이번 포스트에서는 경기 데이터에 대해 정리했다.
TFT api를 통해 얻은 데이터를 바탕으로 첫 번째로 만들고 싶은 데이터프레임은 다음과 같다.
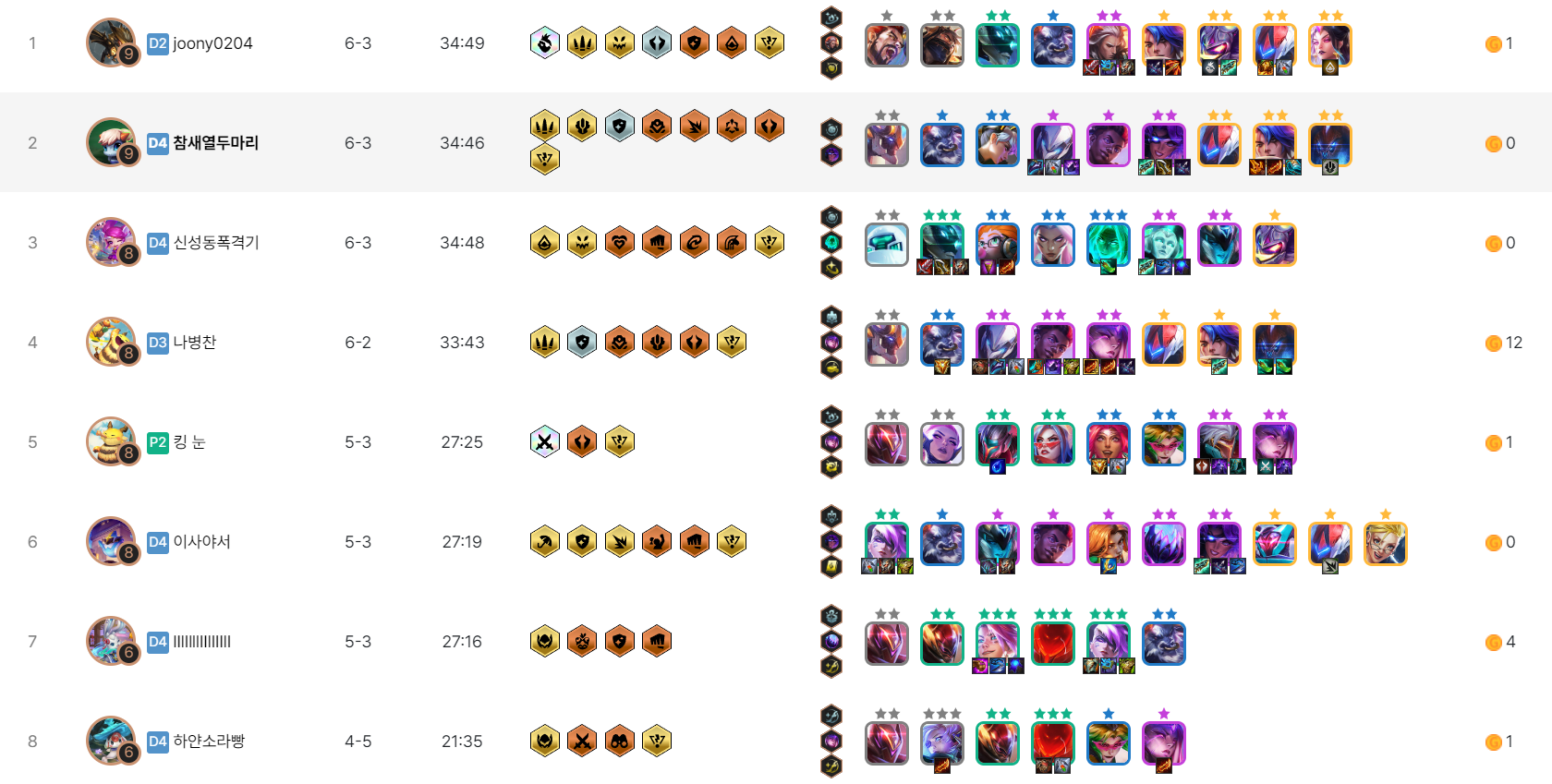
(출처 : 롤체지지)
현재까지 API에서 추출한 경기 데이터에 한글화를 진행했다. 다음 단계로 넘어가보자.
1. 경기 데이터에 필요한 column
현재까지 추출한 데이터프레임은 다음과 같다.
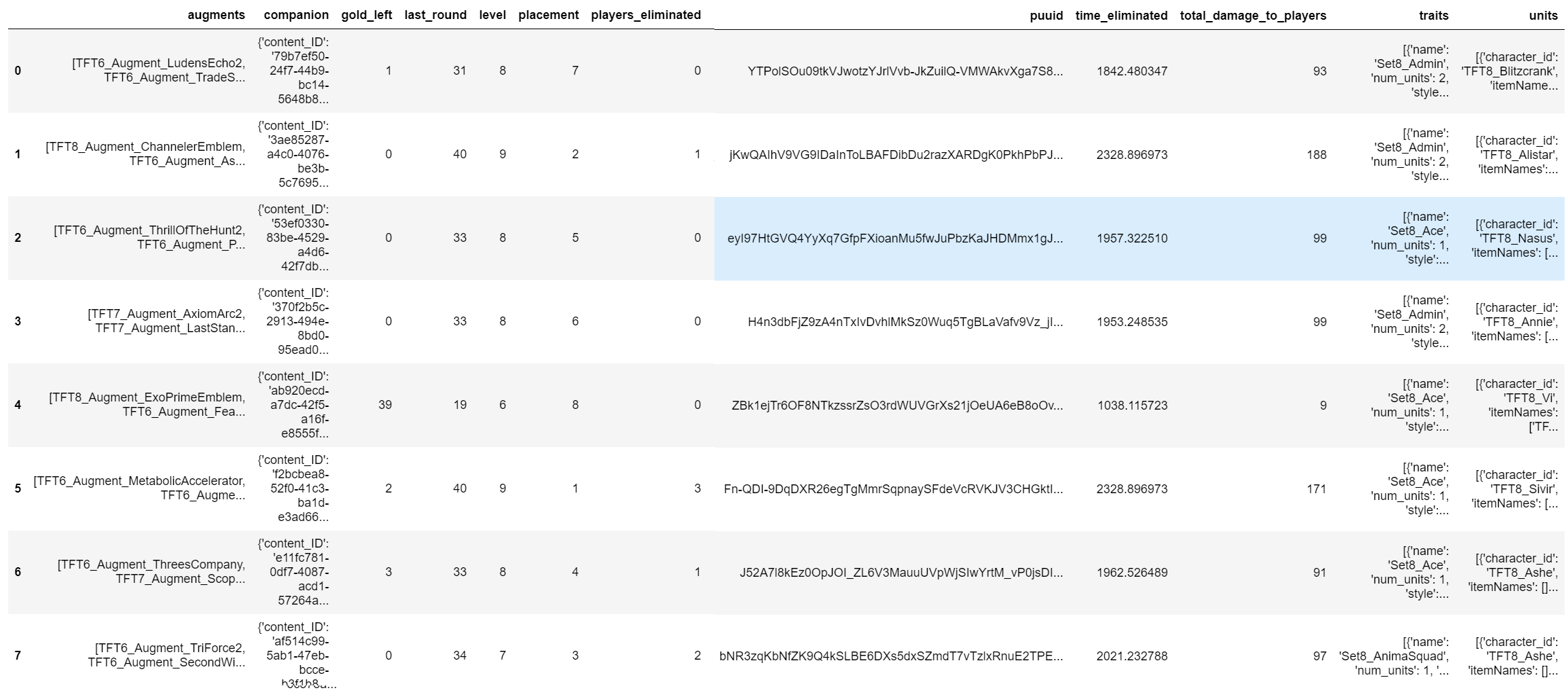
경기 데이터이고(participants), 해당 column의 augments에는 증강체가, traits에는 특성이, units에는 사용한 유닛과 아이템이 적혀있다. (여기서 증강체는 한글 변환이 진행되어 있다.)
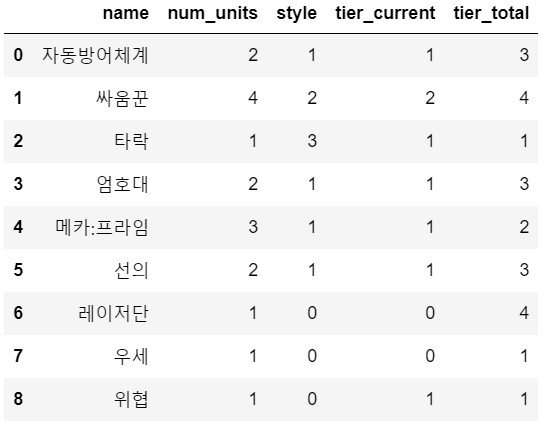
특성 데이터이다. (participants에는 해당 데이터프레임이 8개 존재한다. 해당 데이터프레임은 첫 번째 유저의 특성 결과이므로 first_user_trait으로 지정했다.)
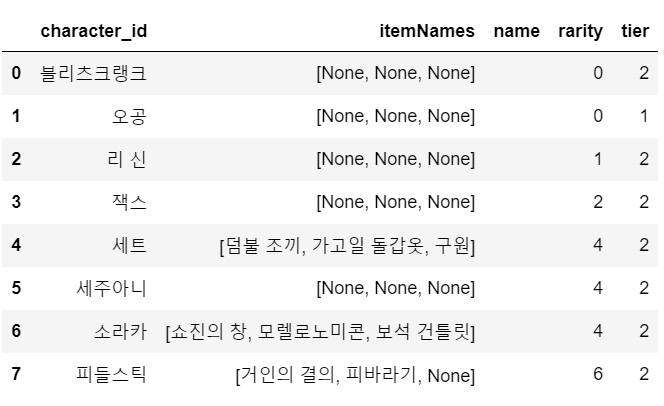
유닛 데이터이다. 유닛마다 아이템을 착용하지 않는 칸은 None으로 표시해두었다. (특성 데이터와 마찬가지로 participants에 해당 데이터프레임이 8개 존재한다. 해당 데이터프레임은 첫 번째 유저의 유닛 결과이므로 first_user_unit으로 지정했다.)
해당 데이터프레임들을 이용해서 경기 결과를 데이터 프레임으로 정리하기 위해서는 다음의 정보가 필요하다.
- Datetime : 해당 게임 한 날짜.
- Game_id : 해당 게임에 대한 이름이 필요하다. 이를 정의해주는 column인 Game_id column!
- Player_id : player 정보 또한 필요하다. Game_id와 player 정보를 알고 있으면 특정 게임에 특정 유저의 플레이 기록을 바로 찾을 수 있다.
- Placement : 등수, 게임 결과에 필수적으로 필요하다!
- Time : 해당 게임 플레이 시간.
- Last_round : 게임이 끝났을 때의 마지막 라운드. 이를 통해 게임 템포를 확인할 수 있다.
- Damage_player : 해당 유저가 다른 유저에게 가한 데미지. 게임이 끝났을 때 최종 결과만 제공하는 API에서 초중반에 어떤 운영을 진행했는지 확인할 수 있는 지표 중 하나이다.
- Gold_left : 게임이 끝났을 때 남은 골드
- augment1, augment2, augment3 : 증강체. 각각 2-1, 3-2, 4-2에 선택한 증강체이다.
- traits : 최종 조합 특성 정보
- units : 최종 조합 유닛 정보
여기서 특성과 유닛 column의 경우 문제가 존재한다. 전략가의 왕관에 따라 최대 기용할 수 있는 유닛 수가 10이 넘어갈 수 있기 때문에, augment처럼 unit1, unit2, ...라는 column을 지정할 수 없다. 이는 특성 부분도 마찬가지이다. 따라서, 이를 해결하기 위해 traits와 units column에 속한 element는 list로 지정했고, 세부 정보 column을 추가했다.
-
traits와 관련된 정보
10-1. num_units : 해당 특성을 가진 유닛 수. list로 존재하며, traits에 속하는 list 길이와 같다.
10-2. tier_current : 현재 티어 레벨. list로 존재하며, traits에 속하는 list 길이와 같다.해당 column을 해석하는 방법은 다음과 같다.
- traits column은 해당 유저가 사용한 특성 이름이 차례대로 나열된 list가 삽입된다.
- traits column에 속한 특성 list의 i번째 특성에 해당하는 유닛 수는 num_units에 속한 list의 i번 째 element가 된다.
- traits column 에 속한 특성 list의 i번째 특성에 해당하는 특성 티어는 tier_current에 속한 list의 i번 째 element가 된다.
-
units과 관련된 정보
11-1. unit_tier : 해당 유닛의 성(star)수. list로 존재하며, units에 속하는 list 길이와 같다.
11-2. item_name : 해당 유닛이 착용한 아이템. list로 존재하며, units에 속한 list 길이와 같다.해당 column을 해석하는 방법은 다음과 같다.
- units column은 해당 유저가 사용한 유닛의 이름이 차례대로 나열된 list가 삽입된다.
- units column에 속한 유닛 list의 i번 째 유닛의 성(star)수는 unit_tier에 속한 list의 i번 째 element가 된다.
- units column에 속한 유닛 list의 i번 째 유닛이 착용한 아이템은 item_name에 속한 list의 i번 째 element가 된다.(이 때, i번 째 element는 길이가 3인 리스트이다.)
최종적으로 16개의 column이 존재하는 dataframe이 만들어진다. 목표로 하는 데이터프레임을 game_summary라고 지정하자.
2. DataFrame 만들기
1) 기초 결과 데이터 추출
첫 번째로 전체 게임 경기 데이터프레임(participants)에서 game_summary에 필요한 column을 따로 추출한다.
game_summary = participants[['puuid', 'placement', 'time_eliminated', 'last_round', 'total_damage_to_players', 'gold_left']]
game_summary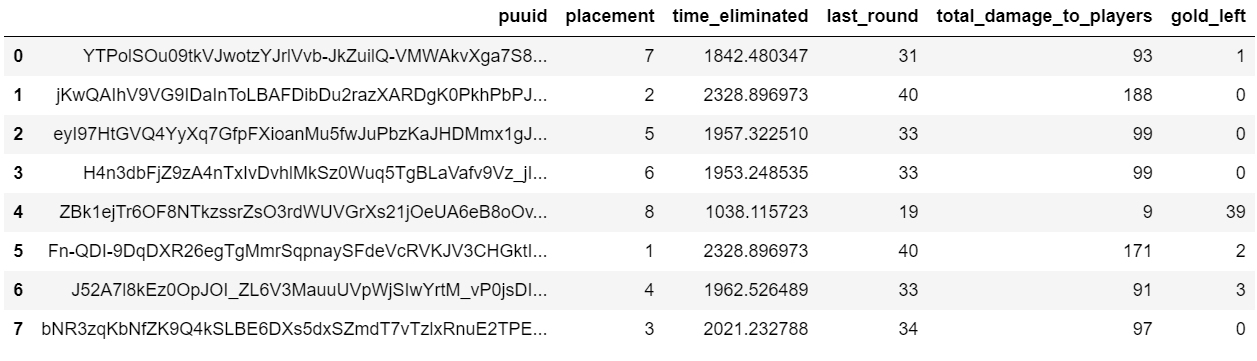
game_id, datetime은 api에서 추출한 데이터(game_result)로부터 얻을 수 있다. 다만 datetime은 unixtimestamp로 기록되어 있어 일반적으로 사용하는 년-월-일 형태로 바꾸어줘야 한다. 해당 값을 이용하여 Game_id column을 game_summary에 추가해준다.
game_id = game_result['metadata']['match_id']
datetime = str(datetime.fromtimestamp(int(game_result['info']['game_datetime'])/1000)).split(' ')[0]
game_summary['Game_id'] = gamd_id
game_summary['Datetime'] = datetime
game_summary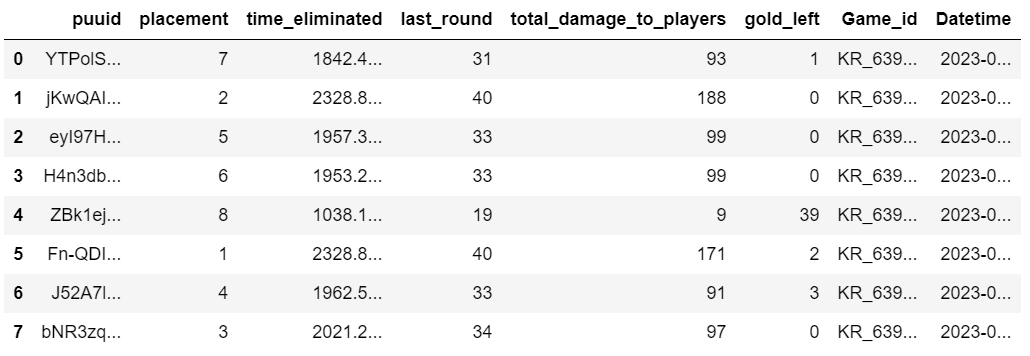
2) 증강체 column 추가
증강체는 3개 존재하므로, 2-1, 3-2, 4-2에 선택한 증강체 순으로 augment1, augment2, augment3 column을 만들 수 있다. 해당 column을 다음과 같이 만들 수 있다.
augment1 = []
augment2 = []
augment3 = []
for augments in participants['augments']:
augments = augments + ['None']*(3-len(augments)) # 증강체를 선택 못한 경우 None으로 처리했다.
augment1.append(augments[0])
augment2.append(augments[1])
augment3.append(augments[2])
augment_df = pd.DataFrame(dict(augment1 = augment1, augment2 = augment2, augment3 = augment3))
game_summary[['augment1', 'augment2', 'augment3']] = augment_df
game_summary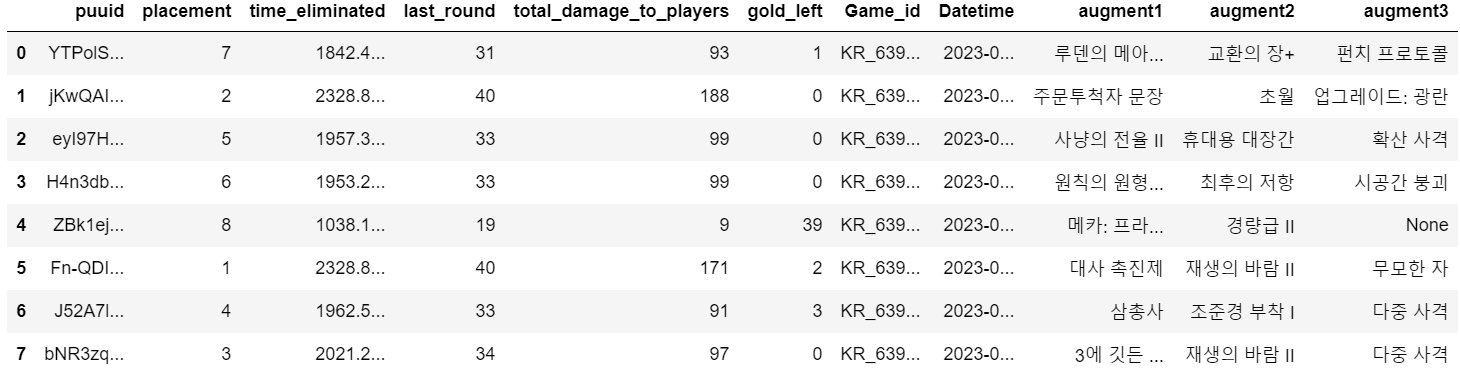
3) 특성 column 추가
participants의 특성 데이터프레임을 이용하여 traits, num_unit, tier_current column을 제작할 것이다. 먼저 traits, num_unit, tier_current을 list로 생성한다.
traits = []
num_unit = []
tier_current = []
여기서 각 유저별로 각각 list에 해당하는 정보를 추가할 것이다.
for participant in range(participants.shape[0]):
check_trait = participants.loc[i, 'traits']
traits.append(check_trait['name'])
num_unit.append(check_trait['num_unit'])
tier_current.append(check_trait['tier_current'])
# 특성명 한글 변환
check_trait = change_traits(dataframe, change_trait)
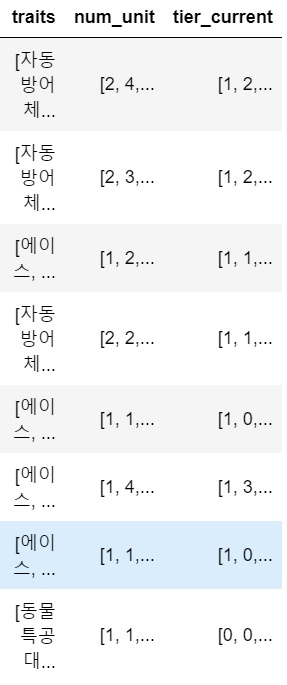
game_summary['traits'] = traits
game_summary['num_unit'] = num_units
game_summary['tier_current'] = tier_current
game_summary
4) 유닛 column 추가
특성 column과 마찬가지로 unit column 역시 추가해준다.
units = []
unit_tier = []
item_name = []
for participant in range(participants.shape[0]):
check_unit = pd.DataFrame(participants.loc[participant, 'units'])
# 유닛, 아이템 이름 한글 변환
check_unit = change_champ_item(check_unit, champ_list, item_aug_list)
units.append(check_unit['character_id'].tolist())
item_name.append(check_unit['itemNames'].tolist())
unit_tier.append(check_unit['tier'].tolist())
game_summary['units'] = units
game_summary['unit_tier'] = unit_tier
game_summary['item_name'] = item_name
game_summary
5) 정리하기
column 명과 순서를 정리해준다.
colname = ['Player_id', 'Placement', 'Time', 'Last_round', 'Damage_player', 'Gold_left', 'Game_id', 'Datetime', 'augment1', 'augment2', 'augment3', 'traits', 'num_units', 'tier_current', 'units', 'unit_tier', 'item_name']
game_summary.columns = colname
game_summary = game_summary[['Datetime', 'Game_id', 'Player_id', 'Placement', 'Time', 'Last_round', 'Damage_player', 'Gold_left', 'augment1', 'augment2', 'augment3', 'traits', 'num_units', 'tier_current', 'units', 'unit_tier', 'item_name']]
game_summary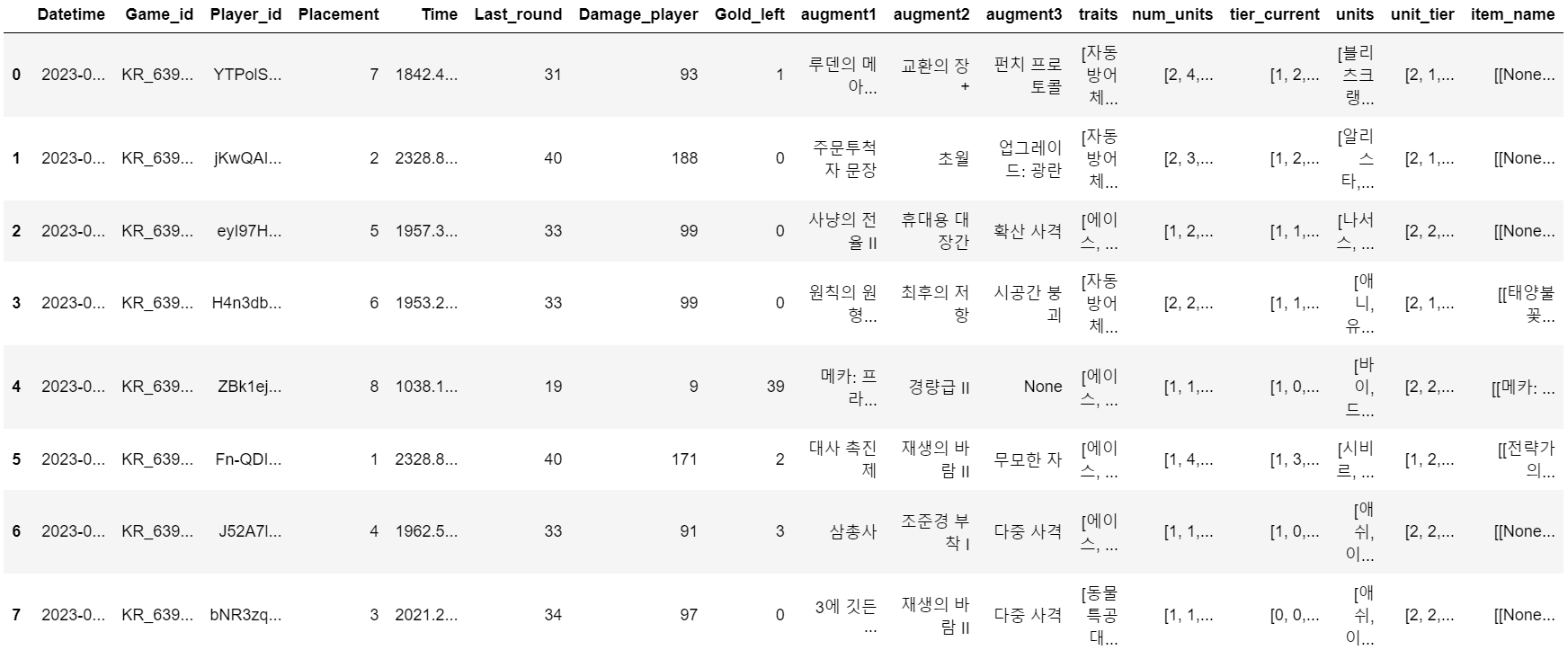
짠! 목표로 한 데이터프레임이 완성되었다.
6) 정리 코드
API에서 추출한 metadata가 있으면 해당 데이터프레임을 만들어주는 class는 다음 github에서 확인할 수 있다.
- 한계
데이터를 받아서 해당 데이터프레임을 변환하는 데 시간이 조금 소요되는 편이다... for문을 많이 써서 그런지 파이썬 자체의 dataframe 구성 시간 때문인지... 약 3만게임 정보를 해당 데이터프레임으로 만드는 과정은 약 3시간 정도 소요된다.
1차 목표는 달성했지만, 해당 데이터프레임으로는 아직 게임 데이터를 분석할 수 없다. 다음 포스트에 계속해서 데이터프레임을 정리할 예정이다.
