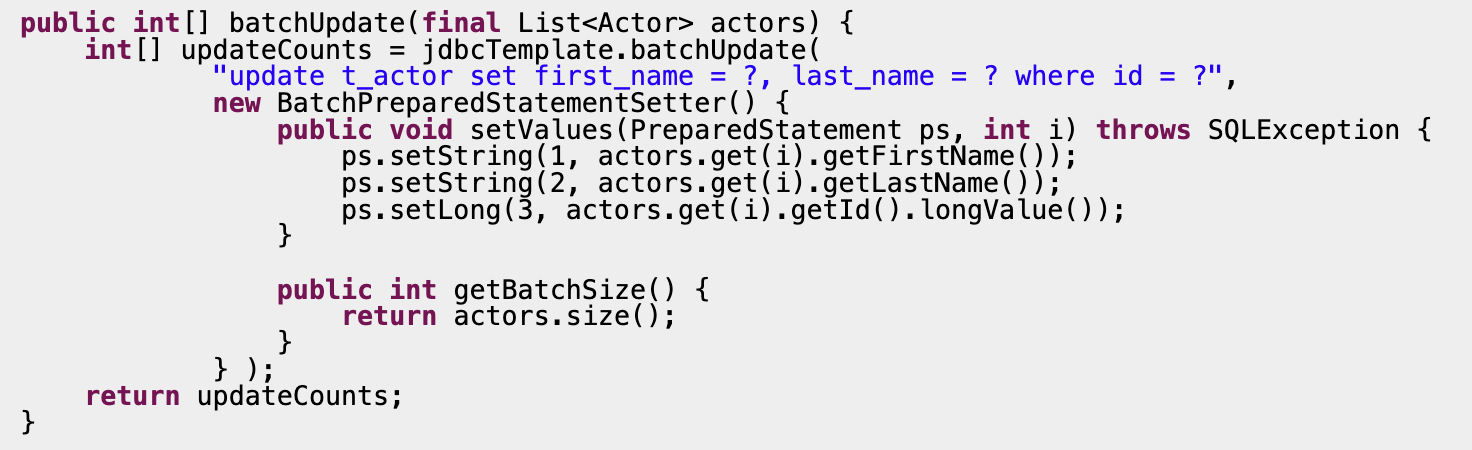
https://docs.spring.io/spring-framework/docs/3.0.0.M4/reference/html/ch12s04.html
https://www.baeldung.com/spring-jdbc-batch-inserts
하지만 mysql을 쓸 경우, 이렇게만 해서는 multi-value로 쿼리가 처리되지 않을 것이다. 추가적인 설정을 보자.
mysql bulk insert
multi value를 저장하는 방법을 지원하는 db들이 있다. 이를 통해 insert into ? values (),()...식으로 한번에 Insert를 여러개 처리하도록 할 수 있다.
Some databases such as Postgres, MySQL, and SQL Server support multi-value inserts
mysql, jdbc드라이버를 사용할 경우 rewriteBatchedStatements=true 옵션을 주어야 multi-value형식으로 쿼리가 실행된다.
https://dev.mysql.com/doc/refman/8.0/en/optimizing-innodb-bulk-data-loading.html
rewriteBatchedStatements옵션 docs
mysql의 auto_increment handling
그런데 의문점이 있다.
그런데 bulk insert를 하더라도 id를 identity방식 - auto_increment로 생성할 것이다.
이때 이 id 채번하는 것은 결국 하나씩 증가해야 하는 처리일텐데 최적화가 가능할까?
mysql에서는 이를 어떻게 handling하는 지 공식문서를 보자
“This section describes the AUTO_INCREMENT lock modes used to generate auto-increment values, and how each lock mode affects replication. The auto-increment lock mode is configured at startup using the innodb_autoinc_lock_mode variable
https://dev.mysql.com/doc/refman/5.7/en/innodb-auto-increment-handling.html
innodb_autoinc_lock_mode로 id값 생성 시의 락을 제어할 수 있다.
이 lock_mode에서는 아래와 같은 insert문을 아래와 같은 종류들로 나눠서 다룬다.

innodb_autoinc_lock_mode
위 공식문서에서 알 수 있 듯, auto_increment id를 생성할 때 lock을 거는 방식을 설정할 수 있다.
0(tradiational)모드에서는 테이블 락을 걸어 insert시 다른 insert작업은 기다려야 한다.(트랜잭션 내내 락이 걸리는 것은 아니고, 해당 statement가 끝날 때까지)
1(consecutive)모드에서는 id를 생성하는 작업에만 mutex를 통해 lock을 걸기에 여러 insert작업을 더 병렬적으로 가능하다. 다만 bulk insert시에는 여전히 테이블락이 걸린다.
2(interleaved)모드에서는
bulk insert까지도 AUTO_INCREMENT id값들을 생성 시에만 mutex를 통한 락이 걸린다. 즉 bulk insert시의 병렬성이 개선된다. 하지만 id사이의 간격이 bulk insert끼리의 동시작업으로 인해 일정하지 않게 될 수 있고, replication시에 문제가 생길 수 있다.
bulk insert시에는 이 innodb_autoinc_lock_mode설정도 생각해야 한다.
우리 서비스에서는 bulk insert가 동시적으로 일어나야 할 정도로 자주 일어나진 않고, 바이너리 로그를 이용한 replication을 하고 있기에 1(consecutive모드)로 설정했다.
querydsl-sql 혹은 EntityQL
주로 jdbc가 추가적인 의존성 없이 많이 선택될 것 같다.
다만 jdbc의 아쉬운 점은 sql을 문자열로 다루기에 typesafe하지 않아 유지보수에 단점이 있다.
이 때문에 querydsl에서의 네이티브 쿼리를 가능하게 하는 querydsl-sql을 고려할 수 있지만, 추가적인 설정이 많다는 단점이 있다. 이보단 좀 더 쉽게 사용가능한 entityQL이라는 라이브러리도 있다.
하지만 많은 batch 작업을 해야하는 게 아닌 이상 웬만하면 jdbc로 하는 게 더 경제적일 것 같다.
https://jojoldu.tistory.com/558
https://joanne.tistory.com/270
실험
아래처럼 jdbcTmeplate을 통해 batchupdate하는 repository를 만들었다. 실험해보자
30000개의 카페 데이터를 실험으로 넣었다.
@Repository
public class CafeJdbcRepository {
private final JdbcTemplate jdbcTemplate;
public CafeJdbcRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Transactional
public void saveUnviewedCafes(List<Cafe> cafes, Member member) {
int batchSize = 60;
int batchCount = 0;
List<Cafe> subItems = new ArrayList<>();
for (int i = 0; i < cafes.size(); i++) {
subItems.add(cafes.get(i));
if ((i + 1) % batchSize == 0) {
batchCount = batchInsert(batchCount, subItems, member.getId());
}
}
if (!subItems.isEmpty()) {
batchCount = batchInsert(batchCount, subItems, member.getId());
}
System.out.println("batchCount: " + batchCount);
}
private int batchInsert(int batchCount, List<Cafe> subItems, String memberId) {
String sql = "INSERT INTO un_viewed_cafe (`cafe_id`, `member_id`) VALUES (?, ?)";
jdbcTemplate.batchUpdate(sql,
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setLong(1, subItems.get(i).getId());
ps.setString(2, memberId);
}
@Override
public int getBatchSize() {
return subItems.size();
}
}
);
subItems.clear();
batchCount++;
return batchCount;
}
}
기존처럼 변경감지로 할떄
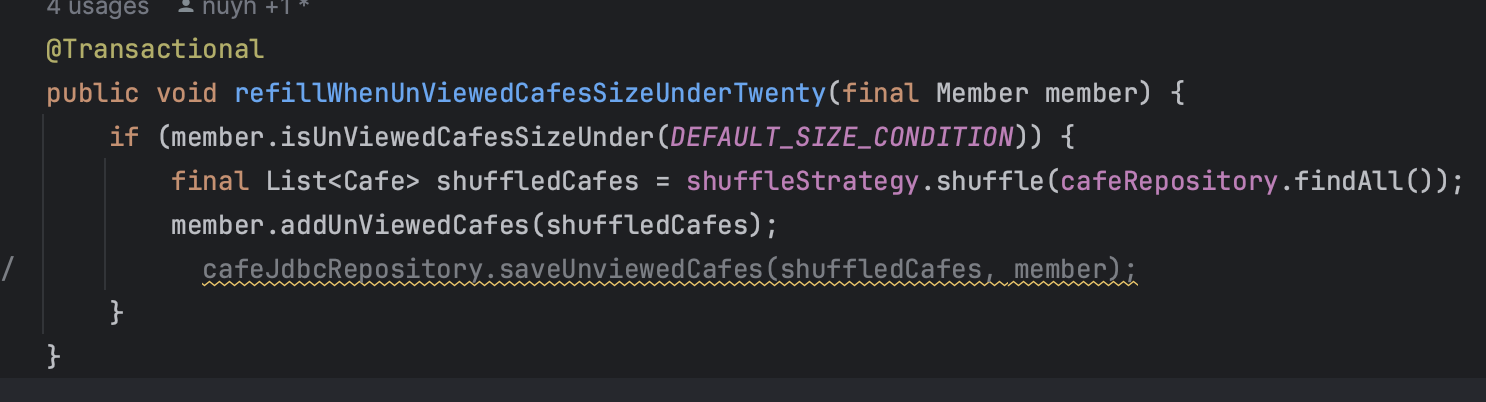


16초 정도 걸린다.
jdbc로 batch 작업할때
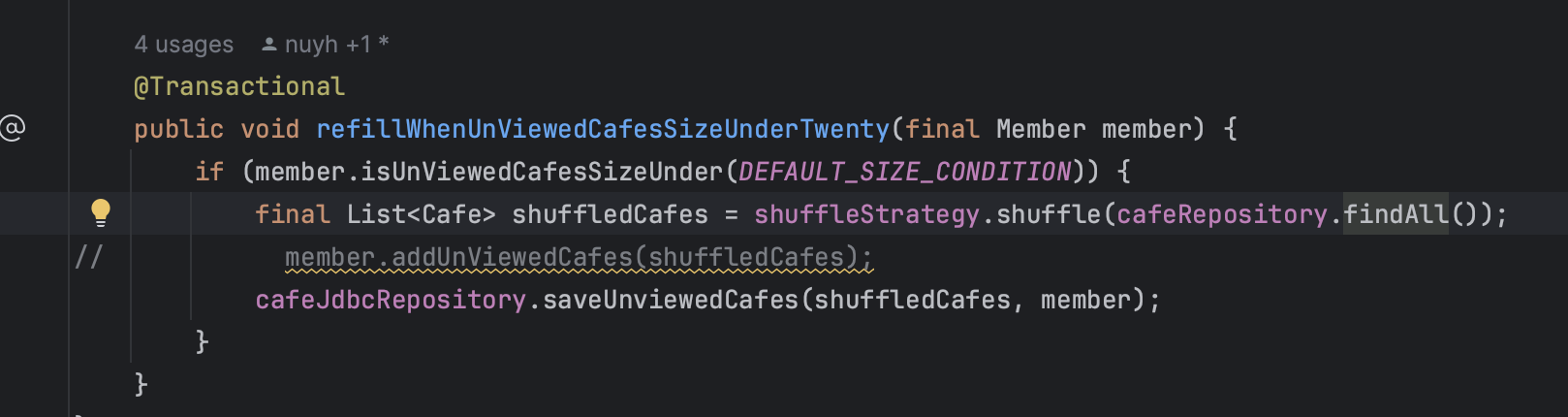
여기서의 queryCount개수는 hinernate의 inspector의 의존한 것이기에 jdbc로 직접 쿼리한 이 batch 작업의 쿼리개수는 포함되지 않고 있다.
때문에 queryCount는 신경쓰지 말고 보자.
jdbcTemplate.batchupdate를 통한 성능향상도 있지만
더 큰 개선을 기대할 수 있는 부분은 rewriteBatchedStatements옵션을 통해서이다.
하나씩 날아가던 insert문을 아래처럼 insert into values..문으로 한번에 여러개를 실행할 수 있다.
https://dev.mysql.com/doc/connector-j/8.1/en/connector-j-connp-props-performance-extensions.html
rewrite옵션 안 건 경우


16초에서 11초로 성능 개선이 있기는 하다.
rewriteBatchedStatement옵션까지 건 경우



1초 좀 넘게 걸린다. 16초에 비해 놀라운 성능개선이 있다.
