
1. Introduction
최근의 진보들으로는 raw sensory data에서 high-level feature들을 추출해 낼 수 있었고, 이는 computer vision, speech recognition 분야에서 획기적인 발견을 이끌었다. 이러한 방법들은 CNN, Multilayer perceptrons, restricted Boltzmann machines, RNN, 지도학습 및 비지도학습 등을 포함한다.
그런데, RL 분야는 몇 가지 문제에 부딪혔다.
- 대부분의 딥러닝 모델들은 많은 훈련 데이터들로 학습을 하지만, RL의 경우에는 scalar 보상을 통해서만 배울 수 있다.
- 대부분의 딥러닝 모델들은 서로 연관되어 있지 않은 데이터 샘플들이라고 가정하지만, RL의 경우에는 샘플들의 수열이 높게 연관되어 있다.
- RL에서 알고리즘이 새로운 행동을 학습하면서 데이터 분포가 변하는데 이는 고정된 분포를 가정하는 방법에 대해 문제가 될 수 있다.
이 논문에서는 CNN이 복잡한 RL 환경에서 성공적으로 학습할 수 있음을 보였으며, 다양한 Q-learning 알고리즘, SGD를 사용했다. 상호연관된 데이터와 변하는 분포의 문제를 경감시키기 위해서 무작위로 이전 상태를 보여주는 experience replay mechanism을 사용해서 훈련 분포를 부드럽게 했다.
특별한 정보 제공 없이 진행됐으며 사람이 하듯이 정보를 받았다. 그렇게 해서 좋은 결과를 거두었다.
2. Background
아타리 시뮬레이터 환경에서 sequence of actions, observations, rewards를 확인하고, 각 상황에서 가능한 at를 선택한다. 관측은 오직 emulator의 image xt에서만 관측되며, 이는 현 스크린의 벡터 값을 나타낸다. 이렇게 선택된 결과를 통해서 결과 값 rt가 나오게 되며, 이러한 과정이 반복된다.
이 때, xt만 확인하게 되면 task가 부분적으로만 관찰되기 떄문에 현 상황을 완전히 이해하는 것은 불가능하다. 따라서, st = x1, a1, x2, a2, … a(t-1), xt라는 수열을 통해서 게임 전략을 배운다. 이러한 형식은 유한한 마르코프 결정 과정(MDP)를 야기하며, MDP를 위한 RL 학습법을 사용할 수 있따.
이 agent의 목적은 미래의 reward를 최대화하는 action들의 수열을 찾는 것이다. 한 회마다 리턴 값이 r의 비율로 감소한다고 가정했고, 가능한 최대 T, 현재 시간 t에서 식을 아래와 같이 얻었다.
또한, optimal action-value function 을 아래와 같이 정의했다. 여기서, 특정한 수열 s, 행동 a, 규칙 pi를 가정했다. 이 함수는 Bellman Equation을 따른다고 한다.
**** 차후에 Q function에 관련된 내용은 더 추가할 예정입니다.
이 Rt를 풀어서 다음 항부터 r로 다시 묶어서 쓰면 아래와 같이 쓸 수 있다.
여기서 s, a를 각각 변경된 s’, a’으로 작성하게 되면 Q 함수를 아래처럼 다시 쓸 수 있게 된다.
이렇게 되면 수렴성은 확실하게 보일 수 있지만, 일반화되지 않아서 굉장히 비실용적이다. 따라서 NN과 같이 가중치를 통해서 Loss를 계산하고, 이를 최소화하는 방향으로 계산을 진행하려고 했다. 그래서 아래와 같이 각 반복 i에 대해서 Loss를 계산했다.
여기서 rho(s,a)는 behavior distribution 으로 수열 s와 행동 a에 대한 확률분포이다. 기존의 supervised learning에서 정해진 상태에서 계산을 했지만, 여기서는 반대로 진행된다. 위 loss function을 theta_i에 대해 편미분해서 최소화하는 방향으로 SGD를 적용하면 된다. 이 Q-learning은 model-free이며 off-policy이다.
3. Related Work
backgammon 이라는 게임에서 기존에 Q-learning이 적용되었다. 하지만 이 방법은 체스, 바둑, 체커에서는 비효율적이었고, 이는 backgammon이 주사위를 돌려서 하는 게임이다 보니까 특별하게 작용한 것으로 추측한다.
게다가 비선형 함수 approximator로 Q-learning 을 진행하거나, off-policy learning은 Q-network 가 발산하게 만들 수 있기 때문에 대부분의 연구는 선형 함수 approximator가 수렴한다는 보장을 갖게 하는 것에 집중되어 있다.
최근에는 deep learning과 rl을 결합해서 Q-learning 의 발산 문제를 gradient temporal-difference라는 방법을 통해서 해결하고 있다.
NFQ(Neural fitted Q-learning)은 Loss function을 최적화하며, RPROP 알고리즘을 사용해서 parameter들을 업데이트한다. 그러나 계산 수가 많기 때문에 SGD를 고려한다. 먼저 deep autoencoder로 task의 representation을 익히고 NFQ를 적용한다.
이 모델에서는 대조적으로 입력에서 출력까지 visual input으로 부터 직접적으로 받아서 한 번에 처리했는데(end-to-end), 이는 action-value를 구분하는 것과 직접적으로 관련된 특징을 학습할 수 있다.
Restricted boltzmann machine
generative model로, gan과 비슷한 계열이다. 일리있는 확률밀도함수 학습하여 이를 sampling 하는 것이다.
4. Deep Reinforcement Learning
최근 컴퓨터 비전과 음성 인식 분야의 돌파구들은 거대한 training set을 사용하는 효율적인 DNN에 의존해왔다. 이러한 성공적인 접근들은 최초 input에서 바로 훈련되었으며, SGD를 통한 가중치 업데이트를 이용했고, 이에 영감을 받아서 RL 알고리즘을 DNN과 연결시켜서 RGB 이미지에서 바로 학습하게 하고, 확률적 경사 업데이트를 통해서 데이터를 효율적으로 훈련시키는 목표를 갖는다.
기존에 수열을 통해서 backgammon의 모델의 구조를 만들어냈을 때로부터 20년이 흘렀기 때문에, 그 동안 있었던 하드웨어의 발전을 통해서 조금 더 좋은 결과를 낼 수 있을 것이라고 생각한다.
데이터셋에 각 시간마다 agent의 경험을 저장할 수 있는 experience replay 라는 기술을 이용했다. 저장된 샘플들 사이로부터 랜덤하게 Q-learning, minibatch update를 진행했다. 이후에 e-greedy policy를 적용했다. 임의의 길이가 들어오는 것은 어려울 수 있기 떄문에, Q 함수는 함수 phi에서 생산된 고정된 길이의 표현만을 사용했다.
DQN Algorithm

일반적인 Q-learning 에 비해서 여러가지 장점이 있다.
- 각 step에서 많은 weight update 가 이루어지므로, 데이터 효율이 늘어난다.
- 연결된 샘플들의 강한 관련 때문에 연속적인 샘플들을 훈련하는 것은 비효율적이므로, 무작위로 샘플을 뽑는 것은 업데이트의 분산을 감소시킨다.
- 기존의 경우에는 연속적으로 훈련이 진행되었기 때문에, 이전 결과가 바뀌면 그에 따라서 이후 훈련 분포가 전부 바뀌게 되어 극소값에 빠지거나, 발산할 수 있었다. 하지만, experience replay를 사용하면 진동이나, 값의 발산을 막을 수 있다.
N개의 experience memory를 사용했고, 이보다 더 나오는 경우에는 덮어썼다.
4.1 Preprocessing and Model Architecture
직접 아타리 게임기로 작업을 하게되면 계산량이 너무 많아지기 때문에 preprocessing을 통해서 계산량을 줄이려고 했다. 크기를 중요한 부분만 잘라서 얻고, 흑백으로 만들어서 이 문제를 해결했다. 이는 오류의 정도를 줄이고, 조금 더 다른 게임들이 익히기 쉽게 만들었지만, 점수 크기를 다르게 할 수 없어서 성능에 영향을 미칠 수 있다.
Q는 history와 action이 값에 영향을 미쳐서 input으로 사용되ㅆ지만, 이 구조는 action의 개수에 비례해서 계산이 적용되어야 하기 때문에 상당히 계산이 늘어난다는 점이다. 그래서 output이 action에 따라서 여러 개로 나오고, input은 현재 state 하나만 집어넣게끔 구조를 설정했다. 이러한 구조는 단순히 하나의 길만으로도 가능한 모든 action을 계산할 수 있다는 능력이다.
그래서 전체적인 구조는 84844의 초기 이미지, 첫 번째 hidden layer 16 88 filters w/ stride 4 with nonlinear function, 2nd hidden layer 32 4 4 w/ stride 2 w/ nonlinear function, final hidden layer FCNN w/ 256 units, 그리고 가능한 action의 개수는 게임에 따라서 4 ~ 18개이다. 우리는 이 구조를 DQN으로 부르기로 했다.
5. Experiments
Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders의 7개의 게임으로 실험을 진행했다. 이 실험을 통해서 특별한 게임에 대한 팁 없이도 다양하게 좋은 결과를 낼 수 있다는 것을 보였다. 바꾼 것은, 게임마다 점수 체계가 다양하기 때문에 점수 추가는 1, 변화 없음은 0, 점수 감소는 -1로 표현했다.
5.1 Training and Stability
supervised learning 에서는 model의 성능을 확인하기 쉽지만, RL 모델에서는 그렇지 않다. 그래서 모델에서 얻은 보상들의 총합을 주기적으로 계산해서 성능으로 표현했지만, 이는 noisy하다. 왜냐하면 policy의 가중치의 작은 변화가 해당 policy가 마주하는 경우에서 상당히 다른 분포를 가져올 수 있기 때문이다.
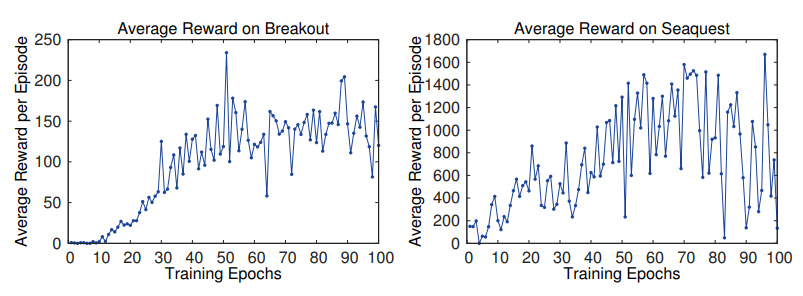
실제로 위 그래프에서 훈련 횟수는 많이 변하지 않았음에도 policy가 조금씩 바뀌면서 noise가 크게 벌어지는 것을 알 수 있다. 그리고 이는 점진적인 발전을 하지 않는 것처럼 보일 수 있기 때문에 아래와 같이 Q function을 활용한 기댓값의 그래프를 만들었다.
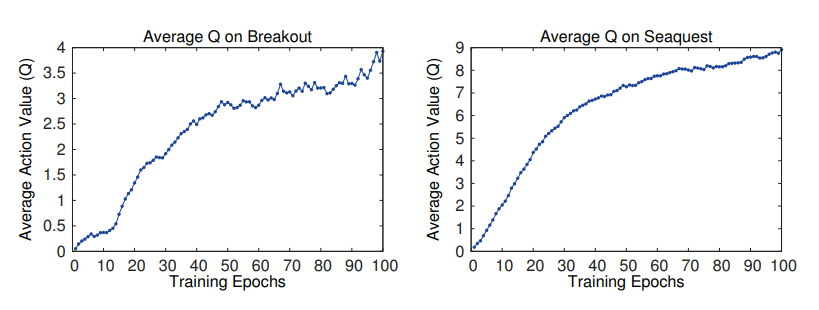
그리고 위 Q 함수를 학습하면서 어떠한 발산 문제를 겪지 않았으며, 이는 이론적으로 수렴성의 보장이 없더라도 DNN을 RL과 SGD를 통해서 학습하는 방법이 안정적임을 보인다.
5.2 Visualizing the Value Function

value function을 시각화해서, 적이 나나타는 A에서는 함수가 올라가고, 적이 어뢰를 발사한 B에서는 최고점을 찍었으며, 적이 지나간 후에는 다시 원래대로 C와 같이 돌아왔다. 일련의 복잡한 사건들을 잘 학습하는 것을 확인할 수 있다.
5.3 Main Evaluation
DQN, Sarsa, Contigency, Human, HNeat Best 등의 방법들을 전부 시도해서 얻은 점수표는 아래와 같다. 사람은 2시간 플레이한 후의 점수를 확인했다.
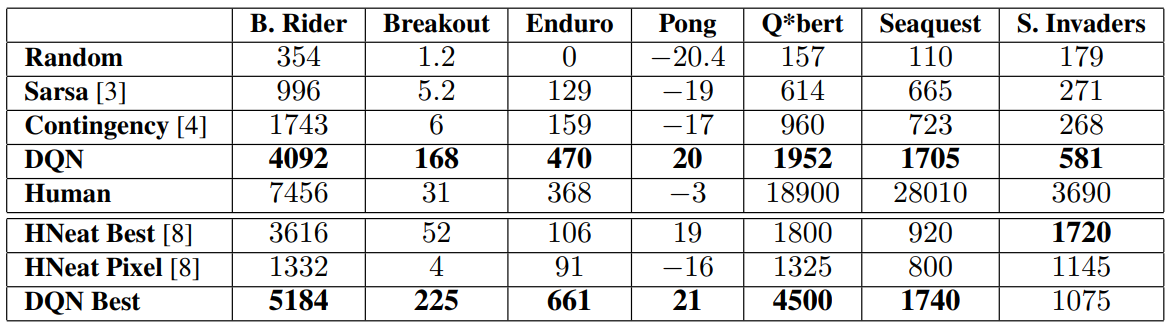
이 논문에서 제시한 DQN 모델이 기존의 대부분의 RL 모델보다 성능이 좋은 것을 확인할 수 있다. 일부 게임의 경우는 사람을 능가하는 성능을 보이는 것으로 확인되었다.
6. Conclusion
이 논문은 RL을 위한 새로운 딥러닝 모델을 만들었고, 오직 raw input만을 이요해서 게임을 조작하는 어려운 규칙을 만들어 낼 수 있는 능력을 보였다. 새로운 Q-learning의 형태를 보여서 RL을 위한 훈련을 더 쉽게 만들었다.
틀린 부분, 오탈자가 있다면 댓글 달아주시면 감사하겠습니다!
