RNN(Recurrent Neural Network, 순환 신경망)
0. NLP(자연어 처리)의 모델의 발전 과정

1. 개념
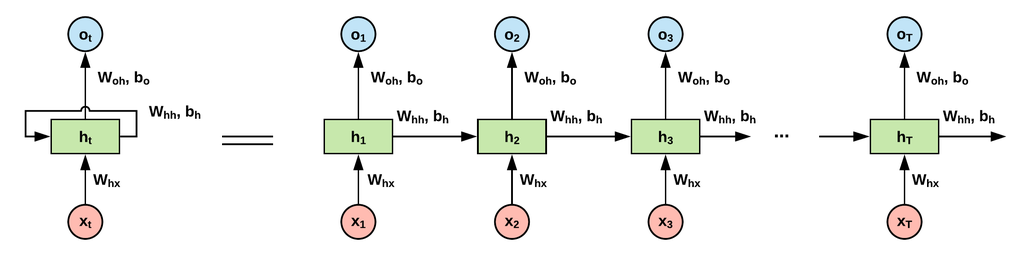
기존의 CNN 같은 신경망들은 전부 출력층 방향으로만 향했으나, RNN은 활성화함수를 통해 나온 결과값을 출력층 방향으로도 보냄, 즉 이전 계산의 결과가 다음 계산의 결과에 영향을 미치게 된다.
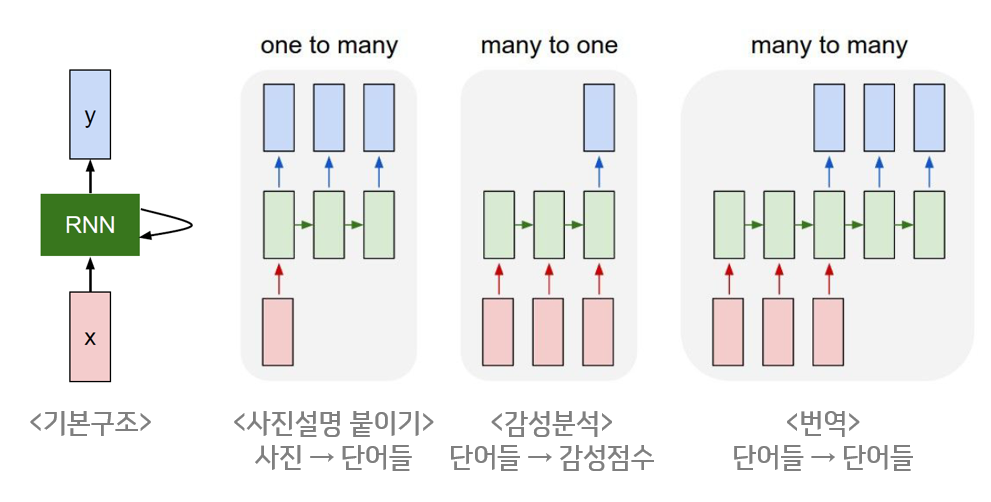
RNN은 input layer, hidden layer, output layer의 3가지 층으로 구성되고, 만들 수 있는 구조는 굉장히 다양하다.
그렇다면, 이 RNN이 어떤 방식으로 NLP에 활용이 되는가? —> input state의 각각에 단어 벡터를 넣어서 해당 문장을 해석 및 분류하는 방식으로 진행됨, 문장이기 때문에 전 후 단어들에 영향을 많이 받기 때문에 RNN이 활용되기 좋다.
2. 계산 방법
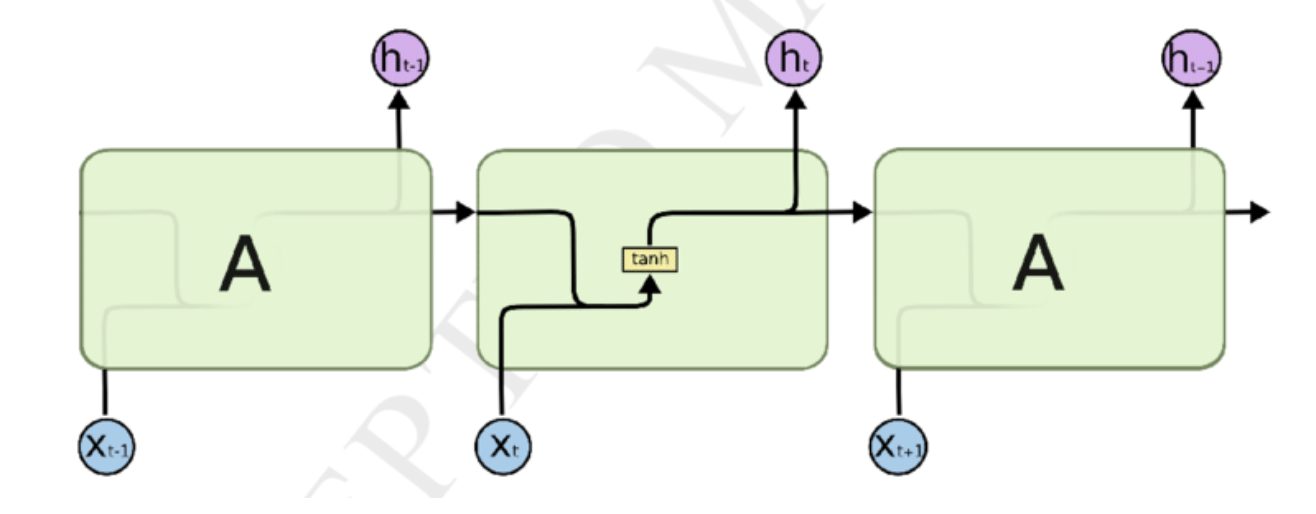
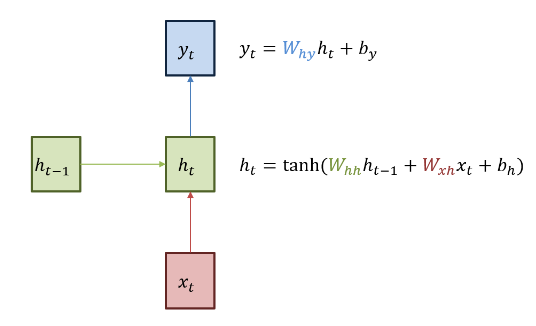
임의의 t 시간에서 은닉층의 값을 ht라고 두면, 이 값은 이전의 은닉층의 값과 가중치, 새로운 입력 값과 가중치, bias에 영향을 받기 때문에 아래와 같은 식을 사용한다. ReLU를 사용하지 않는 이유는, 이전의 값을 그대로 가져와서 사용하기 때문에, 전체적인 출력이 발산할 수 있기 때문에 Normalizing을 위해서 사용하게 된다. sigmoid는 다소 역전파가 tanh에 비해 느리다고 한다.
그리고, output layer가 존재한다면, 해당 가중치를 사용해서 출력 값을 얻을 수 있게 된다.
여기서 output은 다음 step에서 쓰이는 값이 아니기 때문에, 원하는 비선형 함수를 선택해서 쓰면 된다.
3. RNN 간단한 예제 코드
import numpy as np
timesteps = 10 #10회 실행하게 됨
input_dim = 4 #input의 크기
hidden_units = 8 #hidden layer의 크기
# 입력에 해당되는 2D 텐서(10회, 4쌍을 랜덤한 값으로 설정함)
inputs = np.random.random((timesteps, input_dim))
# 초기 은닉 상태는 0(벡터)로 초기화 = h0
hidden_state_t = np.zeros((hidden_units,))
# (8, 4)크기의 2D 텐서 생성. 입력에 대한 가중치.
Wx = np.random.random((hidden_units, input_dim))
# (8, 8)크기의 2D 텐서 생성. 은닉 상태에 대한 가중치.
Wh = np.random.random((hidden_units, hidden_units))
# (8,)크기의 1D 텐서 생성. 이 값은 편향(bias).
b = np.random.random((hidden_units,))
total_hidden_states = [] # t 시간에 해당하는 은닉층의 값들을 저장
# 각 시점 별 입력값.
for input_t in inputs:
# Wx * Xt + Wh * Ht-1 + b(bias)
output_t = np.tanh(np.dot(Wx,input_t) + np.dot(Wh,hidden_state_t) + b)
# 각 시점 t별 메모리 셀의 출력의 크기는 (timestep t, output_dim)
# 각 시점의 은닉 상태의 값을 계속해서 누적
total_hidden_states.append(list(output_t))
hidden_state_t = output_t
# 출력 시 값을 깔끔하게 해주는 용도.
total_hidden_states = np.stack(total_hidden_states, axis = 0)
# (timesteps, output_dim)
print('모든 시점의 은닉 상태 :')
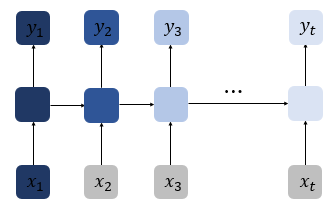
print(total_hidden_states)아래 사진들과 같이, 은닉층을 추가하거나 양 방향에서 정보를 받아오는 양방향 RNN도 존재한다.

LSTM(Long Short-Term Memory)
1. RNN의 한계

장기 의존성 문제(Problem of Long-Term Dependencies)
뒤로 갈 수록 점점 앞에서 전달하던 내용이 점점 희미해지고, 구문이 점차 길어짐에 따라서 효과의 정도가 훨씬 더 떨어진. 따라서 앞의 내용을 손실 없이 저장할 수 있는 새로운 모델이 필요함.
2. LSTM의 구조

1) 입력 게이트(Input gate)

여기서 사용되는 weight의 종류는 i를 구성할 때, input, hidden layer, bias에 해당하는 3가지이며, g의 경우도 마찬가지로 3가지가 사용된다. i는 sigmoid를 사용하므로 0에서 1사이, g는 tanh를 사용하므로 -1에서 1사이의 값이 나온다.
2) 삭제 게이트(Forget gate)

sigmoid 함수를 거쳐서 나온 결과를 확인하는데, 0에 가까울 수록 정보가 많이 삭제되며, 1에 가까울 수록 정보가 온전하다는 뜻이다. 즉, input이 positive 할 수록 정보가 많이 보존된다.
3) 셀 상태(Cell state)

셀 상태(Ct)를 게산하는 수식은 원소별 곱(elementwise product)으로 진행된다.
먼저 ft의 경우 0에 가까울 수록 이전 셀의 영향이 사라짐을 알 수 있다. 나머지 곱은 현재의 정보를 다음 셀에 전달해주기 위해서 곱해진다.
여기서 은닉 상태와 셀 상태는 서로 다른 목적을 가지고 만들어진다. 전부 전 state의 정보를 확인하는 것은 동일하지만, 셀 상태의 업데이트는 각 gate의 결과를 더함으로써 진행하고, 이는 오차를 더 잘 전파할 수 있도록 한다.
4) 출력 게이트와 은닉 상태

output값을 얻기 위해서 위 게이트들과 비슷하게 값을 얻는 것을 확인할 수 있다.
hidden layer값을 전달할 때는 vanilla RNN과 같이 tanh를 기존 output값에 추가적으로 사용하는 것을 확인할 수 있다. h값은 누적 합으로 계산되지 않고, 각 셀의 특징을 나타내기 위해서 tanh 함수를 사용한다.
GRU(Gated Recurrent Unit)
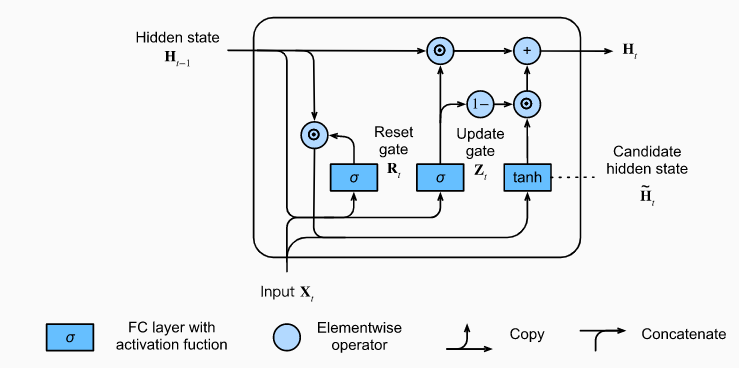

1) 업데이트 게이트(Update Gate)

LSTM에서의 forget gate, input gate의 역할을 담당하며, zt는 이전 정보의 비율을 결정한다. 따라서, 1-zt는 현재 정보의 비율이라고 계산할 수 있다.
2) 리셋 게이트(Reset Gate)

리셋 게이트는 zt와 계산하는 방법이 동일하며, 이전 정보에서 얼마만큼을 선택해서 정보를 전달할지 결정한다.
3) 은닉층(Hidden State)

GRU에서는 output gate없이 hidden state의 값을 전달한다. 과거 정보는 h(t-1)이고, 해당 정보를 내보낼 비율을 rt와 zt로 계산하였다. 따라서 이를 가지고 계산하면 전달하려는 정보에 관해서 아래와 같은 식을 얻을 수 있다.
-1부터 1 사이로 값을 만들기 위해서 계산된 결과에 tanh 함수를 사용했다. 일종의 output값으로 사용되는 개념이며, 해당 값을 이용해서 hidden state의 값을 계산하면 아래와 같은 식을 얻을 수 있다.
Seq2Seq
발전 배경
기존의 DNN 같은 경우에는 문제와 답들이 명확해서 분류하는 것을 목표로 만들어졌다. 그러나 여러 문장들을 가지고 만들어지는 많은 문제들(음성 인식, 번역기 등)은 먼저 길이가 주어지지 않고, 주어진 input에 관해서 나오는 답이 정확히 구분되지 않는다. 이러한 문제를 해결하기 위해서 주어진 sequence를 다른 sequence로 만드는 모델을 기존의 CNN 등의 방법이 아닌 RNN을 이용한 새로운 방법으로 제안한다. 이 논문에서는 영어를 프랑스어로 번역하는 작업을 수행했다.
1. Sequence-to-Sequence의 구조
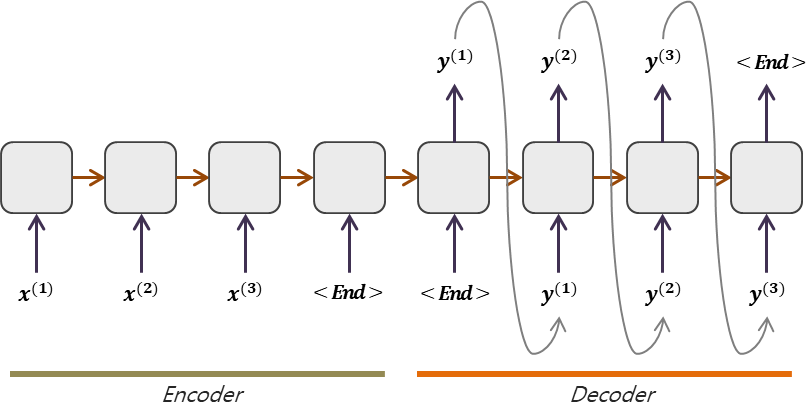
한 시퀀스를 다른 시퀀스로 변환하는 작업을 수행한는 딥러닝 모델이며, 앞에서 입력을 받아 해석하는 부분을 Encoder, 출력 시퀀스로 변환하는 작업을 수행하는 부분을 Decoder라고 부른다. LSTM 혹은 GRU를 사용한다. 2개의 모델은 실질적으로 속도 차이가 거의 없는 것으로 알려져 있다.
1) Encoder
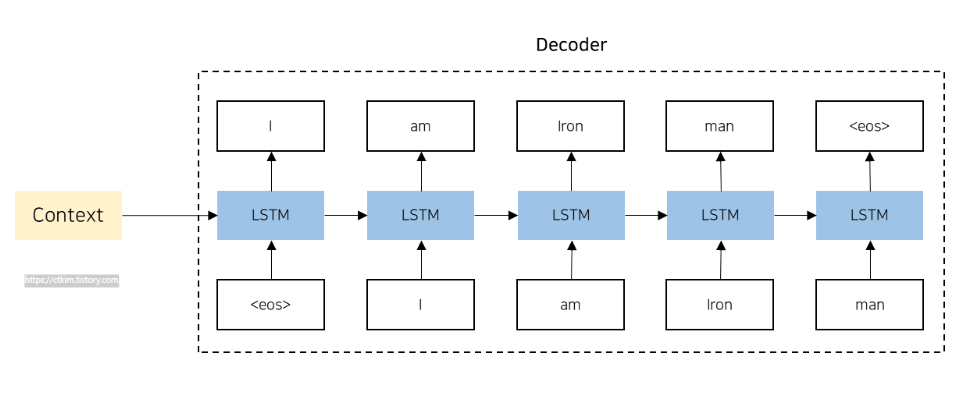
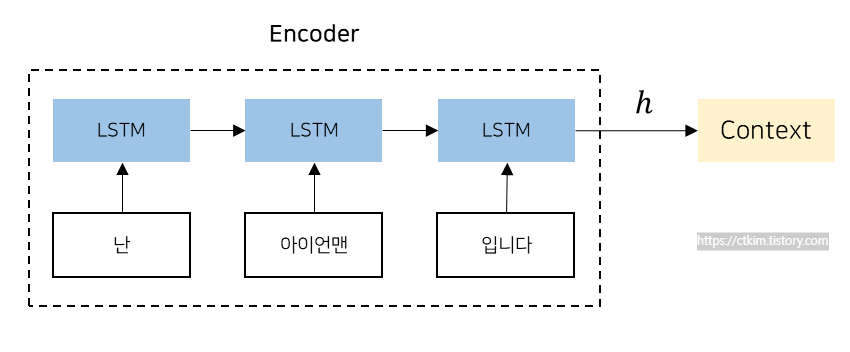
RNN, LSTM, GRU 등의 구조를 사용하여 input sequence를 고정 길이의 벡터로 변환하는 역할을 수행한다. 각 단계에서 신경망을 거치면서 hidden state를 업데이트 하고 최종적으로 벡터 h를 생성해서 디코더로 전달시킨다. 즉, 이 과정에서 input으로 들어온 문장의 특징을 분석하는 것이다.
2) Decoder
디코더는 인코더에서 가져온 고정 길이의 벡터를 가지고 원하는 출력 시퀀스를 생성하는 역할을 수행한다. 인코더와 유사한 구조를 사용하며, 각 모듈을 지날 때마다 softmax function을 이용해서 확률 분포로 변환시키며, 가장 확률이 높은 단어가 선택된다. 즉, 이전 단어들을 가지고 다음에 나올 단어를 예측하는 셈이다. 그래서 전 모듈에서 나온 output 값이 다음 모듈의 input으로 들어가는 것을 확인할 수 있다. 는 디코더에게 문장 생성 시작과 종료를 알리는 신호로 사용된다.
3) 실험의 특징
이 논문에서는 각각 160000개와 80000개의 빈도가 높은 단어들을 영어(source language)와 불어(target language)에 설정했다. 이에 해당되지 않는 단어들은 UNK 토큰으로 정의했다. —> 나중에 NLP 관련된 내용을 더 자세히 읽으면 알 수 있을 것이다. OOV 같은 형식???
Beam Search
예측 값의 확률 분포 중 가장 높은 확률 K개를 고르고, 해당 K개에서 다음으로 확률이 높은 K개를 선택한 뒤, 전체 K*K개 중에서 상위 K개를 선택해서 학습을 진행한다. 이 과정을 를 만날 때까지 반복한다.
논문에서는 target sentence를 뒤집어서 훈련시키면 성능이 더 좋아진다고 함… —> 논문에서의 추측은 원래대로 문장을 넣게 되면 모든 단어간 거리가 동일하지만, 뒤집어서 넣게 되면 문장에서 초반에 나오는 단어들의 거리가 상대적으로 짧아지고, 이는 초반 단어들의 예측을 더 정확하게 해준다. 따라서, 초반 단어들의 정확도가 올라가고, 잇따르는 문장의 단어들의 정확도 역시 올라간다.
parameter의 초기값은 -0.08에서 0.08로 설정했고, optimizer는 SGD, 학습률은 0.7로 했고, 5회 학습 후 매 회마다 학습률을 절반으로 줄였다. 또한, 각 batch에 128개가 포함되게 설정했으며, 너무 긴 문장이 포함되어 있는 경우 normalize를 했다.
4) 교사 강요(teacher forcing)
decoder를 훈련하는 과정에서 이전 셀의 출력이 다음 셀을 출력하는데 사용되는데, 이 때 전 셀의 출력이 잘못될 가능성이 있다. 그런 경우, 연쇄적으로 작용하는 이 모델의 경우 다음 출력까지 잘못될 우려가 있기 때문에 예측과는 다른 실제 값을 decoder 셀의 입력으로 넣어주는 방법을 사용한다.
5) 모델의 한계
고정된 길이의 벡터로 압축되기 때문에, input sequence의 길이에 대한 유연성이 떨어진다. 즉, input의 길이가 길어질 수록 손실되는 정보의 양이 증가한다. 따라서, 해당 정보들을 온전히 전달하기 위해서는 인코더에서 고정적으로 더 긴 길이의 벡터를 만들어야 하는데, 이는 모델의 전체적인 효율을 저하시키는 결과를 낳는다.
A ten-minute introduction to sequence-to-sequence learning in Keras
6) 실행 예시
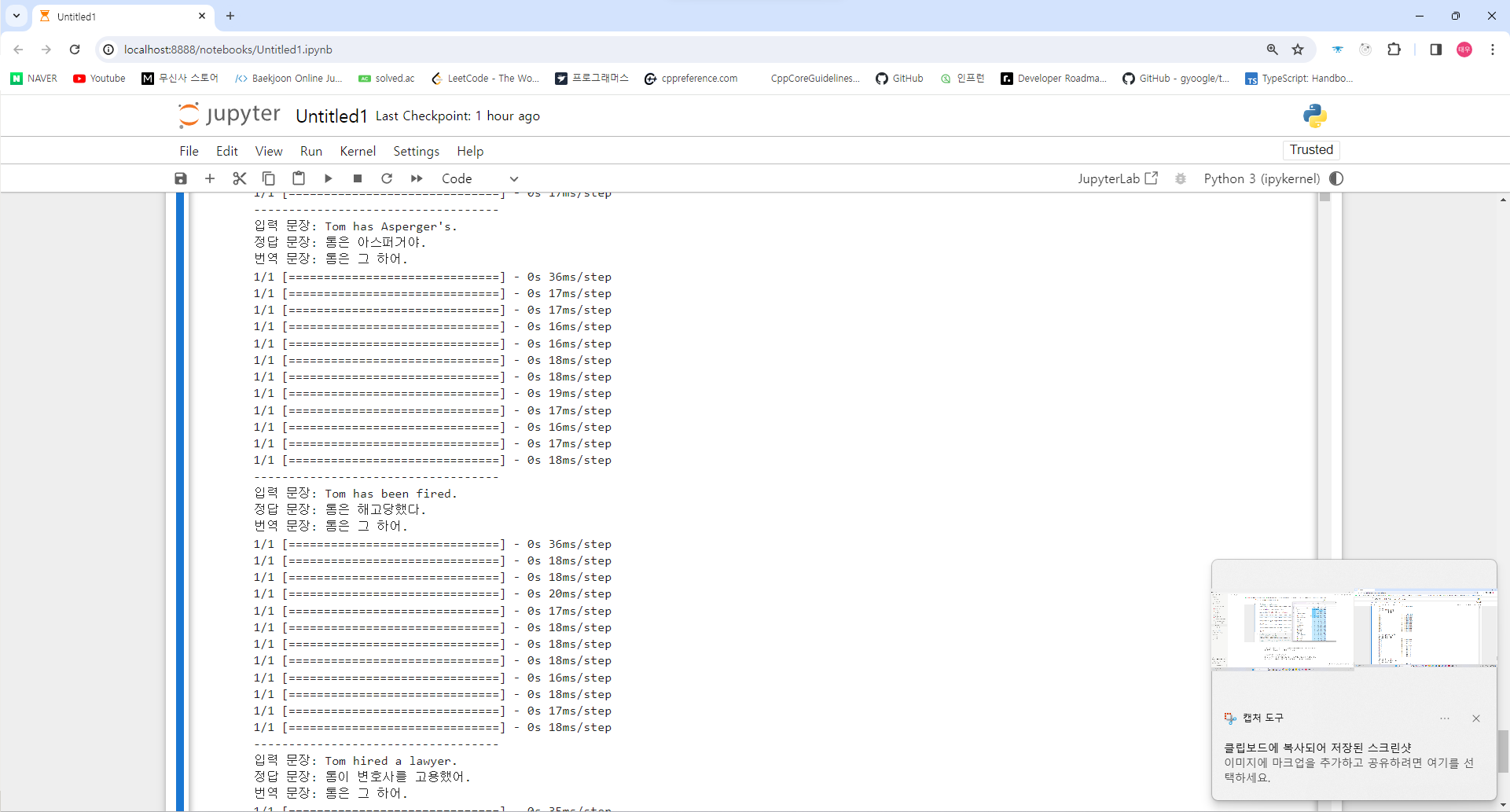
기존 실행 방법에서는 영어를 프랑스어로 번역하는 과정이었지만, 한국어 파일도 있어서 fr을 ko로 바뀌어서 진행했습니다.
RAM과 CPU가 굉장히 많이 잡아먹힙니다… epoch를 40회가 아니라 좀 더 줄였어야 했는데 epoch 한 번에 80초나 소요될 줄 몰라서 대략 50분 정도 소요되었습니다.
원래는 프랑스어가 사용되었기 때문에 한글과는 다소 다른 부분들이 많을 것이라 예측했습니다. 글자 수도 굉장히 많이 차이나고, 어순 등도 다르기 때문에 결과가 나쁠 것이라고 예상했습니다.
실제로 프랑스어와는 달리 다른 값이 나온 것을 확인할 수 있었습니다. 이게 코드 오류라서 그런건지는 정확하게 모르겠지만, 언어에 따라서 다른 모델을 적용하는 것 같습니다.
Reference
딥 러닝을 이용한 자연어 처리 입문
LSTM(Long Short Term Memory)
Gated Recurrent Unit(GRU)의 이해
