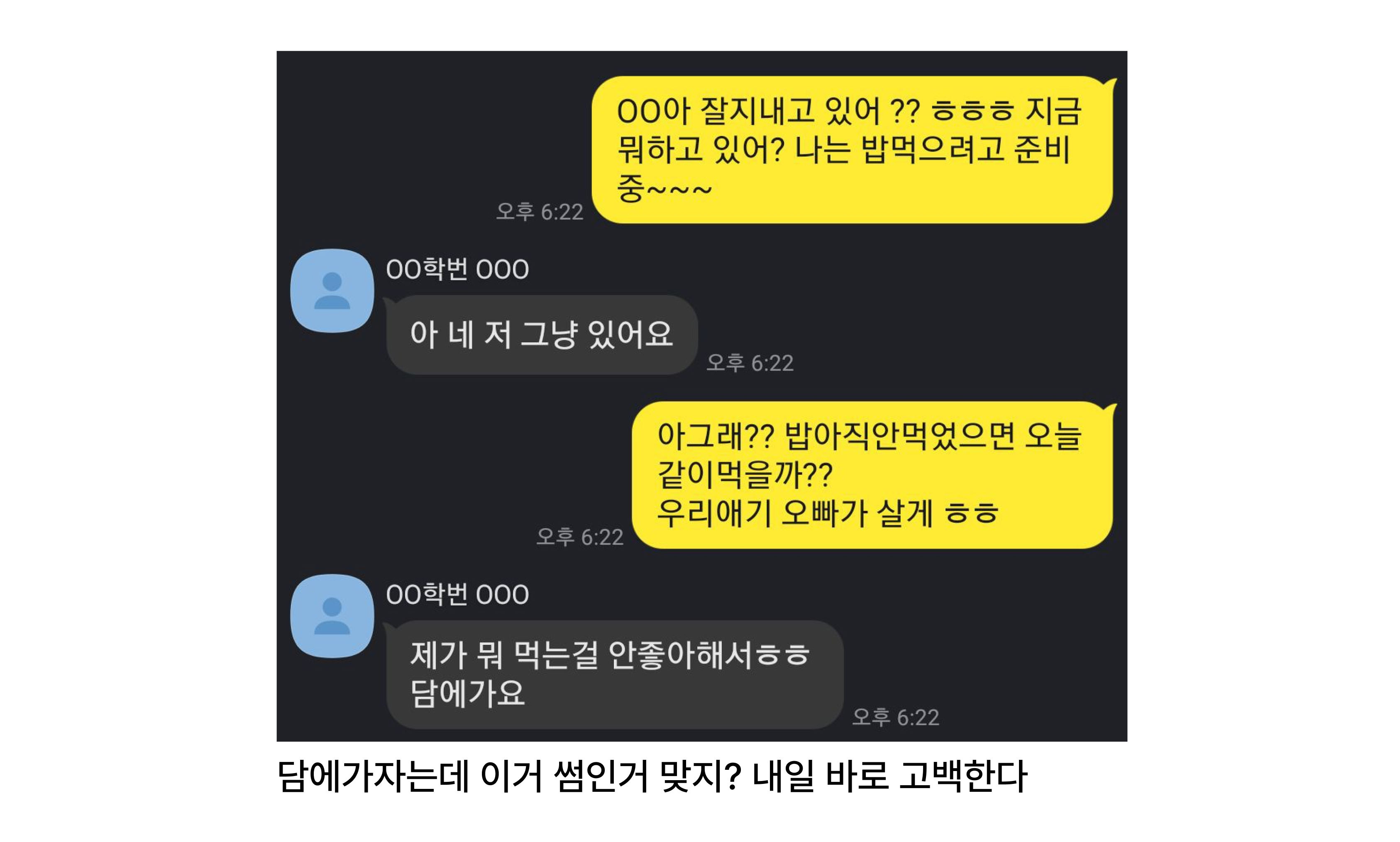
학교에서 작은 대회를 하나 하길래 재미로 참가해볼 겸 소소하게 친구와 함께 데이터분석 프로젝트를 만들어보자고 생각했다.
카카오톡 대화 내역을 분석하여 상대방과 나의 사이는 썸인지, 비즈니스인지,
친구인지, 커플인지 나타내주는 AI를 개발해보자.
Maru님의 졸업 프로젝트 '믿어방'에 대한 글을 보고 참고하여 제작했다. 샤라웃샤라웃
두근두근, 우리 과연 썸일까?
입력받은 대화 내용으로 형태소를 분석하여 유사도를 도출하는 함수를 만들어보자.
sklearn.feature_extraction.text의 Tfidf를 사용하여 vectorizer 구축하기
sklearn.feature_extraction.text에서 지원하는 vectorizer중에서는
CountVectorizer와 TfidfVectorizer가 있다.
CountVectorizer는 형태소에서 count된 값으로 결과를 도출해주고,
TfidfVectorizer는 반복되는 단어는 가중치를 낮추어 평균적인 결과를 도출하게 해준다.
만약에 누가 뭐 '사랑해 사랑해 사랑해 사랑해 사랑해' 이런 데이터를 넣었다고 하면
이걸 연인이라고 하긴 좀 어렵다 예 경찰서 ㄱㄱ..
따라서 이런 중복되는 단어에 대한 가중치를 낮추기 위해서 TfidfVectorizer를
사용하기로 했다.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df=1) 그래서 문장들을 벡터화시켜서 유사도를 도출해볼 생각이다.
예를 들어
[안녕하세요, 반갑습니다, 감사합니다, 뭐라고요?, 그렇군요]
의 데이터가 있는데, 타겟 문장이
'안녕하세요, 그런데 뭐라고요? 네, 감사합니다, 감사합니다'
와 같다면 벡터는
[1,0,2,0,0]
이렇게 표현이 된다.
그래서 학습 데이터와 타겟 문장의 벡터를 각각 구하여 코사인 유사도를 얻기 위한
거리를 구하여 문장 유사도를 얻어보려고 한다.
Okt 사용하여 형태소 분리하기
Okt라는 라이브러리를 사용하여 형태소를 분리하기로 했다.
여러 라이브러리 중 적당히 시간이 빠르고, 형태소도 적당히 디테일하게
분리해주었기에 빠른 시간 내에 결과가 도출되기를 기대하여 해당 라이브러리를 사용했다.
from konlpy.tag import Okt
translate = Okt()학습 데이터 벡터화 시키기
기존에 준비되어있던 학습 데이터를 벡터화시킨다.
models_tokens = [translate.morphs(row) for row in models]
models_for_vectorize = [' '.join(tokens) for tokens in models_tokens]
X2 = vectorizer.fit_transform(models_for_vectorize)이렇게되면 이차원 배열로 벡터화된 학습 데이터를 얻을 수 있다.
타겟 문장 벡터화 시키기
비슷하게 다음과 같이 작성해준다.
target_tokens = [translate.morphs(row) for row in target]
targets_for_vectorize = [' '.join(tokens) for tokens in target_tokens]
t_vec = vectorizer.transform(targets_for_vectorize)거리 구하기
벡터를 비교하여 dist_raw라는 함수로 거리를 구해주자.
구한 거리를 나타낼 때에는 scipy 라이브러리를 사용해주었다.
import scipy as sp
def dist_raw(v1, v2):
delta = v1 - v2
return sp.linalg.norm(delta.toarray())다음과 같이 사용해주자.
best_dist = 65535
best_i = None
for i in range(len(models)):
vec = X2.getrow(i)
d = dist_raw(vec, t_vec)
print("== Post %i with dist=%.2f : %s"%(i, d, models[i]))
if d < best_dist:
best_dist, best_i = d, i
s.append([d, i])
print("== Best %i with dist=%.6f : %s"%(best_i, best_dist, models[best_i]))여기까지 테스트해보고, 샘플 데이터를 넣어보았다.

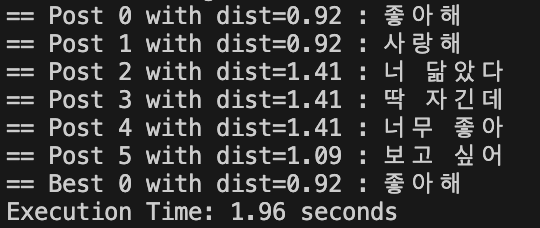
distance가 낮을 수록 형태소와 유사하다는 의미이다.
각 파트에 알맞는 데이터 도출 유도해보기
연인, 비즈니스, 썸, 친구에 잘 맞을 법한 문장들을 직접 만들어 이와 비슷한
결과값을 기대하며 데이터 도출을 유도해보았다.
각 형태소마다 도출된 distance값을 다 더해서 결과를 내기로 했다.
마찬가지로 distance가 낮을 수록 유사하다는 의미이다

기대한 것과 다르게 문제점이 많았다.
일단 비즈니스가 거의 고정값 급으로 변하지 않았고, 나머지 데이터들도 분류에 반해
각각 차이가 그렇게 크게 나지 않았다. 그리고 친구는 또 왜이렇게 유사하지 않은 것이냐...
데이터 교정하여 정확도 높이기 1
친구와 유사한 문장이 잘 나오지 않았기에, '친구' 학습 데이터를 잘 살펴 보았다.
보통 짧은 문장과 은어, 예를 들면 'ㅋㅋ', 'ㄷㄷ'와 같은 데이터들이 많이 있었다.
형태소를 분석하는 거라면 이런 모든 문장들을 다 합치고, 대화 내용도 모두 합쳐서
분석을 해주는 것이 더 정확할 거라고 판단했다.
중복되는 값들은 tfidf를 사용하여 가중치를 낮춰주기에 문제가 없을거라고 판단하고
모든 문장을 합쳐서 분석하는 로직으로 변경하여 값을 내보았다.

비즈니스가 친구가 제일 가깝게 출력된 것을 제외하고는 모두 유도한 것과 동일한 값이
도출되었다.
아직도 비즈니스가 거의 고정값으로 도출되었기에, 이를 판별하는 다른 로직이
추가되어야겠다고 생각했다.
우리 사이가 비즈니스인지 판단하기
여러가지 예외 사항이 발생할 수는 있지만, 가벼운 마음으로 시작한 데이터 분석이기에
다음과 같은 가정을 했다.
나와 상대방의 사이가 만약 비즈니스라면, 대부분 존댓말을 사용할 것이다.
Komoran을 사용하여 존댓말 분류하기
오종민님의 글을 참고하며 설계했다 화이팅 샤라웃샤라웃
여러가지 형태소 분석기 중에서, 존댓말을 분류할 때에는 Komoran을 채택했다.
토큰을 normalize하게 잡아주기 때문이라고 한다.
가끔씩 "안녕하세요" 등의 존댓말이 무시되는 경우가 있어 Okt를 사용해볼까도 고민해보았는데,
충분히 값을 조정하여 핸들링할 수 있을거라고 생각하여 그대로 사용했다.
먼저 존댓말 토큰(모델 또는 학습데이터)을 선언했다.
komoran_honorific_token.txt
('저', 'NP')
('전', 'MM')
('절', 'NNG')
('제가', 'NNP')
('고마워요', 'NNP')
('해주시', 'NNP')
('분', 'NNB')
('어딨어요?', 'NA')
('님', 'XSN')
('께', 'JKB')
('에요', 'EF')
('에요', 'EC')
('아요', 'EC')
('아요', 'EF')
('예요', 'EF')
('예요', 'EC')
('어서요', 'EF')
('어서요', 'EC')
('요', 'JX')
('요', 'EC')
('요', 'EF')
('군요', 'EC')
('군요', 'EF')
('ㄴ데요', 'EC')
('어요', 'EF')
('어요', 'EC')
('구요', 'EF')
('구요', 'EC')
('ㄹ게요', 'EC')
('게요', 'EC')
('ㄹ께요', 'EF')
('지요', 'EF')
('지요', 'EC')
('네요', 'EC')
('네요', 'EF')
('죠', 'EF')
('죠', 'EC')
('니까요', 'EF')
('니까요', 'EC')
('ㅂ니까', 'EF')
('나요', 'EF')
('ㅂ니다', 'EF')
('ㅂ니다', 'EC')
('ㅂ시다', 'EF')
('ㅂ시다', 'EC')
('습니다', 'EF')
('습니다', 'EC')
('답니다', 'EF')
('답니다', 'EC')
('시', 'EP')
('드리', 'VV')
('으시', 'EP')
('ㅔ요', 'EC')
('ㄴ데요', 'EC')
('ㄴ걸요', 'EC')
('ㄹ까요', 'EC')
('ㄹ까요', 'EF')
('던가요', 'EF')
('거든요', 'EC')
('거든요', 'EF')
('ㄴ가요', 'EC')
('더라구요', 'EF')
('더라구요', 'EC')
('더라고요', 'EC')
('더라고요', 'EF')
('려고요', 'EF')
('을까요', 'EF')
('을까요', 'EC')
('면서요', 'EF')
('래요', 'EC')
('그래요', 'IC')
('으면', 'EC')해당 토큰으로 text를 받으면 토큰들과 비교하여 존댓말을 count해주는
함수를 작성했다.
import re
from konlpy.tag import Komoran
komoran = Komoran()
hon_tokens = [word.rstrip('\n') for word in open('app/ml/' + 'komoran_honorific_token.txt', 'r',encoding='utf-8')]
def honorific_token_counter(text):
cnt = 0
for i in komoran.pos(text):
if str(i) in hon_tokens: cnt += 1
return cnt
잘 작동하는 것을 볼 수 있다.
Kss 사용하여 더 부드럽게 예외 처리하기
하지만 위에서 말한 것처럼 존댓말이 무시되는 경우가 있을 수 있고,
비즈니스인데도 상사와의 대화라면 일방적인 존댓말이 사용될 수 있다는 가능성을 생각했다.
그래서 문장의 개수를 따로 세어 count된 존댓말이 개수의 절반을 넘으면 비즈니스값을 도출해주기로 했다.
문장의 개수를 세어주는 라이브러리인 kss를 사용했다.
from kss import split_sentences
from app.utils.honorific_token_counter import honorific_token_counter
def honorific_analysis(target):
target = ' '.join(target)
tokens = honorific_token_counter(target)
sentence = len(split_sentences(target, backend='pecab'))
if not sentence: return [False, 1]
average = 1 - tokens/sentence
if average < 0: average = 0
if tokens > sentence//2: return [True, average]
return [False, average]둘을 사용하여 다음과 같은 최종적인 함수를 구현했다.
존댓말의 수가 문장의 수 절반을 넘는다면 True를 반환하도록 설계했다.
데이터 교정하여 정확도 높이기 2
위에서 설계한 존댓말 분석기를 메인 로직에 도입하여 결과를 도출했다.

비즈니스의 거리가 티가 나게 줄어든 것을 볼 수 있다.
하지만 혼자 이러한 방식을 사용하여 값이 도출될 경우 다른 값과 차이가 심할 수 있기 때문에,
만약 존댓말이 문장 개수의 절반을 넘지 못한다면 다른 데이터와 똑같은 분석 방법을
실행시켜주도록 로직을 정리했다.
백분율로 바꾸기
결국에는 각 파트가 몇 퍼센트에 해당하는지를 반환해야 했기 때문에,
값이 낮을 수록 백분율을 높여주는 계산 함수를 따로 만들어 적용했다.
def percentage_calculator(data):
sorted_data = sorted(data.items(), key=lambda x: x[1][0])
total = sum(1 / (abs(value[0]) + 0.01) for _, value in sorted_data)
percentages = {key: (1 / (abs(value[0]) + 0.01)) / total * 100 for key, value in sorted_data}
return percentagesAPI 구축
백엔드와 프론트엔드를 생각하고 만든 프로젝트이기 때문에, 해당 로직으로
API를 설계해주었다.
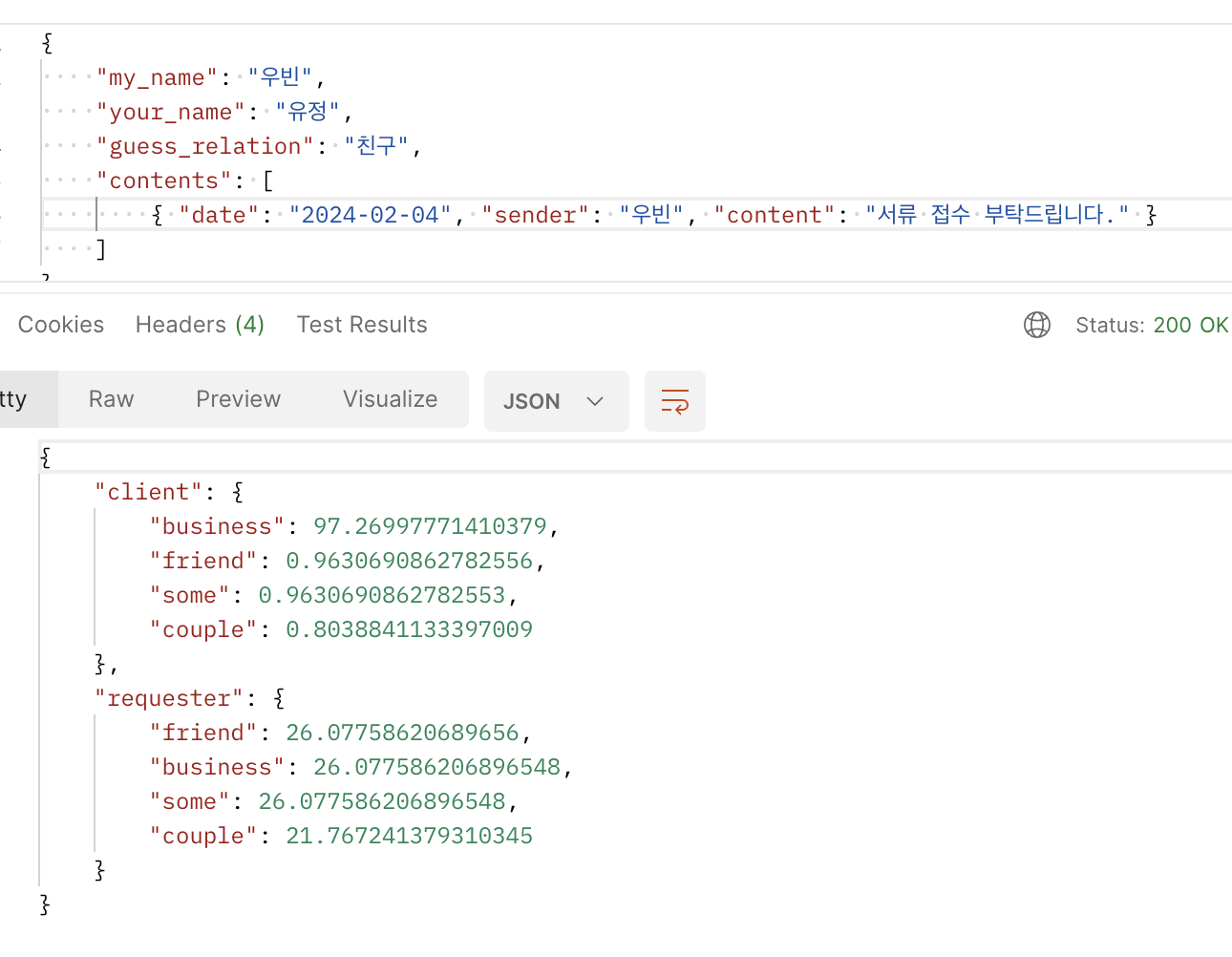
포스트맨으로 테스트한 결과이다.
contents에 따라 각 파트를 백분율로 나누어 보여준다.
아무것도 넣지 않은 requester의 couple값이 낮다는 것을 볼 수 있다.
내 생각에는 학습 데이터들이 파트마다 개수나 어절의 차이가 있기에 나는 차이지않을까 싶다 (couple이 다른 데이터보다 유독 개수가 작음)
부가적인 분석 도출하기
추가적으로 답장이 오는 시간도 분석하여 결과를 내면 더욱 정확할 것 같다고 생각하여
답장 시간을 파싱하여 더해주는 함수를 작성해주었다.
from datetime import datetime, timedelta
def time_checker(talks, my_name, your_name):
me = []
you = []
talks = sorted(talks, key=lambda x : x.date)
for i in range(len(talks)-1):
talk1, talk2 = talks[i], talks[i+1]
date1 = datetime.strptime(talk1.date, "%a, %d %b %Y %H:%M:%S %Z")
date2 = datetime.strptime(talk2.date, "%a, %d %b %Y %H:%M:%S %Z")
time_difference = max(date1, date2) - min(date1, date2)
print()
print(time_difference)
if talk1.sender != talk2.sender:
if talk1.sender == my_name and talk2.sender == your_name: you.append(time_difference)
else: me.append(time_difference)
print()
print(me)
print()
print(you)
print()
me_sum = 0
if len(me) > 1:
me_sum = str(sum(((date - me[0]) for date in me[1:]), timedelta()))
else:
me_sum = str(me[0])
you_sum = 0
if len(you) > 1:
you_sum = str(sum(((date - you[0]) for date in you[1:]), timedelta()))
else:
you_sum = str(you[0])
print("????????????????????????")
print(me_sum)
print("///////////////////////")
print(you_sum)
print("????????????????????????")
return {"my_reply_time": me_sum, "you_reply_time": you_sum}print문이 조금 많이 찍혀있다. 여러번의 테스트를 거친 결과이다..
for문으로 대화내용을 탐색하면서 내려가서 만약 i번 대화와 i+1번 대화의 발신자가
다르다면 "답장"이라고 판단하고 시간을 계산하여 각 답장자의 시간 배열에 더해주는
로직을 구현했다.
추가적으로 대화 개수도 세어 더욱 데이터 분석할 데이터들을 여러개로 도출시켰다.
완성
백엔드에 요청을 이렇게 보내면


이렇게 응답을 주는 프로그램을 완성시켰다.
analysis time은 '나'와 상대방 두 시간을 다 더하여 1초도 넘지 않는데,
막상 걸리는 시간은 6~7초 정도 걸리는 것 같다. (빠르면 2초, 가끔 다르다)
이제 해당 로직으로 프론트엔드를 작성해볼까 한다.
추가적으로 실제 대화 내용, 즉 긴 대화 내용을 넣어보지 않았기에
혹여나 분석값이 이상하게 나올까봐 조금 걱정이 된다.
그래서 학습 모델을 조금 더 다듬어주고, 추후 프론트엔드를 설계하고
테스트를 진행하여 예외값을 더 다듬어 처리해줄 계획이다.
마무리
데이터 분석을 한번 시작해보니까 시간 가는 줄도 모르고 계속 했었다.
delta값을 구할 때에 '연관성이 없는 값'이라는 오류가 계속 떠서 새벽 3시까지
고생했다
그래도 잘 고칠 수 있어 다행이었다.
가끔씩 얕게 데이터분석으로 프로젝트를 만들어보는 것도 좋은 것 같다.
아피곤행






오... 멋진데