이전 포스트
에서 이어지는 포스트이다.
1. Modeling
이전 포스트에서 EDA를 통해 얻은 특징을 바탕으로 모델링을 시작했다.
1) Sparse and high dimensional data
데이터프레임 element 내부에 0이 많고 column의 수도 59개로 적지 않은 편이다. 이를 해결하기 위한 방법으로 SVD (Singular Value Decomposition)을 이용하기로 했다.
(1) Singular Value Decomposition
Matrix 를 3개의 matrix 로 분해하는 방법이다. 이 때 는 diagonal entry에 0 또는 양의 정수를 갖고, 나머지 entry는 0의 값을 가지는 matrix이다. 가 matrix일 때,3개의 matrix의 size는 다음과 같다.
를 다음과 같이 작성하면
(여기서 는 sigular value를 diagonal entry 값으로 하는 square matrix이다. 개의 singular value 에 대해
는 다음과 같이 작성 가능하다.
해당 방법으로 분해되는 이유는 다음 포스트를 참고하길 바란다.
여기서, 만약 의 값이 충분히 작다면, 식에서 항을 제외해도 와 근사해질 것이다. 이를 이용하여 차원을 축소시키는 방법이 Singular value decomposition이다.
또한, 의 각 column은 의 linear combination으로 표현된다. 즉, 이 를 표현하는 새로운 basis가 된다. 즉 basis를 변경시켜 sparse 데이터를 다른 형태(0이 많지 않은 형태)로 변환하여, sparsity 문제도 해결할 수 있다.
(2) SVD with python
Python에서는 pytorch를 이용하여 svd를 진행할 수 있다. (scipy, numpy 통해서도 svd를 진행할 수 있지만, data size의 제한이 있다.)
check = np.array(game_champ_list).astype(float)
check = torch.tensor(check)
svd_u, svd_s, svd_v = torch.svd(check)
여기서 svd_s가 singular value에 해당하는 값이고, 크기 순으로 sort되어 있다. 여기서 singular value가 작은 경우 제외하면 된다. singular value를 몇 개를 남겨야하는지 확인하는 방법이 condition number와 scree plot이다.
Condition Number
Singular value를 singular value의 합으로 나눈 후, cummulative sum한 값이다. 번째 singular value까지의 합이 전체 singular value 합에서 차지하는 비중을 나타내며, singular value가 추가되었을 때 이전 condition number와 차이가 없거나, condition number가 특정 값을 넘길 때 까지의 singular value를 사용하고, 이 후 condition number는 사용하지 않는 방법으로 차원을 축소시킬 수 있다.
condition_number = svd_s/torch.sum(svd_s)
condition_number = condition_number.numpy()
condition_number_ex = []
for i in range(len(condition_number)):
condition_number_ex.append(sum(condition_number[:i+1]))
scree_ploting=pd.DataFrame(dict(number = range(1, len(condition_number)+1), condition_number = condition_number_ex))
scree_plot = px.line(data_frame = scree_ploting, x='number', y='condition_number', markers=True)
scree_plot.update_layout(title = 'Scree plot')
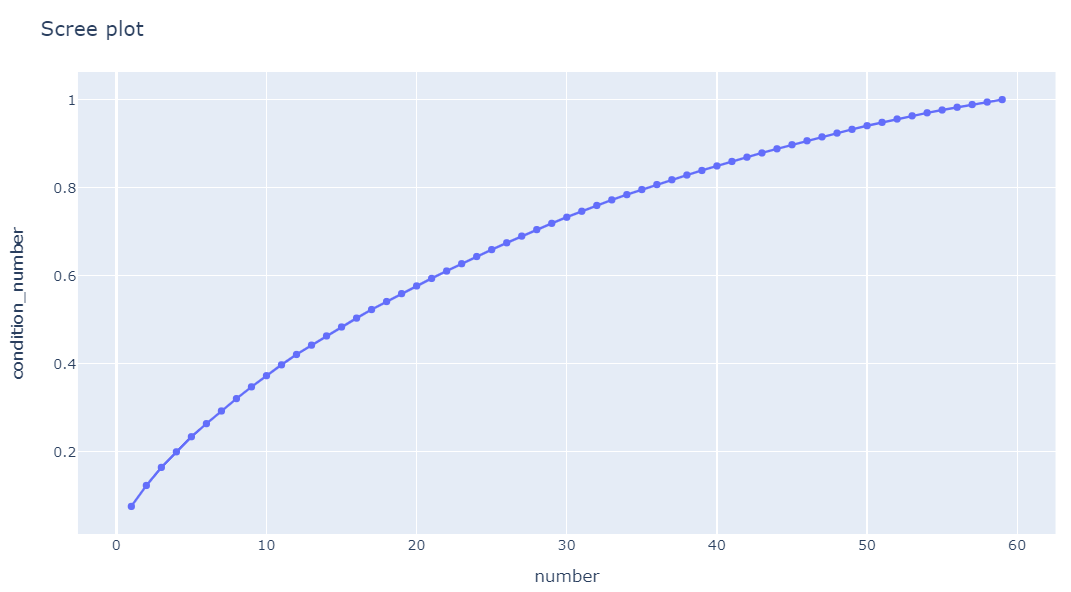
감소율이 급감하는 지점이 없어(= elbow point가 없어) condition number가 0.8을 넘기 전인 지점인 36을 선택, dimension을 59에서 36으로 감소시켰다.
changed_value = pd.DataFrame(svd_u.numpy()).iloc[:, :36]
2) Clustering - K-means clustering
Clustering 방법론 중 대표적인 방법론 중 하나인 K-means clustering을 적용했다. K개의 클러스터에 대해서 클러스터 point에서 클러스터에 속한 데이터까지의 거리 합이 최소가 되도록 클러스터를 구성하는 방법이다. 이 때 클러스터 point는 클러스터에 속한 데이터들의 평균값이다.
거리 지표는 Euclidean mean을 사용했고, 클러스터 수 K는 2에서 30으로 설정하고, within sum of square의 추세를 보고 판단했다.
from sklearn.cluster import KMeans
check = []
for i in range(2, 30):
kmeans = KMeans(n_clusters=i, random_state=15).fit(changed_value)
check.append(kmeans.inertia_)
find_k = px.line(x= range(2, 20), y=check, markers=True)
find_k
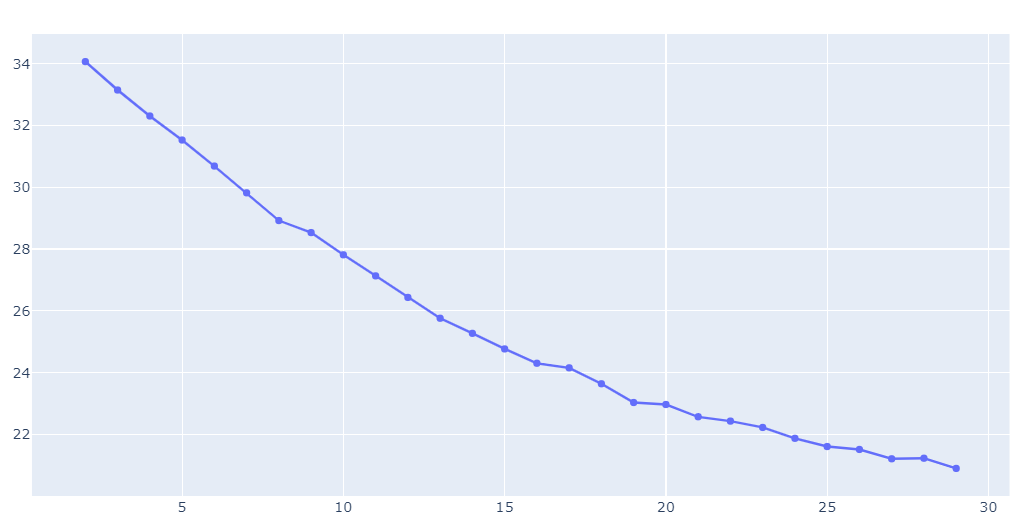
K=8 이후 감소하는 기울기가 낮아져, cluster의 수를 8개로 정했다. 즉, K-means clustering으로 분류한 덱이 8개가 존재한다는 뜻이다.
클러스터 별에 속한 플레이어가 사용한 챔피언 수를 count하는 dataframe을 만들었다.
from functools import reduce
kmeans = KMeans(n_clusters=8).fit(changed_value)
cluster_check = {'cluster' + str(i+1) : game_champ_list[kmeans.labels_==i] for i in range(8)}
cluster_count = {'cluster' + str(i+1) : pd.DataFrame(cluster_check['cluster'+str(i+1)].apply(sum, 0)) for i in range(8)}
for i in cluster_count.keys():
cluster_count[i]['champ'] = cluster_count[i].index
cluster_count[i] = cluster_count[i].reset_index(drop=True)
cluster_count[i].columns = [i, 'champ']
cluster_result = [cluster_count[i] for i in cluster_count.keys()]
result = reduce(lambda x, y : pd.merge(x, y, on='champ'), cluster_result)
result = result[['champ']+ [f'cluster{i+1}' for i in range(8)]]
result
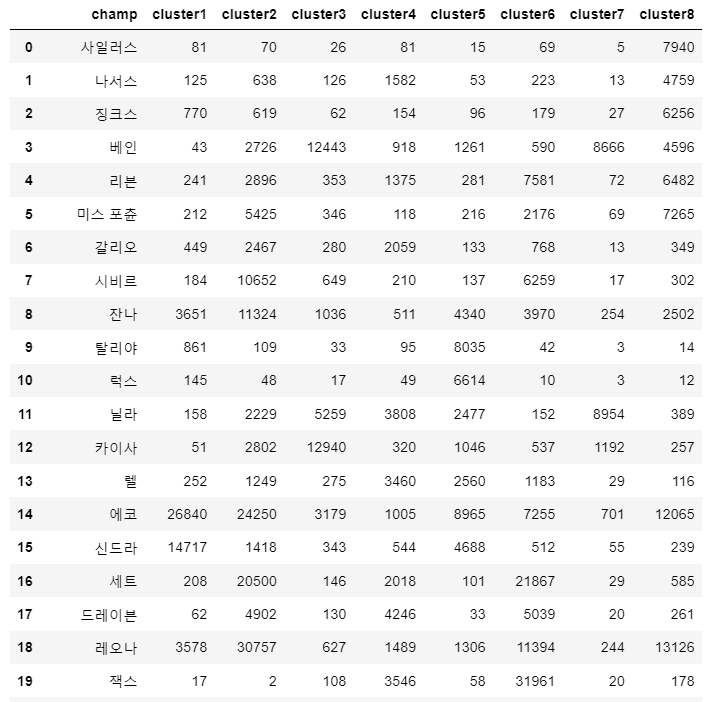
각각의 클러스터별로 count가 많은 순으로 나열해 많이 사용한 챔피언을 확인했다.
result.sort_values('cluster1', ascending=False).reset_index(drop=True).head(10)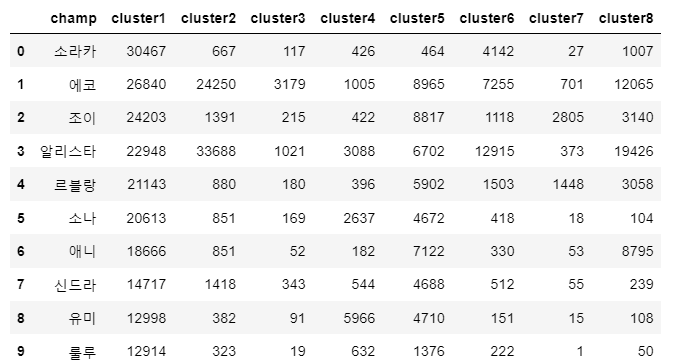
가장 많이 사용한 챔피언을 정리하면 다음과 같다.
-
Cluster 1 : 소라카, 에코, 조이, 알리스타, 르블랑, 소나, 애니, 신드라
-
Cluster 2 : 알리스타, 피들스틱, 레오나, 우르곳, 사미라, 아펠리오스
-
Cluster 3 : 람머스, 초가스, 카이사, 베인, 자크, 이즈리얼, 벨베스
-
Cluster 4 : 말파이트, 갱플랭크, 리신, 유미, 드레이븐, 오공, 닐라, 잭스
-
Cluster 5 : 세주아니, 제드, 야스오, 레넥톤, 세나, 모데카이저
-
Cluster 6 : 잭스, 세트, 오공, 사미라, 피들스틱, 우르곳, 알리스타, 레오나
-
Cluster 7 : 닐라, 베인, 야스오, 제드, 피오라, 갱플랭크, 세주아니
-
Cluster 8 : 비에고, 알리스타, 탈론, 레오나, 에코, 피들스틱, 아펠리오스
데이터를 통해 클러스터링한 결과에서 시즌 8 때 많이 사용한 덱이 많이 나왔다. Cluster별로 정리하면 다음과 같다.
-
Cluster 1 : 선의 소라카
-
Cluster 2 : 방패대 특등사수
-
Cluster 3 : 위협 정찰단
-
Cluster 4 : 우세 리롤
-
Cluster 5 : 레이저단
-
Cluster 6 : 세트 사미라
-
Cluster 7 : 결투가
-
Cluster 8 : 무법자 황소부대
하지만 완벽하게 클러스터링이 되었다고 말하긴 힘들었다. 그 이유를 몇 가지 꼽으면
-
우세 리롤 덱의 경우 우세 챔피언은 탱커 + 시너지 용이고 핵심 딜러는 따로 있는데, 이를 분류해내지 못했다. (유미와 드레이븐이 동시에 쓰였다.)
-
Cluster 1에 두 가지 덱이 존재한다. - 주문투척자 탈리야와 선의 소라카.
-
메인 덱 중 하나인 동물 특공대가 분류되지 않았다.
Cluster 수를 줄이거나, 늘려도 비슷한 결과를 얻을 수 있었다. 따라서 챔피언만 이용해서는 완벽한 결과를 얻긴 힘듦을 알 수 있다.
따라서, 챔피언 뿐만 아니라, 해당 플레이어 사용한 특성 또한 column에 추가했을 때 결과가 어떻게 변하는지 확인해보기로 했다.
3) 특성 변수 추가 후 modeling
game_champ_list에서 특성 변수를 추가한 데이터프레임을 game_all_list로 지정했다. 이 때, 특성 개수만큼의 column이 추가되었고, 해당 플레이어가 사용한 특성의 티어가 element이다.
trait=['민간인', '자동방어체계', '동물특공대', '레이저단', '싸움꾼', '메카:프라임', '위협',
'마스코트', '기상캐스터', '에이스', '결투가', '황소부대', '병기고', '방패대',
'지하세계', '별 수호자', '익살꾼', '선의', '타락', '우세', '무법자', '주문투척자',
'정찰단', '특등사수', '엄호대', '기계유망주', '해커']
game_all_list = {i : [0]*game_summary.shape[0] for i in summary_all['champion'].keys()}
for i in trait:
game_all_list[i] = [0]*game_summary.shape[0]
for i in range(len(game_summary['units'])):
try:
units = eval(game_summary['units'][i])
for unit in units:
game_all_list[unit][i] +=1
traits= eval(game_summary['traits'][i])
trait_tier = eval(game_summary['tier_current'][i])
if len(traits)==0:
pass
else:
for j in range(len(traits)):
game_all_list[traits[j]][i] += trait_tier[j]
except:
print(i)
game_all_list = pd.DataFrame(game_all_list)
# 결과 확인
game_all_list
마찬가지로 해당 데이터 또한 sparse and high dimensional data이므로, svd를 통해 차원 축소 및 basis 변환을 진행했다.
# svd 진행
check_all = np.array(game_all_list).astype(float)
check_all = torch.tensor(check_all)
svd_u_all, svd_s_all, svd_v_all = torch.svd(check_all)
condition_number_all = svd_s_all/torch.sum(svd_s_all)
condition_number_all = condition_number_all.numpy()
condition_number_all_ex = []
for i in range(len(condition_number_all)):
condition_number_all_ex.append(sum(condition_number_all[:i+1]))
scree_plot_all = px.line(x=range(1, 95), y=condition_number_all_ex, markers=True)
scree_plot_all.update_xaxes(title = 'singular value number')
scree_plot_all.update_yaxes(title = 'condition number')
scree_plot_all.update_layout(title = 'Scree plot')
scree_plot_all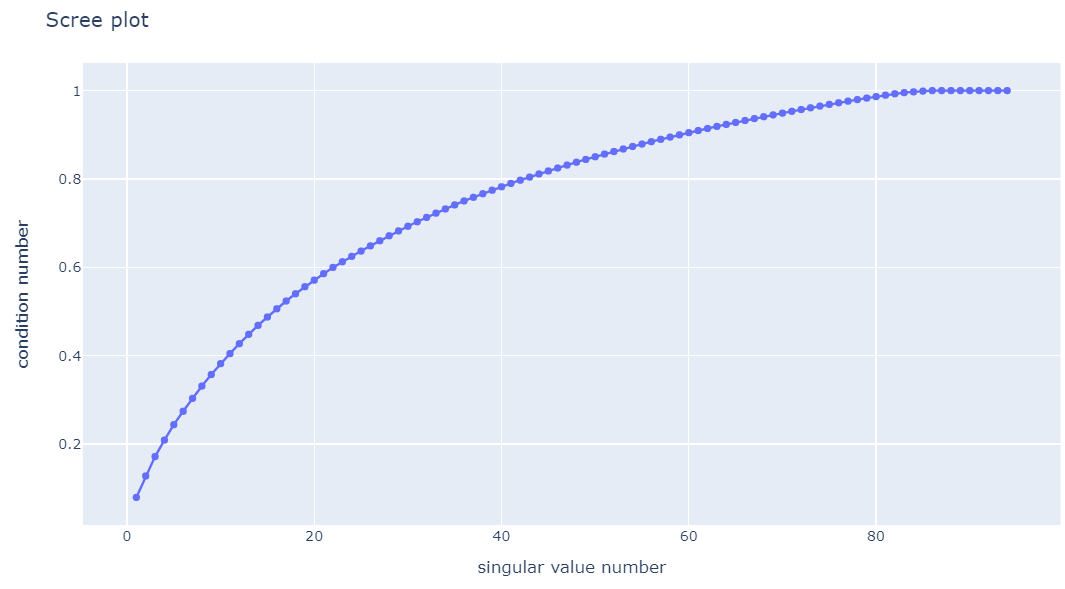
22번 째 singular value 이 후 증가하는 속도가 느려져, 차원을 22로 축소했다.
changed_value_all = pd.DataFrame(svd_u_all.numpy()).iloc[:, :22]
check_all = []
for i in range(2, 30):
kmeans = KMeans(n_clusters=i).fit(changed_value_all)
check_all.append(kmeans.inertia_)
find_k_all = px.line(x= range(2, 30), y=check_all, markers=True)
find_k_all
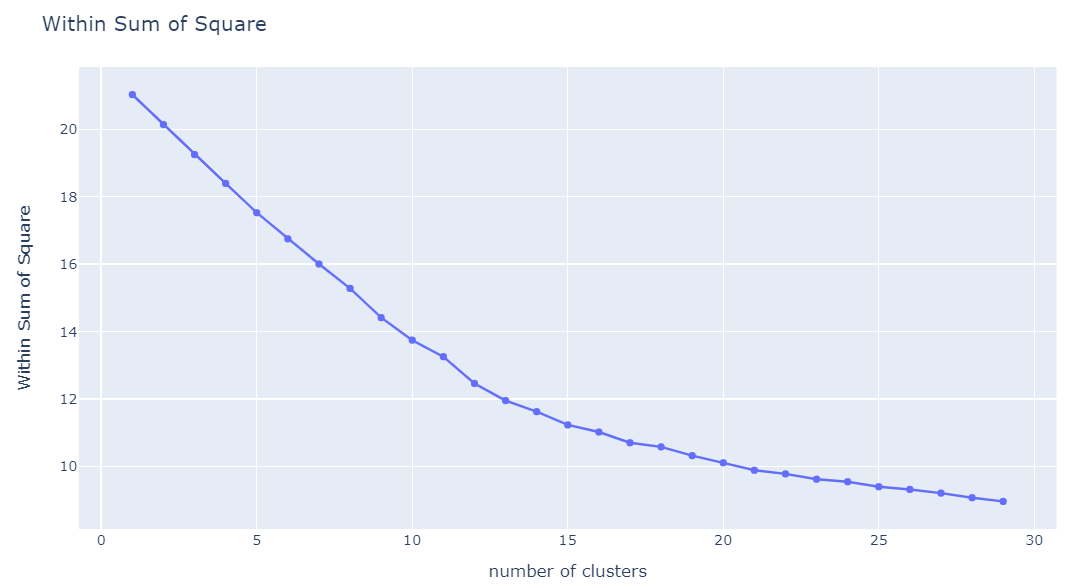
너무 일자로 떨어져서, 확인하기가 힘들었다. 12 이후 기울기가 절댓값이 감소해서 K : 11, 12, 13을 선택하여 확인했다. 그 중 덱 분류가 잘 된 K=13일 때의 결과를 아래에 작성했다.
kmeans_all = KMeans(n_clusters=12).fit(changed_value_all)
cluster_check_all = {'cluster' + str(i+1) : game_all_list[kmeans_all.labels_==i] for i in range(12)}
cluster_count_all = {'cluster' + str(i+1) : pd.DataFrame(cluster_check_all['cluster'+str(i+1)].apply(sum, 0)) for i in range(12)}
for i in cluster_count_all.keys():
cluster_count_all[i]['champ'] = cluster_count_all[i].index
cluster_count_all[i] = cluster_count_all[i].reset_index(drop=True)
cluster_count_all[i].columns = [i, 'champ']
cluster_result_all = [cluster_count_all[i] for i in cluster_count_all.keys()]
result_all = reduce(lambda x, y : pd.merge(x, y, on='champ'), cluster_result_all)
result_all = result_all[['champ']+ [f'cluster{i+1}' for i in range(12)]]
result_all
클러스터에 속하는 주요 챔피언은 다음과 같다.
-
cluster 1 : 카이사, 베인, 이즈리얼, 람머스, 초가스, 애쉬, 닐라, 자크
-
cluster 2 : 세주아니, 잭스, 바이, 리신, 리븐, 블리츠크랭크, 소라카, 레넥톤
-
cluster 3 : 세주아니, 제드, 야스오, 레넥톤, 세나, 모데카이저, 조이, 애쉬
-
cluster 4 : 피들스틱, 우르곳, 알리스타, 에코, 레오나, 자크, 벨베스, 아펠리오스
-
cluster 5 : 시비르, 사미라, 알리스타, 세트, 오공, 피들스틱, 우르곳, 레오나
-
cluster 6 : 소라카, 르블랑, 에코, 블리츠크랭크, 소나, 조이, 알리스타, 카밀
-
cluster 7 : 세트, 오공, 레오나, 피들스틱, 알리스타, 우르곳, 아펠리오스, 잭스 , 사미라
-
cluster 8 : 탈리야, 에코, 애니, 알리스타, 럭스, 소나, 신드라, 유미
-
cluster 9 : 비에고, 탈론, 알리스타, 레오나, 아펠리오스, 피들스틱
-
cluster 10 : 애니, 조이, 알리스타, 에코, 룰루, 소라카, 소나, 누누와 윌럼프
-
cluster 11 : 리븐, 징크스, 미스 포츈, 에코, 베인, 나서스, 알리스타
-
cluster 12 : 말파이트, 리신, 갱플랭크, 유미, 드레이븐, 오공
-
cluster 13 : 야스오, 닐라, 베인, 제드, 피오라, 갱플랭크, 세주아니, 케일
클러스터에 속하는 주요 특성은 다음과 같다.
-
cluster 1 : 정찰단, 위협, 결투가, 별수호자
-
cluster 2 : 싸움꾼, 자동방어체계, 선의, 위협
-
cluster 3 : 레이저단, 결투가, 싸움꾼, 해커
-
cluster 4 : 방패대, 위협, 에이스, 타락, 병기고
-
cluster 5 : 민간인, 특등사수, 방패대, 위협, 에이스, 메카:프라임
-
cluster 6 : 자동방어체계, 선의, 주문투척자, 헤커
-
cluster 7 : 메카:프라임, 엄호대, 방패대, 위협, 에이스
-
cluster 8 : 주문투척자, 별수호자, 방패대, 선의
-
cluster 9 : 황소부대, 무법자, 방패대, 자동방어체계, 위협
-
cluster 10 : 기계유망주, 선의, 익살꾼, 주문투척자
-
cluster 11 : 동물특공대, 익살꾼, 에이스, 방패대
-
cluster 12 : 우세, 마스코트, 선의, 싸움꾼
-
cluster 13 : 결투가, 헤커, 레이저단, 위협
해당 정보를 바탕으로 cluster별 네이밍을 진행했다.
-
cluster 1 : 위협 정찰단
-
cluster 2 : 싸움꾼
-
cluster 3 : 레이저단
-
cluster 4 : 방패대 고벨류
-
cluster 5 : 메카 특등사수
-
cluster 6 : 자동방어체계 선의
-
cluster 7 : 메카 고벨류
-
cluster 8 : 주문투척자
-
cluster 9 : 무법자 황소부대
-
cluster 10 : 기계유망주 선의
-
cluster 11 : 동물특공대
-
cluster 12 : 우세
-
cluster 13 : 결투가
13개의 덱 리스트를 game_summary에 추가해주었다.
deck_list= ['탈리야 주문투척자', '무법자 비에고', '선의 소라카', '레이저단', '싸움꾼 소라카', '우세 이즈리얼', '황소부대 비에고', '카베람초', '기계유망주 선의', '위협', '메카 특등사수 벨류', '세트 사미라', '우세 드레이븐', '동물특공대', '우세 별수호자', '민간인 마스코트', '방패대 특등사수', '4에이스', '결투가 헤커']
deck_result = [deck_list[kmeans_all.labels_[i]] for i in range(len(kmeans_all.labels_))]
game_summary['Deck'] = deck_result
# 결과 확인
game_summary

game_summary에 덱이 추가된 것을 확인할 수 있다.
다음 포스트에서는 추가된 덱 리스트를 기반으로 덱 별 특징을 정리하려고 한다. (13개의 클러스터 정리...)
