fulltext search란
full text search는 mysql8부터 지원하는 기능이다
FULLTEXT INDEX를 걸고, MATCH ... AGAINST 구문으로 사용할 수 있다.
mysql의 innodb나 myisan엔진에서만 사용가능하다.
예시
# MATCH() in SELECT list...
SELECT MATCH (a) AGAINST ('abc') FROM t GROUP BY a WITH ROLLUP;
SELECT 1 FROM t GROUP BY a, MATCH (a) AGAINST ('abc') WITH ROLLUP;
# ...in HAVING clause...
SELECT 1 FROM t GROUP BY a WITH ROLLUP HAVING MATCH (a) AGAINST ('abc');
# ...and in ORDER BY clause
SELECT 1 FROM t GROUP BY a WITH ROLLUP ORDER BY MATCH (a) AGAINST ('abc');match against 3가지 모드
MATCH ... AGAINST를 3가지 모드로 사용한다.
- natural language mode
- boolean mode
- with query expansion
기본적으로는 natural모드로 동작한다.
내부적으로 문서에 각 단어들이 얼마나 많이 존재하는 지를 통해 중요도(weight)가 계산되고, 적게 존재하는 단어일수록 높은 중요도를 갖는다.
검색 시 이 중요도, 검색 필드의 길이 등에 따라 검색어가 포함된 결과를 순서대로 조회한다.
boolean mode에서는 이에 더해 더 다양한 검색 조건들을 줄 수 있다.
ex)검색어를 완전히 그대로 포함해야함 , 어떤 단어는 포함하지 않아야함...
with query expansion
는 검색 결과 안에서의 주요 단어들로 또 검색을 해 사용자가 놓쳤을 수도 있는 관련 데이터까지 검색해준다.
-단계1: 사용자가 제공한 검색어로 일반적인 FULLTEXT 검색을 수행
-단계2: 첫 번째 단계에서 얻은 가장 관련성이 높은 문서들에서 자주 등장하는 단어들을 찾아내, 이를 원래의 검색어에 추가하여 다시 한번 검색을 수행
위의 2단계로 더 넓은 관련성의 검색을 제공한다.
full text 인덱스
Full-text index는 MySQL에서 에서 FULLTEXT 타입의 인덱스이다.
그런데 원래 built-in된 기본 text parser는 공백 단위로 되어있기에
어절에 완전히 일치하는 것만 조회해온다.
부분 문자열(part-of-word) 검색이 안된다는 것인데, 예를 들면
mysql fulltext index라는 데이터가 있고 'my', 'full'라는 검색어로 조회해도 한 어절과 완전히 일치하지는 않기에 검색되지 않는다는 것이다.
이를 글자 단위로 검색가능하게 하기 위해 n-gram parser를 지원한다.
다만 더 작은 단위로 text의 인덱스들을 많이 생성하기에 더 많은 메모리를 사용한다는 것을 인지해야한다.
아주 많은 text에 대해 n-gram parser의 token사이즈를 작게 잡으면 db에서도 인덱스 사용 시 디스크에 접근할 가능성이 높아져 성능이 저하될 수 있다.
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search-ngram.html
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html
실험준비
0단계. fullText Index 걸기, n-gram parser 적용
alter table cafe add FULLTEXT INDEX name_idx (name) with parser ngram이후
show global variables like 'ngram_token_size';로 토큰 사이즈 확인. 기본은 2로 설정되어 있다.
1단계. 더미데이터 insert
2단계. match-again문 날려보기
3단계. 결론 - fulltext search를 적용할지, 어떤 모드를 선택할 지 결정
더미데이터 집어넣기
- 카페 만 개 insert쿼리
INSERT INTO cafe (name, address, description, map_url, phone)
SELECT
CONCAT(
'Cafe ',
CHAR(65 + FLOOR(RAND() * 26)), -- Random uppercase letter (A-Z)
CHAR(97 + FLOOR(RAND() * 26)), -- Random lowercase letter (a-z)
CHAR(97 + FLOOR(RAND() * 26)), -- Random lowercase letter (a-z)
' Cafe'
) AS name,
CONCAT('Address 주소', FLOOR(RAND() * 10000)) AS address,
'Description' AS description,
CONCAT('Map URL ', FLOOR(RAND() * 10000)) AS map_url,
CONCAT('Phone ', FLOOR(RAND() * 10000)) AS phone
FROM (
SELECT n FROM (
SELECT a.n + b.n*10 + c.n*100 + d.n*1000 as n
FROM
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) a,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) b,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) c,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) d
) numbers
) rand_data;
- 카페명,메뉴명,주소명 다 랜덤하게 데이터 집어넣기
INSERT INTO cafe (name, address, description, map_url, phone)
SELECT
CONCAT(
'Cafe ',
CHAR(65 + FLOOR(RAND() * 26)), -- Random uppercase letter (A-Z)
CHAR(97 + FLOOR(RAND() * 26)), -- Random lowercase letter (a-z)
CHAR(97 + FLOOR(RAND() * 26)), -- Random lowercase letter (a-z),
' Cafe'
) AS name,
CONCAT('Address 주소주소주소', CHAR(97 + FLOOR(RAND() * 26)), CHAR(97 + FLOOR(RAND() * 26)), FLOOR(RAND() * 10000)) AS address,
'Description' AS description,
CONCAT('Map URL ', FLOOR(RAND() * 10000)) AS map_url,
CONCAT('Phone ', FLOOR(RAND() * 10000)) AS phone
FROM (
SELECT n FROM (
SELECT a.n + b.n*10 + c.n*100 + d.n*1000 as n
FROM
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) a,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) b,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) c,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) d
) numbers
) rand_data;
- 랜덤한 메뉴 데이터 집어넣기
-- Set the session to allow auto-increment values during inserts
SET @@auto_increment_increment=1;
SET @@auto_increment_offset=1;
-- Loop to generate and insert 10,000 random 8-character strings into the menu table
INSERT INTO `yozm-cafe`.menu (cafe_id, priority, name, image_url, description, price, is_recommended)
SELECT
(SELECT id FROM `yozm-cafe`.cafe ORDER BY RAND() LIMIT 1), -- Select a random cafe_id
FLOOR(RAND() * 100),
CONCAT(
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(97 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(97 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(97 + FLOOR(RAND() * 26)),
CHAR(65 + FLOOR(RAND() * 26)),
CHAR(97 + FLOOR(RAND() * 26))
),
CONCAT('Image URL ', FLOOR(RAND() * 10000)),
'Description',
CONCAT('$', FLOOR(RAND() * 100)),
FLOOR(RAND() * 2)
FROM
(SELECT n FROM
(SELECT a.n + b.n*10 + c.n*100 + d.n*1000 as n
FROM
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) a,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) b,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) c,
(SELECT 0 as n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) d
) numbers
) rand_data
LIMIT 10000; -- Limit to 10,000 rows
실험
try1 - 무의미
랜덤한 데이터를 넣어 테스트하지 않아 실패... 실험준비에서 처럼 랜덤한 데이터를 넣어주어야 한다.
like검색
-
address 검색
-

-

-
name검색
-

-

fulltext search
- address검색


- name검색


이 경우 전체조회를 하는건데 그러면 인덱스를 타는 의미가 없다
랜덤한 더미데이터를 만들어야 한다.
try2 - 조건 2개
랜덤한 데이터 - 조건2개일 경우
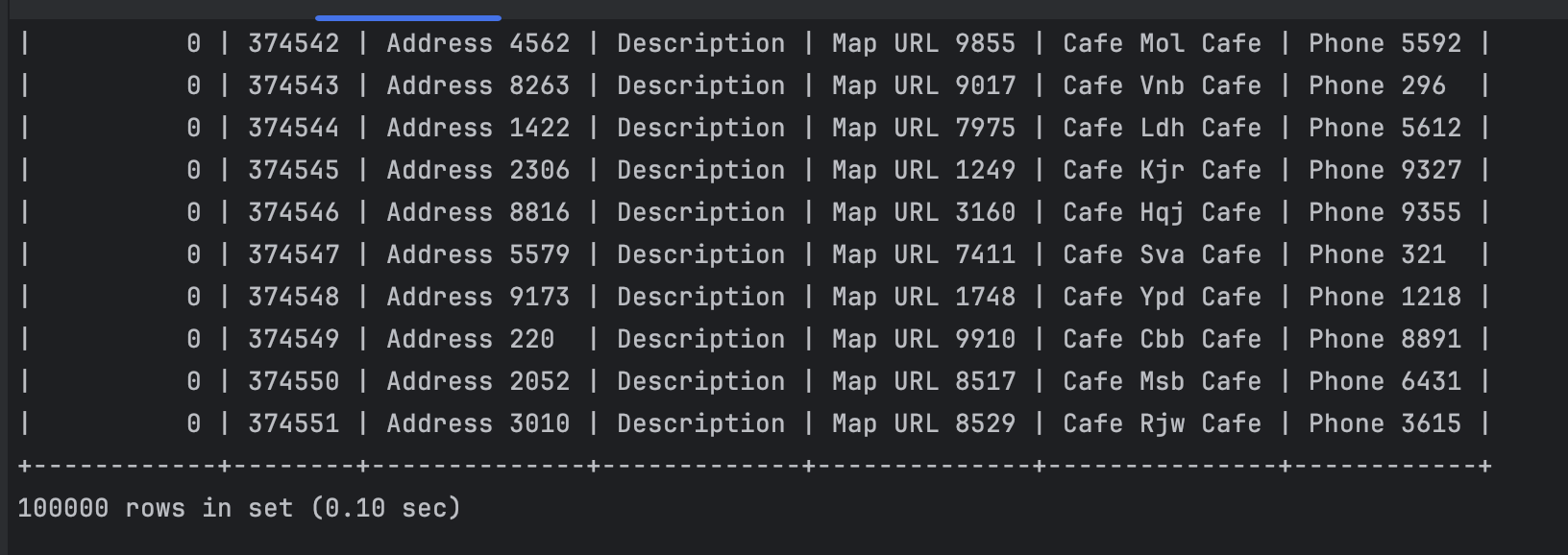
5만개의 카페와 2만개의 메뉴 데이터에서 검색한다
결과
한 조건에 대해서만이면 인덱스를 건게 조금 더 효율적이다. 그런데 여러 조건에 걸쳐 검색되면서 범위 터플이 적어진 상태에서는 인덱스를 건 게 오히려 느릴 수 있다
2가지 조건 걸어 like검색 - 0.07초
SELECT
c.id,
c.address,
c.description,
c.map_url,
c.phone,
c.like_count,
c.name
FROM
cafe c
JOIN
menu m ON m.cafe_id = c.id
WHERE
LOWER(c.name) LIKE '%e C%' ESCAPE '!'
AND LOWER(c.address) LIKE '%hw%' ESCAPE '!';
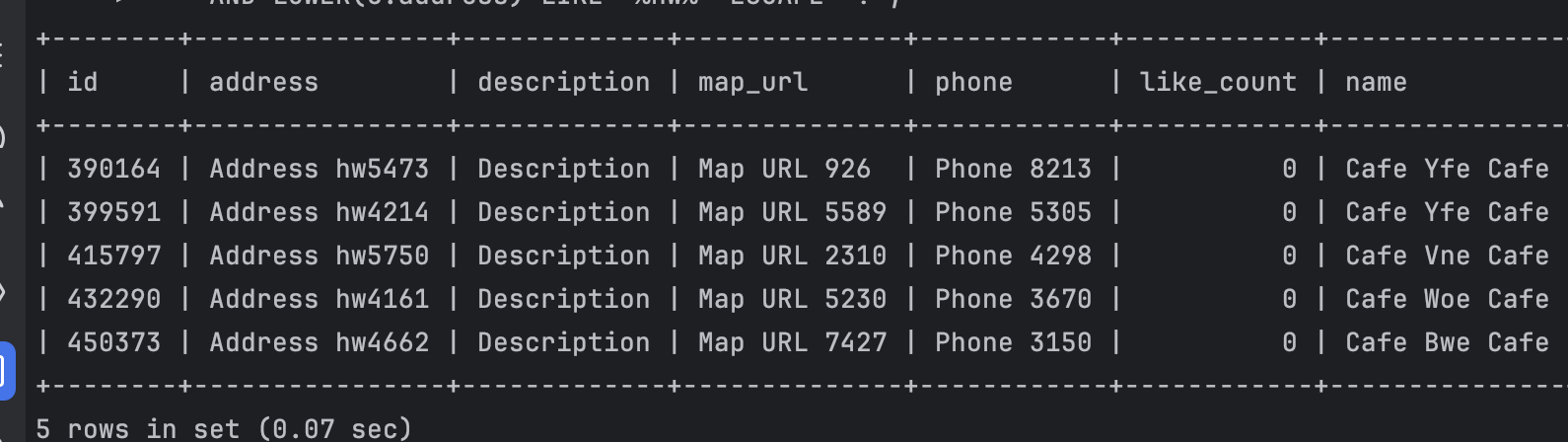
0.07초
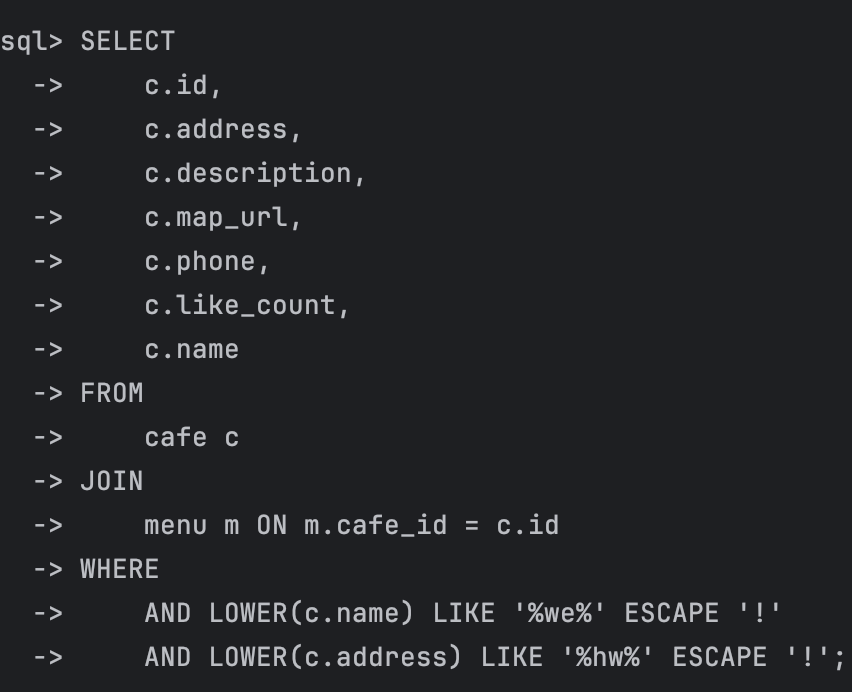
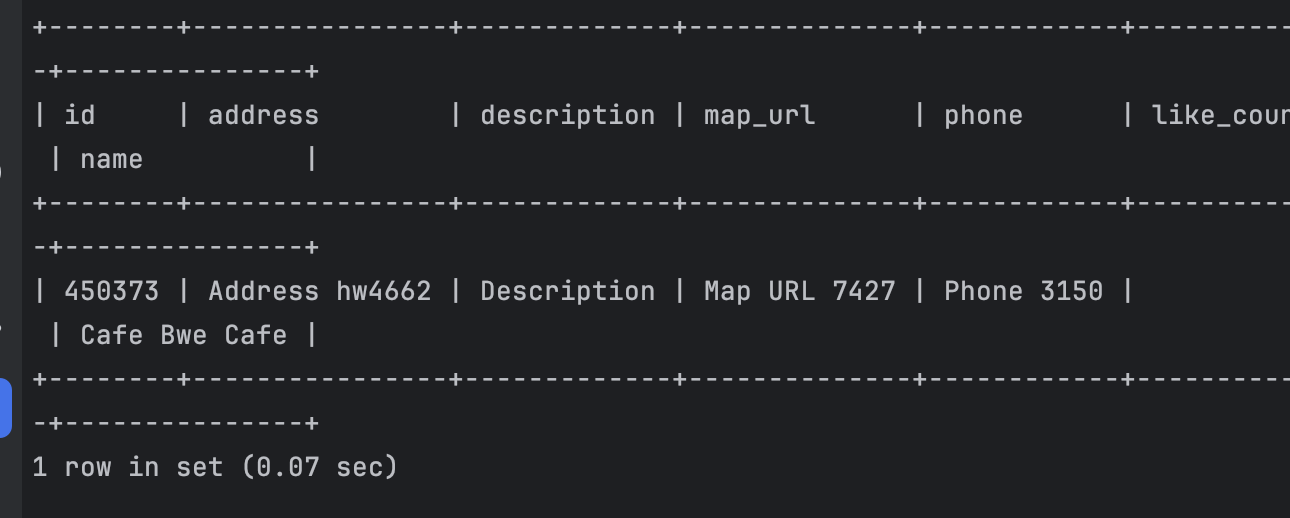
0.07초
2가지 조건 걸어 full text search - 0.15초
SELECT
c.id,
c.address,
c.description,
c.map_url,
c.phone,
c.like_count,
c.name
FROM
cafe c
JOIN
menu m ON m.cafe_id = c.id
WHERE
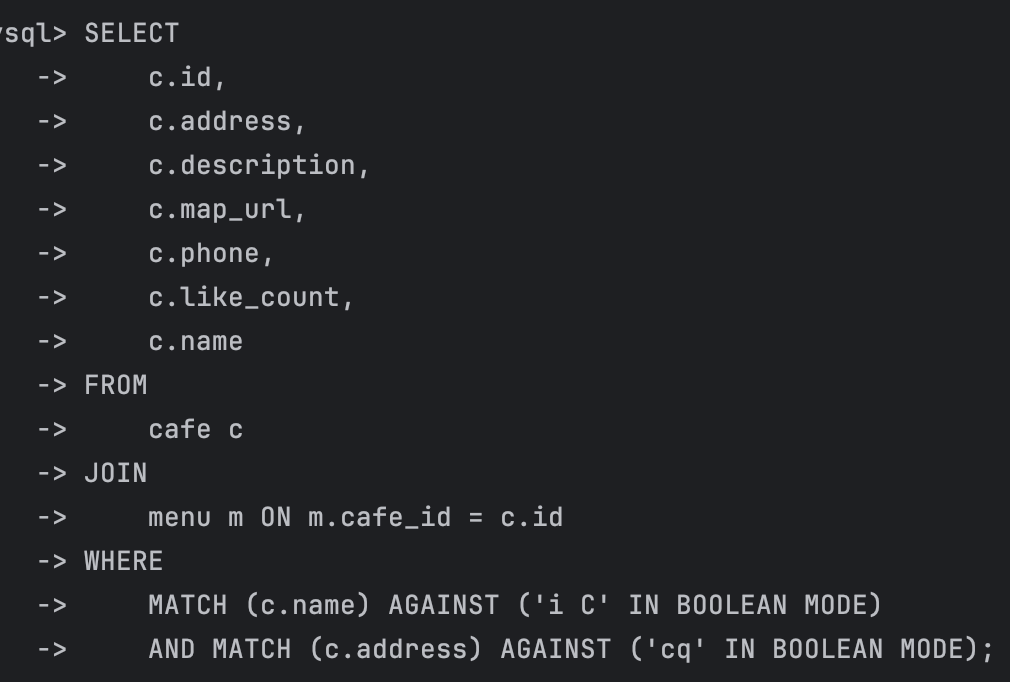
MATCH (c.name) AGAINST ('i C' IN BOOLEAN MODE)
AND MATCH (c.address) AGAINST ('cq' IN BOOLEAN MODE);
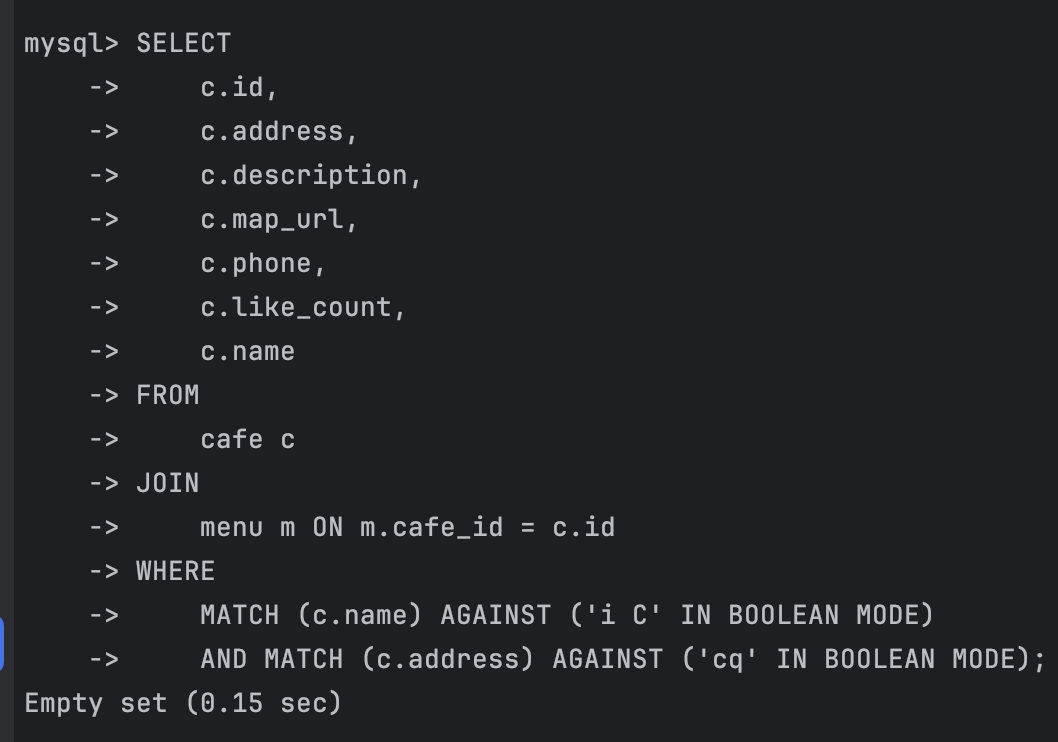
try3 - 조건 1개
랜덤한 데이터 - 조건 1개일 경우
결과
fulltext search가 조금 더 빠르다.
like검색 - 0.10
- 쿼리

- 결과

fulltext search - 0.08
-
쿼리

-
결과
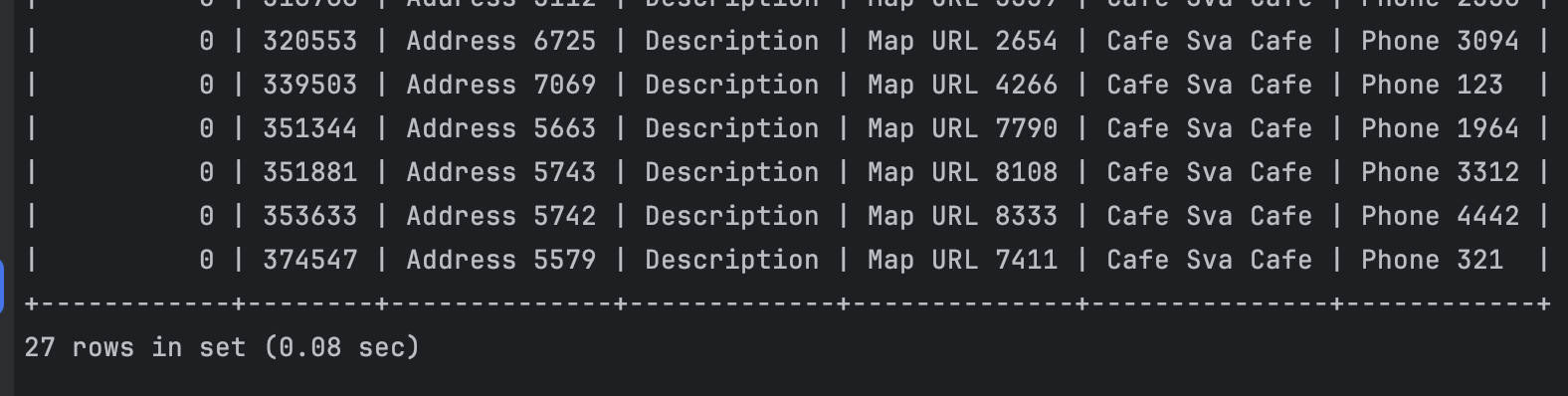
결론
1개의 쿼리에 대해서는 fulltext search가 좀 더 빠르다.
다만 검색 조건이 중첩되어 여러 번의 조회를 할 경우에,
한 번 걸러진 상태에서는 해당 데이터들을 full-scan하는 like검색이 더 빠른 상황도 있다.
우리 서비스에서는 조건을 중첩해서 검색할 상황은 많지 않을거라 생각해 fulltext search를 도입하기로 한다.
