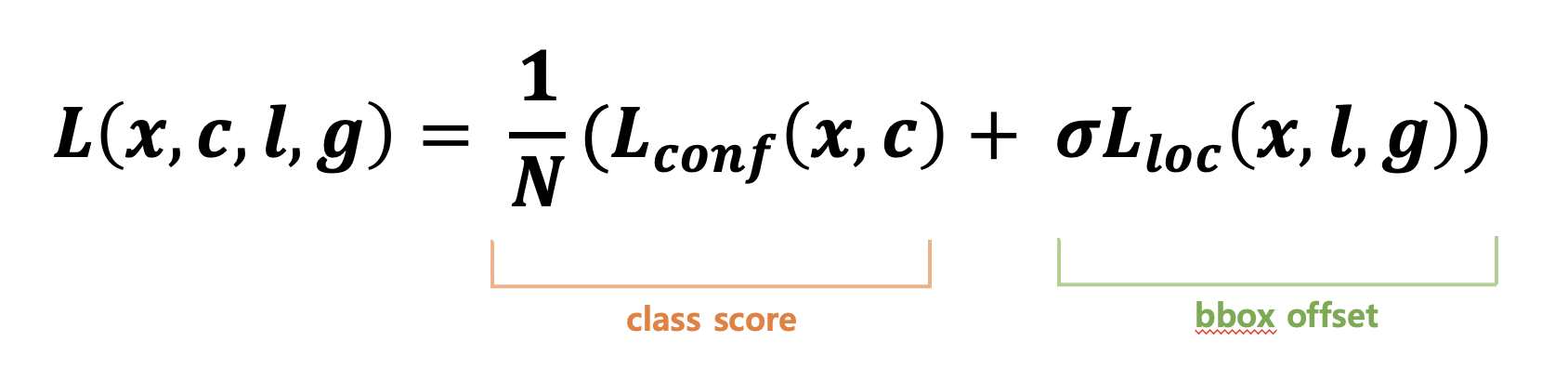작성계기
회사에서 논문을 읽고 있는데, 화요일마다 리뷰시간이 있어서 공부겸 다시 정리
Abstract
- multiple feature map을 사용해서 output 공간을 여러개로 나눈다.
- 각 feature map을 여러 비율과 스케율로 default box를 생성하고 모델을 통해서 계산된 좌표와 class score을 생성한 default box를 통해 최종 bbox를 생성한다.
- 2-stage의 Faster-RCNN의 성능을 가지면서 1-stage의 YOLO와 같이 속도가 빠르다고 말한다.
즉, 이 논문은 1 stagy의 detector!
Introduce
아래와 같이 간추려 설명함.
1. 이전 state-of-the art보다 (YOLO) 속도가 빠르고, region proposal과 pooling (Faster-RCNN)의 성능이 빠르다고 한다.
2. SSD는 feature map에 적용된 small conv를 사용하여 고정된 default bbox set을 통해 category score과 box offset을 예측한다.
3. high detection accuracy를 위해서 가로 세로 비율, scale이 서로 다른 feature map을 제공한다.
4. time, input size 등 다 실험했고 PASCAL VOC, COCO, ILSVRC에서도 데이터 성능비교 결과 제일 좋다.
The Single Shot Detector (SSD)
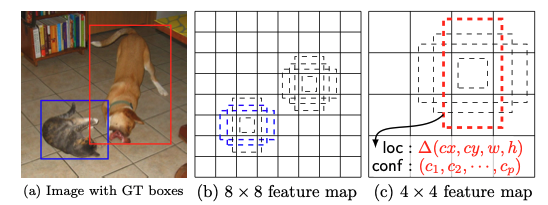
SSD는 위 그림 (a)에서 처럼 학습을 위해 각 물체에 대한 input image와 GT가 필요하다.
(b) 각 다른 scale을 가진 feature map에 대하여 각 다른 비율을 가진 default box로 평가한다.
(c) 각 default box 통해, 각 물체 category에 대한 shape offset과 confidence를 예측할 수 있다.
2.1 model
The SSD approach is based on a feed-forward convolutional network that produces a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by a non-maximum suppression step to produce the final detections.
여기서 그렇게 중요한건 아니지만.. "feed-forwad"라는 말이 뭔지 몰라서 찾아보았다.(딥러닝을 배우는 중이라서 개념이 그렇게 완전히 잡혀있진 않음 ㅠㅠ)
대강 입력층에서 1개이상의 은닉층이 존재하여 출력층으로 전개되는 신경망을 의미한다. (그냥 딥러닝 아니야? 라고 말할수있지만, Recrruent nerual network라고 부르는 RNN에서는 출력층의 값이 은닉층으로 다시 들어가는 경우도 존재하기 때문에 나눈다고 함)
anyway!
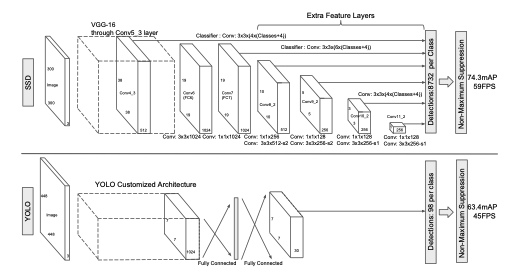
모델은 위와 같다.
VGG-16 network 모델을 가져와서 FC layer를 제외한 conv7까지를 base network로 사용한다.
이 conv4_3에서 38x38x512크기의 feature map을 뽑고, conv7에서 19x19x1024 뽑음. 이 과정 포함하여 이후 layer에서 뽑는 feature map들은 output가 직결되어 있고 layer가 지날수록 size가 감소한다.
그래서 총 6개의 feature map을 뽑음.
좀 더 자세히 말하자면, 38x38x512, 19x19x1024x 10x10x512, 5x5x256, 3x3x256, 1x1x256 총 6개의 다양한 scale이 존재하는 feature map 뽑는다.
따라서, 각 scale이 다른 feature map에 해당하는 default box를 적용한 경우 default box의 수는 (38x38x4)+(19x19x6)+(10x10x6)+(5x5x6)+(3x3x4)+(1x1x4)= 8732개가 나오게 된다.
또한, 최종 예측을 위해서 feature map 추출 후에 3x3(stride=1, padding=1) conv 연산을 수행한다.
Default boxes and aspect ratios
(여기는 진짜 이해하는데 어려웠다.. 아직도 이해 좀 안가는 부분이 있어서 미팅 후에 정리되면 다시 정리올리겠음)
여기서 위의 모델 구조를 보면 classifier: conv: 3x3x(4x(classes+4)) 이런것을 볼 수가 있다. 각 feature map의 cell마다 default box를 생성하는데, 이 때 default bbox를 , 예측하려는 class의 수를 라 할 때, output feature map의 채널 수는 로 결과를 뽑는다. 따라서 의 feature map의 output channel 수는 이다.
좀 더 설명하자면, 각 feature map의 cell마다 default box를 생성하고 각 box마다 4개의 offset과 class score가 존재하는 것.
예를 들어, 첫번째 feature map인 38x38x512를 보면, m=38, n= 38이고 이 해당 feature map에서는 default bbox를 4개를 사용하였다. 따라서 k=4이다. 또한, PASCAL VOC의 class는 20개이고, background까지 포함하여 c=21라 한다면 conv연산을 한 output feature map의 크기는 38x38x4x(21+4) 이다.
2.2 Training
Matching strategy
We begin by matching each groud truth box to the dfault box with the best jaccard overlap. Unlike MultiBox, we then match default boxes to any groudn truth with jaccard overlap higher than a thershold(0.5). This simplifies the learning problem, allowing the network to predict high scores for multiple overlapping default boxes rather than requiring it to pick only the one with maximum overlap.
Training을 하기위해, 위에서 언급한 default box와 학습할 대상을 결정하기 위해서 default box가 어떤 ground truth 와 대응되는지를 알아야한다.
이를 위해서 default box와 ground truth 간의 jaccard overlap를 사용하는데, 여기서 jaccard overlap은 우리가 잘 알고 있는 IoU(Interset of Union)과 같다.
default box와 ground box간의 jaccard overlap의 threshold가 0.5이상인 Box는 positive로, 그 미만인 box들은 negative가 된다.
여기서 이 이후에 hard negative mining이 나오게 된다.
matching step 이후에, default box 대부분이 positive sample 수보다 negative sample 수가 더 많기 때문에 학습을 하는데 Positive와 negative사이의 상당한 불균형이 일어난다고 한다. 그 이유는 전반적인 이미지 내에 사물보다 배경(background)가 많기 때문에 높은 confindence loss를 가진 sample를 추가하는 hard negative mining을 사용한다. 본 논문에서는 positive와 negative 사이의 비율을 1:3으로 둔다한다.
Training objective