작성 계기
RCNN은 컴퓨터비전에서 CNN을 사용한 obejct detection 기술 초기에 엄청난 영향을 미친 논문이다.
회사가 CNN 기반 비전기술로 이 논문의 영향이 있기에 읽게 되었다.
이 논문을 구체적으로 읽기보단 전반적인 시스템이 어떻게 돌아가는지에 대해 초점을 두고 있어서 틀린 부분이 있다면 댓글을 통해 남겨주시길 바란다. 또한, 이해하는데 어려운 부분이 있어서 이미 작성된 논문 리뷰를 참고한 것도 있다.
토요일에도 공부하는 나는 멋쟁이 아이패드 갖고싶당
Abstract
-
Object를 localize 및 segementation을 하기 위해서 bottom-up 방식의 region proposal에 CNN을 적용한다.
-
fine-turning 을 통해 supervied pre-training을 적용하여 성능 향상한다.
1. Introduction
R-CNN process
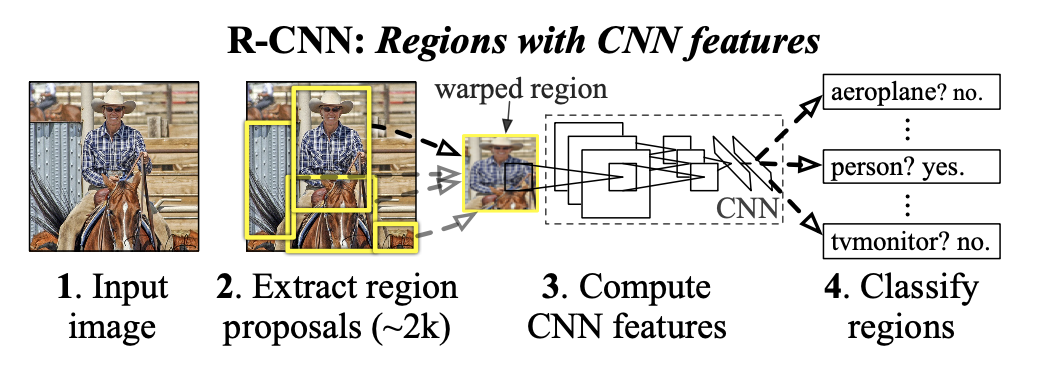
위 figure 1은 R-CNN의 전체적인 프로세스이다.
-
Input image로 부터 독립적인 Region proposal을 생성, 추출을 한다.
-
warp 을 통해서 resize를 하여 이미지 변형을 한다.
-
CNN을 통해서 고정된 길이의 feature vector을 추출한다.
-
각 region마다 linear SVM을 통해서 classification을 수행한다.
2. Object detection with R-CNN
2.1 Module design
1. Rigion proposals
이전 Detection 작업과 제어된 비교 가능한 방식인 Selective Search라는 최적의 Region proposal를 제안하는 기법을 사용해서 독립적인 Region proposal을 추출한다.
- selective search
1) Image의 초기 segement를 정해서 수많은 Region 영역을 생성함
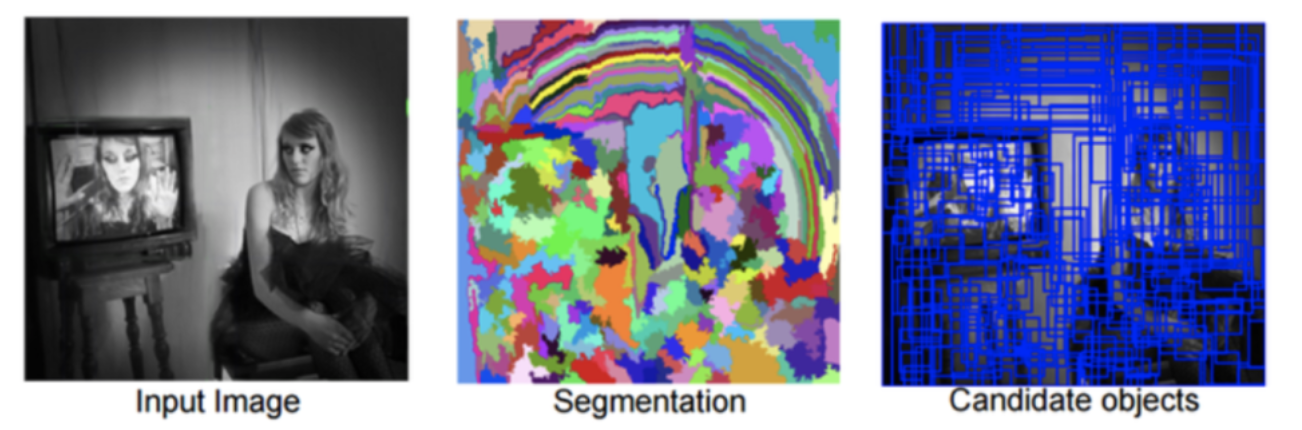
2) Greedy Algorithm을 이용하여 각 Region을 기준으로 주변의 유사한 영역을 결합
Greedy algorithm을 사용해서 여러 영역으로부터 가장 비슷한 영역을 선택하고, 더 큰 영역으로 통합하여 1개의 영역이 남을 때까지 반복

3) 통합된 Region을 바탕으로 Region proposal로 만들어낸다.

2. Feature extraction
Selective Search 방법을 통해 도출된 각 Region proposal로부터 CNN을 사용하여 4096차원의 vector를 추출한다.
CNN의 입력으로 사용되기 위해서 각 Region은 277x277 RGB의 고정된 사이즈로 변횐된다. (Wrap)
2.2 Test-time detection
2.3. Training
1. Supervised pre-training
ILSVRC 2012 classfication dataset을 pre-trained CNN(AlexNet) 모델을 사용한다.
2. Domain-specific fine-turning
classification에 최적화된 CNN 모델을 적용하기 위해서 VOC의 Region Proposal를 통해 SGD 방식으로 CNN parameter에 업데이트한다.
이 과정 이후에 SVM을 통해서 classification 및 bounding regression이 수행된다.
SGD (Stochastic Gradient Descent)
: 전체 Data(Batch)를 가지고 한번의 Loss function을 계산하는 것 대신 일부 데이터의 모음(Mini-Batch)를 사용하여 Loss function을 계산한다.
Neural Network의 weight를 조정하는 과정에서 보통 Gradient Descent 방법을 사용하는데 네트워크에서 내놓는 결과값과 실제 값 사이의 차이를 정의하는 Loss function의 값을 최소화하기 위해서 기울기를 사용한다.
전체 데이터에 대해서 Loss function을 계산하는 경우 많은 계산양이 필요하기 때문에 이를 사용한다.
NMS (Non-Maximum Suppression)
1) 예측한 bounding box들의 예측 점수를 내림차순으로 정렬
2) 높은 점수의 박스부터 시작하여 나머지 박스들 간의 IoU를 계산
3) IoU값이 지정한 threshold보다 높은 박스를 제거
4) 최적의 박스만 남을 때까지 위 과정을 반복
3. Results on PASCAL VOC 2010-12

위의 Table 1은 VOC 2010 test dataset에 대한 각 모델별 결과이다.
UVA 모델은 mAP는 35.1%, R-CNN의 mAP는 53.7%인 것을 확인할 수 있고 이것을 높은 증가율이라고 본 논문에서 말하고 있다.
논문에 VOC 2011/12 dataset에 대한 결과도 있다.
PASCAL VOC (PASCAL Visual Object Classes Challenge)
컴퓨터 비전 분야의 기술 중 하나인 Object class recongnition 기술을 겨루는 국제대회로 2005년부터 2012년까지 매년 진행된 대회이다.
입력 영상에서 특정 종류의 물체를 검출해 내는 성능을 겨룬 대회인데, 총 20가지의 각 물체에 대해 우승자를 가린다. (test dataset & ground truth 다운로드 가능)
PASCAL은 Pattern Anaylsis, Statistical Modeling and Computational Learning의 약자이다.
Reference
[seletive search] J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013 - Selective Search
