이번 포스트에서는 사용 챔피언과 활성화된 특성을 바탕으로 덱을 분류하는 모델링에 대해 정리했다.
1. Data setting
classification을 위한 기본적인 library를 불러왔다.
import numpy as np
import pandas as pd
import sklearn
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
import import_ipynb
import json게임 경기 기록과 해당 경기에서 사용한 덱을 나타낸 데이터프레임을 불러왔다.
game_deck = pd.read_csv('challenger_game_list_deck.csv')
game_deck = game_deck.drop('Unnamed: 0', axis=1)게임 내 플레이어가 사용한 챔피언과 활성화된 특성을 나타내주는 데이터프레임을 작성했다.
# 챔피언 이름 불러오기
champ_list = pd.read_csv('champion_list.csv', encoding='cp949')
champ_list = [i for i in champ_list.Name if i not in ['황금 알', '용병 상자', '증강 보관소', '거대 대게 우르곳', '해커림', '화산 솔', '돌연변이 자크', '훈련 봇']]
# 특성
trait=['민간인', '자동방어체계', '동물특공대', '레이저단', '싸움꾼', '메카:프라임', '위협',
'마스코트', '기상캐스터', '에이스', '결투가', '황소부대', '병기고', '방패대',
'지하세계', '별 수호자', '익살꾼', '선의', '타락', '우세', '무법자', '주문투척자',
'정찰단', '특등사수', '엄호대', '기계유망주', '해커']
game_all_list = {i : [0]*game_deck.shape[0] for i in champ_list}
for i in trait:
game_all_list[i] = [0]*game_deck.shape[0]
for i in range(len(game_deck['units'])):
try:
units = eval(game_deck['units'][i])
for unit in units:
game_all_list[unit][i] +=1
traits= eval(game_deck['traits'][i])
trait_tier = eval(game_deck['tier_current'][i])
if len(traits)==0:
pass
else:
for j in range(len(traits)):
game_all_list[traits[j]][i] += trait_tier[j]
except:
print(i)
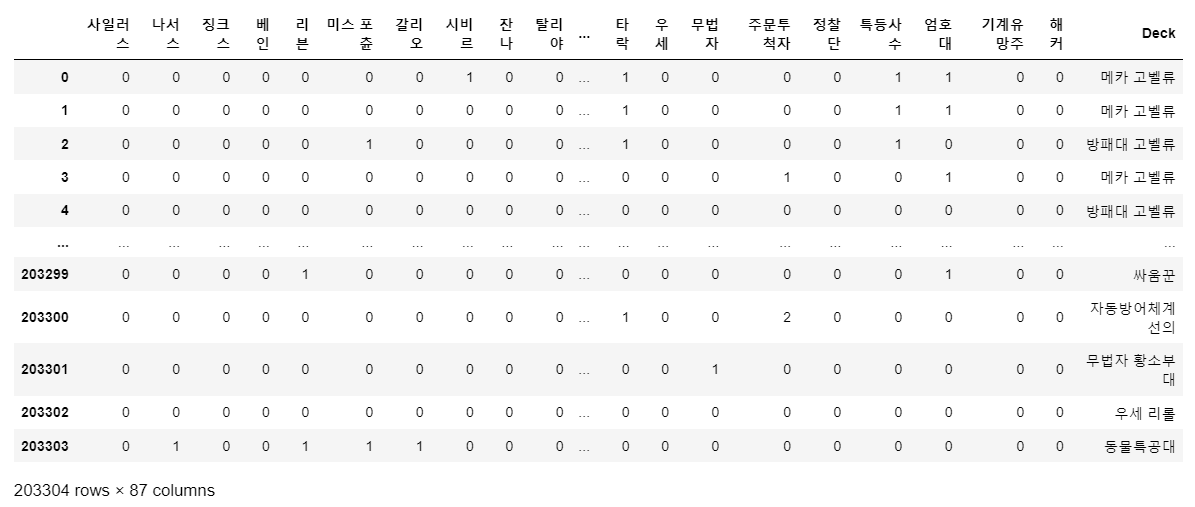
game_all_list = pd.DataFrame(game_all_list)
game_all_list['Deck'] = game_deck['Deck']
# 결과 출력
game_all_list
2. 덱 예측 모델링
이전 포스트에서 덱 별 특징을 정리했다. 따라서 EDA를 건너뛰고 바로 모델링을 진행하려 한다.
game_all_list의 column 중 챔피언 column(사일러스 ~ ), 특성 column(민간인 ~ 해커)를 explanatory variable로, Deck을 예측하는 것이 목표이다. 13개의 덱을 분류하는 classification 문제이다.
1) train test set 분리
현재 데이터에서 train set과 test set을 분리했다.
from sklearn.model_selection import train_test_split
X = game_all_list.drop('Deck', axis=1)
Y = game_all_list.Deck
train_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size=0.2)2) Dimension Reduction
지금 column의 수가 86개로 많은 편이라고 생각해서, 차원 축소를 진행해주었다. 클러스터링을 적용한 이전 포스트에서 svd를 적용했는데, svd와 pca는 사실 같은 방법임을 확인했다. (향후 svd와 pca에 대해 정리할 예정) 따라서 pca를 이용하여 차원 축소를 진행했다.
from sklearn.decomposition import PCA
pca = PCA(n_components = X.shape[1])
pca.fit(X)
scree_plot = px.line(
x = range(1, X.shape[1]+1),
y = pca.explained_variance_ratio_,
markers = True
)
scree_plot.update_layout(title = 'Scree Plot')
scree_plot.update_xaxes(title = 'nth components')
scree_plot.update_yaxes(title = 'explained variance ratio')
scree_plot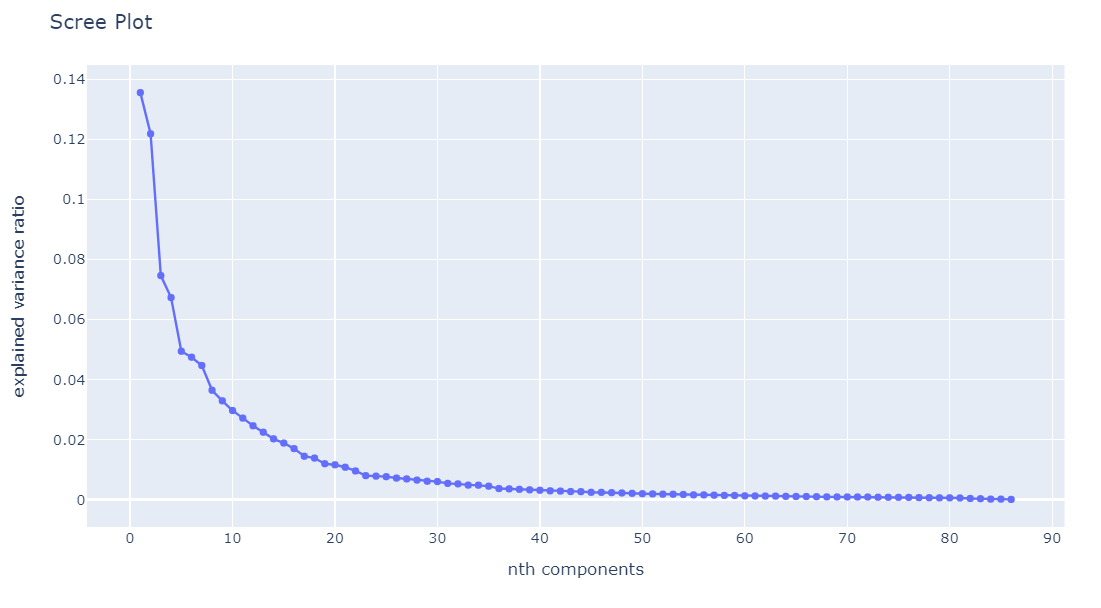
elbow point인 8개의 component를 선택, dimension을 8로 축소했다.
pca_changing = PCA(n_components = 8)
pca_changing.fit(train_X)
changed_x = pca_changing.fit_transform(train_X)
3) Multinomial logistic regression
먼저 multi class를 구분하는 가장 기본적인 모델인 multinomial logistic regression을 사용했다.
from sklearn.linear_model import LogisticRegression
train_Y_re = train_Y.reset_index(drop=True)
mnl_result = LogisticRegression(penalty = 'none', solver= 'sag').fit(X=changed_x, y=train_Y_re)
mnl_result.score(changed_x, train_Y_re)
해당 모델링 결과 train accuracy가 약 0.86이 나왔다.
(1) Confusion matrix
해당 모델을 이용하여 confusion matrix를 만들었다.
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
cm = confusion_matrix(train_Y_re, mnl_result.predict(changed_x), labels=mnl_result.classes_)
disp = ConfusionMatrixDisplay(confusion_matrix = cm, display_labels=mnl_result.classes_)
disp.plot()
fig = disp.figure_
fig.set_figwidth(20)
fig.set_figheight(20)
fig.suptitle('Plot of confusion matrix')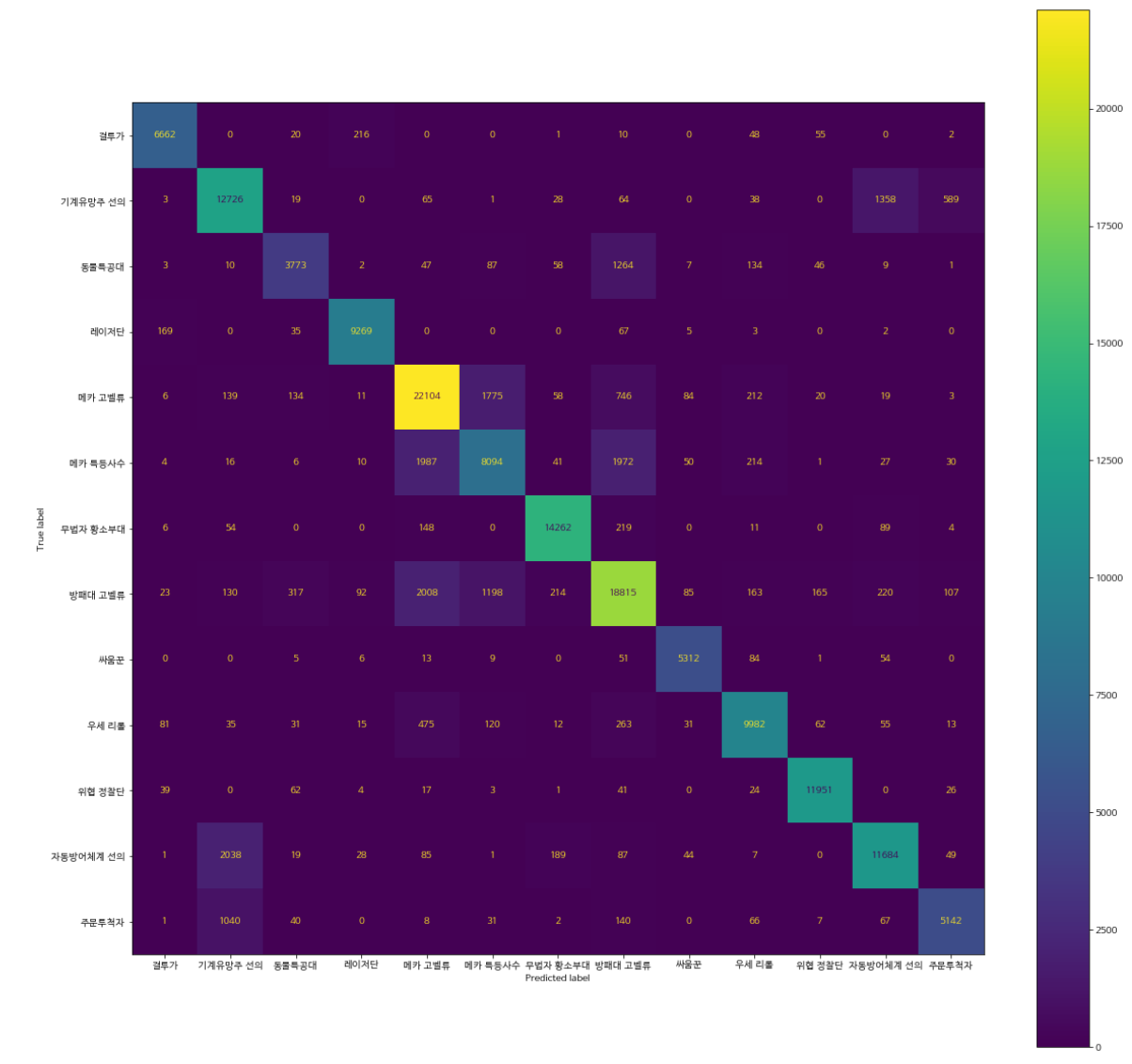
대부분 정확한 분류를 진행하지만, 다음 덱 간 약간의 오분류가 존재했다.
- 자동방어체계 선의, 기계유망주 선의, 주문투척자
- 메카 특등사수, 방패대 고벨류, 메카 고벨류
- 동물특공대, 방패대 고벨류
(2) test set 검증
해당 모델을 이용해서 test data를 예측하고, 결과를 살펴보았다.
# pca 축 변환
changed_test_x = pca_changing.fit_transform(test_X)
test_Y_re = test_Y.reset_index(drop=True)
mnl_result.score(changed_test_x, test_Y_re)test set에서의 accuracy는 약 0.85였다.
cm_test = confusion_matrix(test_Y_re, yhat)
disp_test = ConfusionMatrixDisplay(confusion_matrix = cm_test, display_labels = mnl_result.classes_)
fig_test = disp.figure_
fig_test.set_figwidth(20)
fig_test.set_figheight(20)
fig_test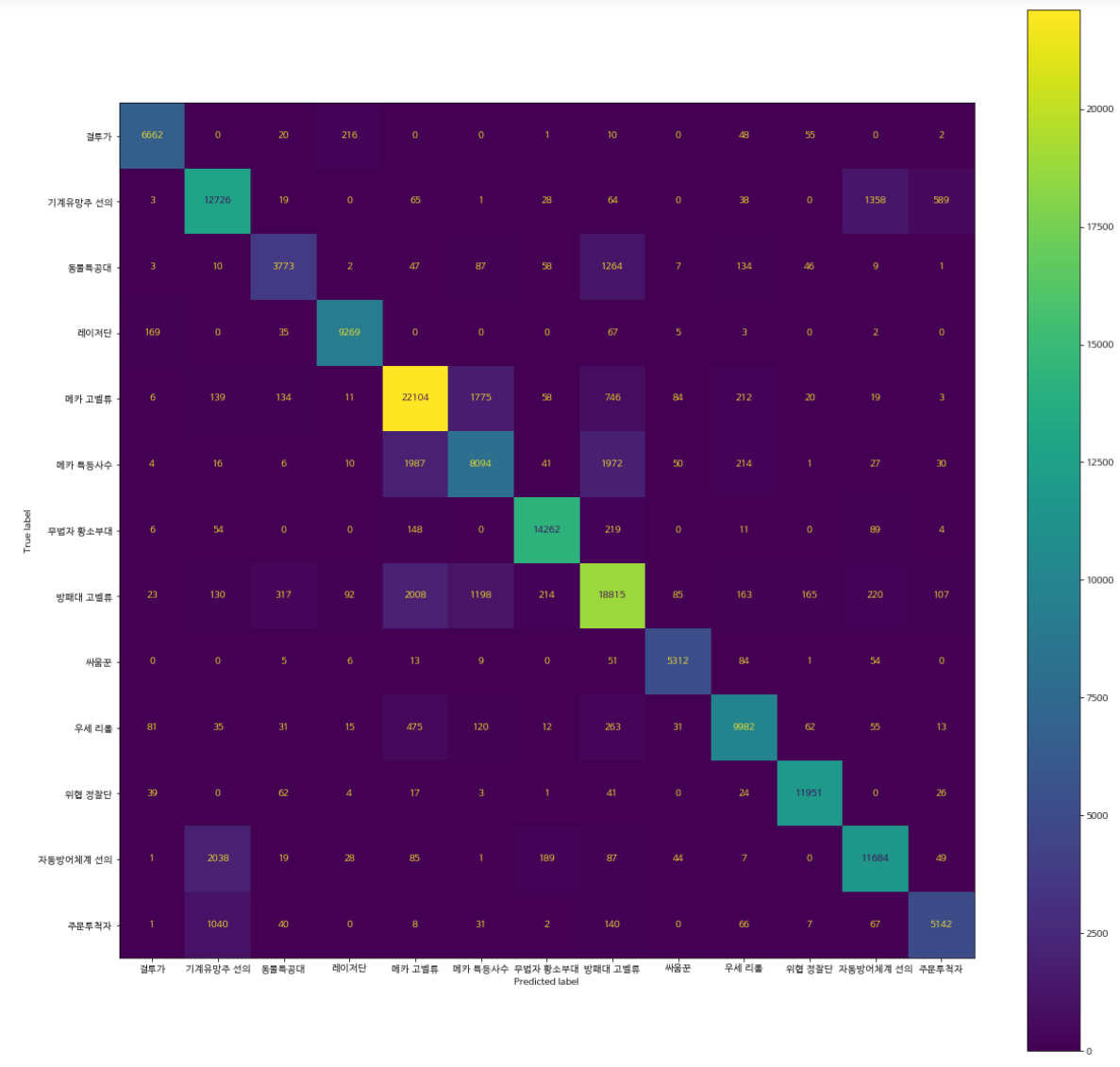
4) Random Forest
다음 모델로 random forest 모형을 이용하여 예측을 진행했다. Hyperparameter setting을 위해 grid search를 진행했다.
Grid search에 사용한 parameter는 다음과 같다.
- n_estimators : Tree의 수, 많을수록 정확성이 높아지나, 과적합의 위험과 시간 소요가 증가한다는 단점이 있다.
- min_samples_leaf : leaf 노드가 되기 위한 최소한의 데이터 수, 적을수록 과적합의 위험이 있다.
- min_samples_split : node가 확장되기 위한 최소한의 데이터 수, 적을수록 과적합의 위험이 있다.
다음과 같이 hyperparameter 값을 설정 후 grid search를 진행했다.
'n_estimators' : [10, 30, 50, 100],
'min_samples_leaf' : [1, 2, 4, 8, 12, 16],
'min_samples_split' : [2, 4, 8, 16]### gridsearchcv
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators' : [10, 30, 50, 100],
'min_samples_leaf' : [1, 2, 4, 8, 12, 16],
'min_samples_split' : [2, 4, 8, 16]
}
rf_clf = RandomForestClassifier(n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid= params, n_jobs = -1)
grid_cv.fit(changed_x, train_Y_re)
# 결과 추출
grid_cv.best_params_
- min_samples_leaf : 2
- min_samples_split : 2
- n_estimators : 100
해당 parameter를 이용하여 modeling을 진행했다.
rnf_best = RandomForestClassifier(min_samples_leaf = 2, min_samples_split = 2, n_estimators = 100)
rnf_best.fit(changed_x, train_Y_re)
rnf_best.score(changed_x, train_Y_re)
accuracy가 0.99로 높은 점수가 나왔다.
Test set에서 성능을 평가하고 confusion matrix를 그려보았다.
rnf_best.score(changed_test_x, test_Y_re)
yhat_rnf = rnf_best.predict(changed_test_x)
cm_test_rnf = confusion_matrix(test_Y_re, yhat_rnf)
disp_test_rnf = ConfusionMatrixDisplay(confusion_matrix = cm_test_rnf, display_labels = mnl_result.classes_)
disp_test_rnf.plot()
fig_test = disp_test_rnf.figure_
fig_test.set_figwidth(20)
fig_test.set_figheight(20)
fig_test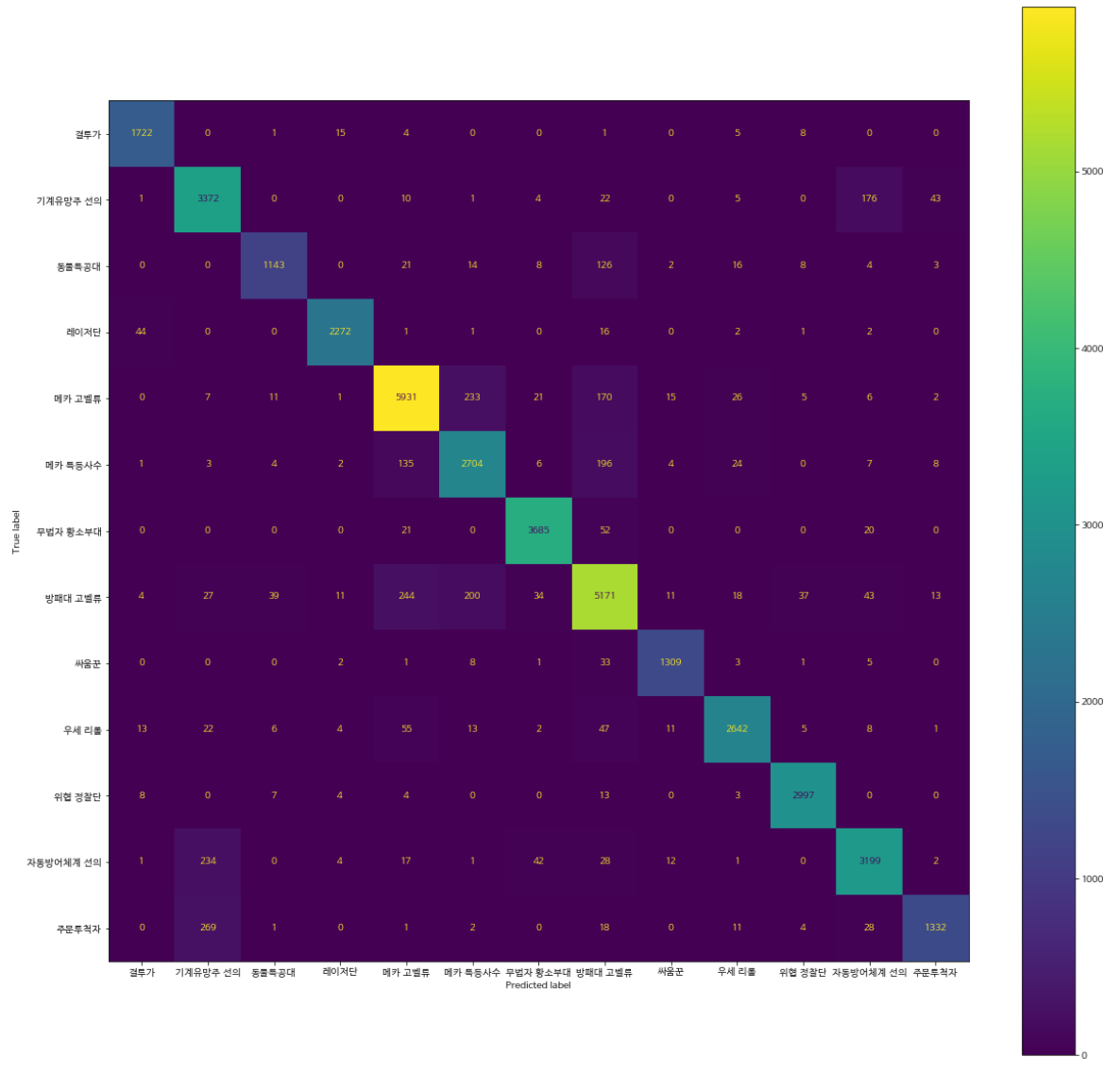
Accuracy는 0.92가 나왔다.
5) 추가 비교 모델
추가 비교 모델로 SVM와 XGBoost 모델을 사용해보았다. 다만, Randomforest 결과와 비교했을 때 성능지 좋지 않아 제외하였다.
6) Dimension 변환
앞선 모델링에서는 dimension을 8로 낮추어 모델링을 진행했다. 하지만 scree plot에서 elbow point가 22로도 생각해볼 수 있어서(22 이후 거의 감소가 되지 않는다.) 22로 dimension을 낮추어 모델링을 진행해보았다.
#random forest modeling
# pca
pca_changing_new = PCA(n_components = 22)
pca_changing_new.fit(train_X)
changed_x_new = pca_changing_new.fit_transform(train_X)
train_Y_re = train_Y.reset_index(drop=True)
# grid-search
params = {
'n_estimators' : [10, 30, 50, 100],
'min_samples_leaf' : [2, 4, 8, 12],
'min_samples_split' : [2, 4, 8, 16]
}
rf_clf = RandomForestClassifier(n_jobs=-1)
grid_cv = GridSearchCV(rf_clf, param_grid= params, n_jobs = -1)
grid_cv.fit(changed_x_new, train_Y_re)
grid_cv.best_params_
최적의 hyperparmeter로 n_estimators =100, min_samples_leaf = 2, min_samples_split = 4로 나왔다. 해당 hyperparameter를 이용하여 모델링을 진행했다.
ranf_best_22 = RandomForestClassifier(min_samples_leaf =2, min_samples_split = 4, n_estimators = 100)
ranf_best_22.fit(changed_x_new, train_Y_re)
ranf_best_22.score(changed_x_new, train_Y_re)
적합 결과 accuracy가 0.9997이 나왔다.
test set에 적용했을 때 accuracy는 다음과 같이 나왔다.
changed_test_x_new = pca_changing_new.fit_transform(test_X)
test_Y_re = test_Y.reset_index(drop=True)
rnf_yhat_22 = ranf_best_22.predict(changed_test_x_new)
ranf_best_22.score(changed_test_x_new, rnf_yhat_22)
Accuracy가 1이 나왔다. 즉, 모든 정답을 다 맞추었다는 의미이다. (해당 블로그에는 정리하지 않았지만, 해당 모델보다 성능이 좋은 모델이 없었다.)
따라서 최종 모델은 PCA를 통해 22개의 dimension을 축소한 후, random forest를 진행한 모델로 선정했다.
전체 데이터를 이용하여 random forest 모델을 fitting한 뒤, 모델을 저장을 해주었다.
joblib.dump(final_pca, 'pca_result.pkl')
joblib.dump(final_rf, 'rf_result.pkl')
