What is Tree?
Isolation forest는 트리기반 이상탐지 알고리즘이다. 이를 알아보기 전 먼저 기본적인 의사결정나무가 무엇인지부터 다루어보자.
의사결정나무 모델 리마인드
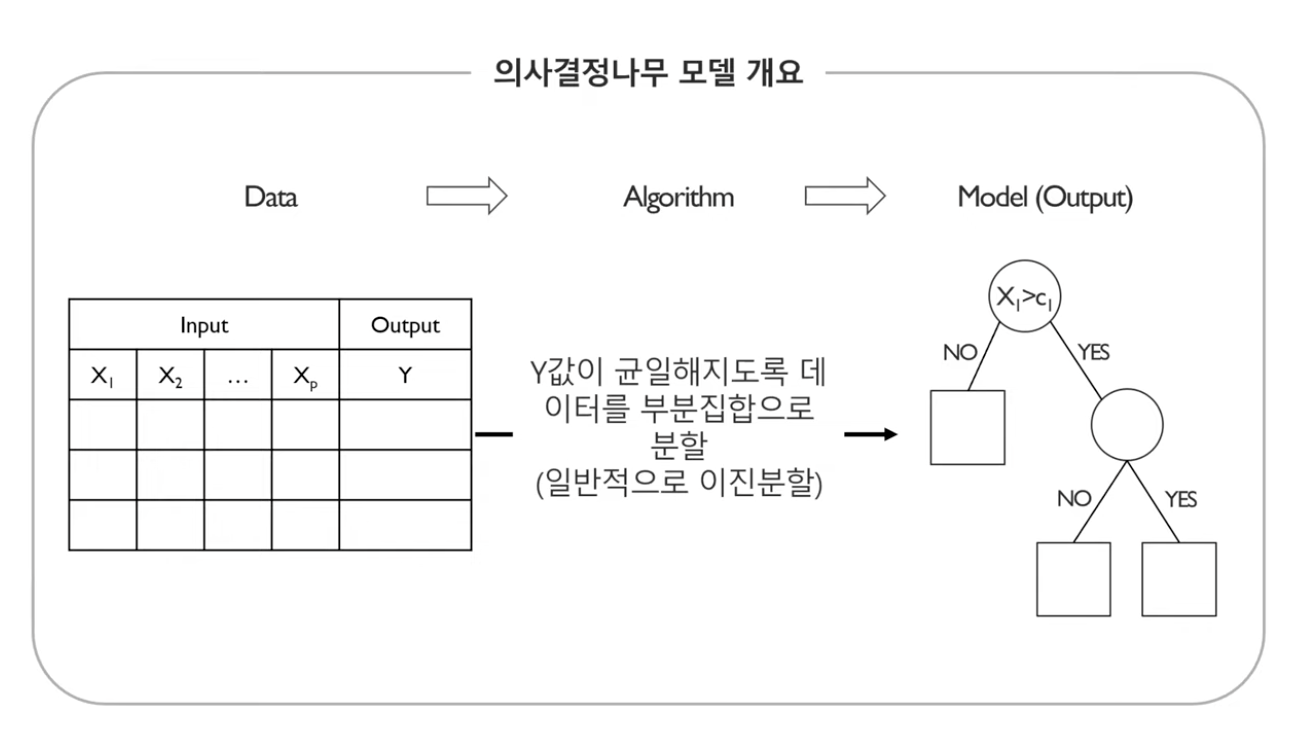
지도학습기반이므로, Y가 연속적인 Regression, Y가 범주형인 Classification 모두 해결 가능한 모델이다.- 우리는
Y가 균일해지도록이라는 말에 집중해보도록 하자.
1. 이진분류문제
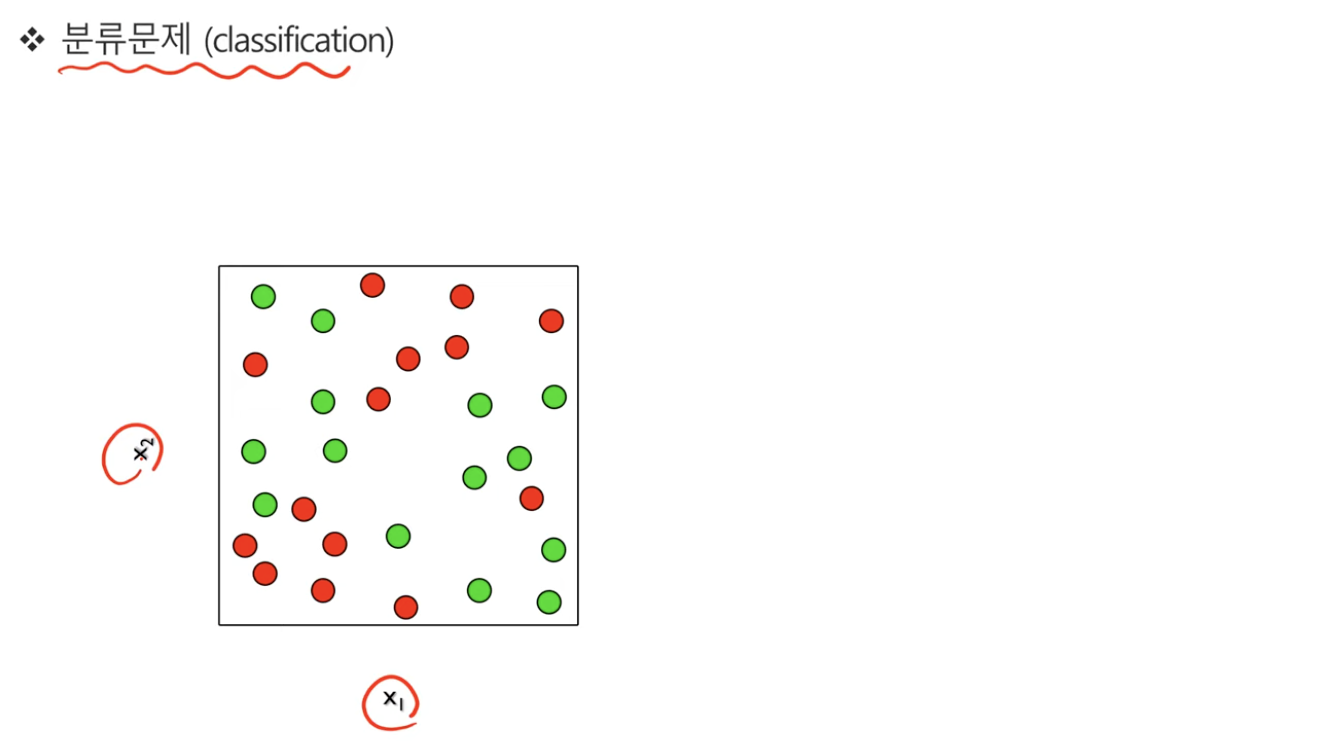
- 위 그림은 범주형 데이터이다. Y는 빨간색과 초록색이라는 값을 가질 것이다.
- 여기서 한번 절반으로 나눠보자.
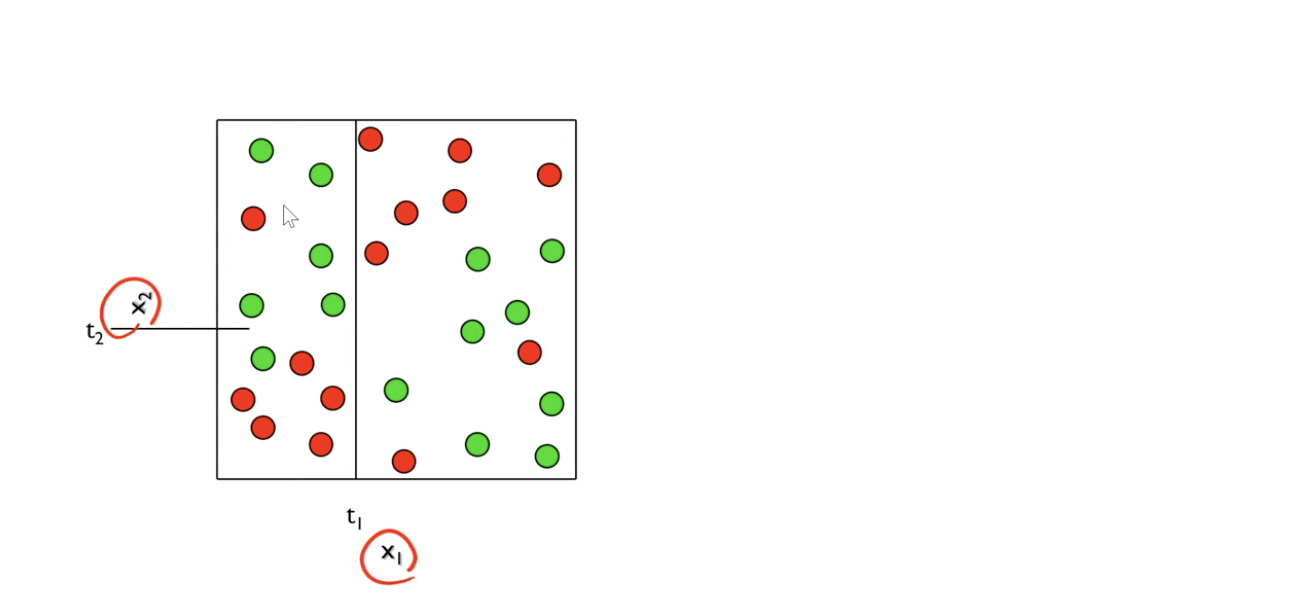
- 좀 나눠진 것 같은데, 여기서도 좀 균일하게 한번 더 나눠보자.
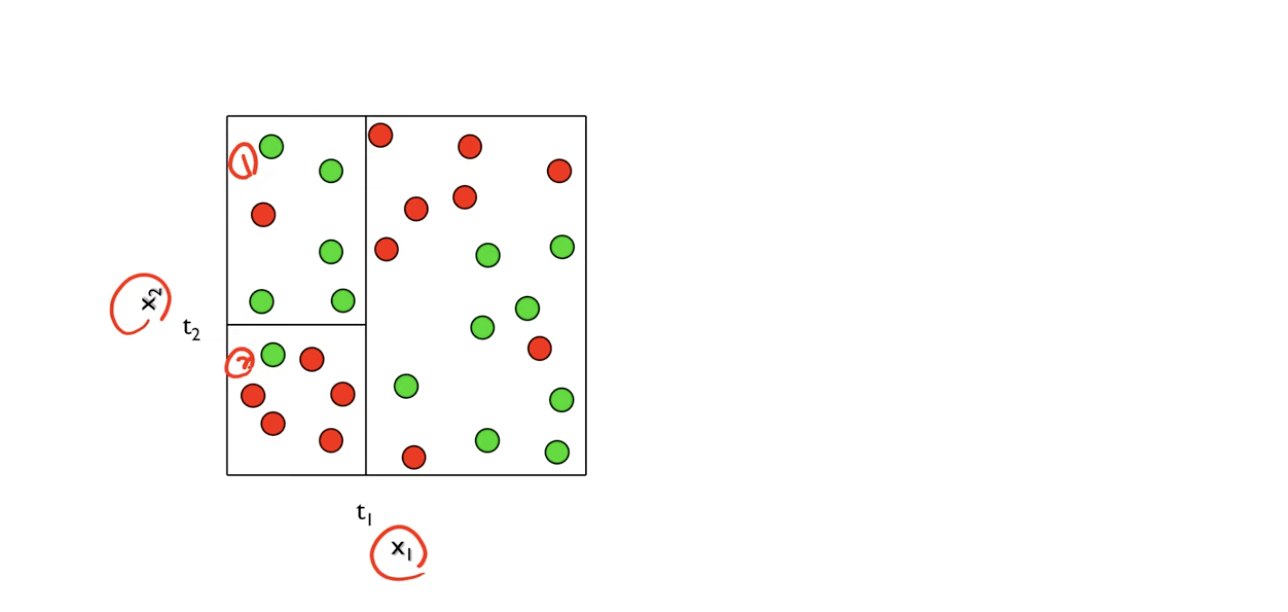
- 왼쪽을 보면 위쪽은 초록색, 아래쪽은 빨간색으로 얼추 잘 나눠진 것 같다.
- 이를 계속해서 한번 반복해보자.
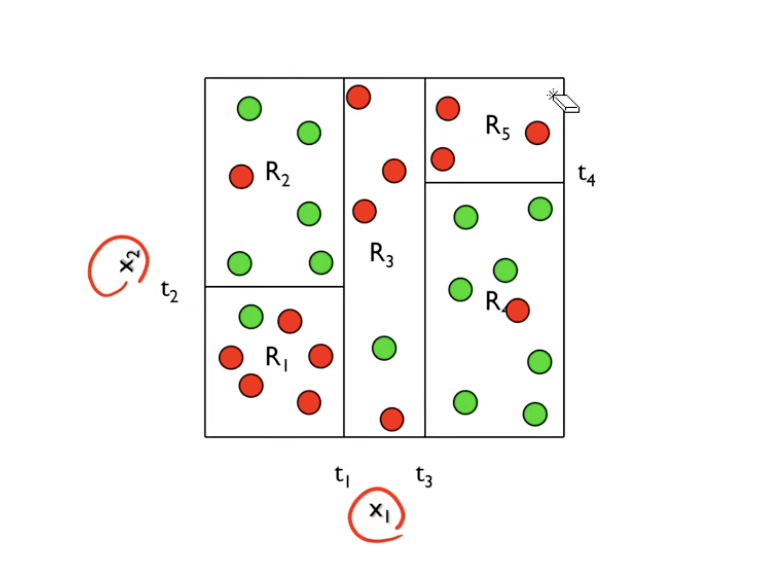
- 최종적으로 한번 5개로 나눠지게 되었다.
- 이 경우 각 부분마다 빨간색, 또는 초록색으로 잘 나눠진 것 같다.
각 지역 [R1,R2,R3,R4,R5]은 [Red,Green,Red,Green,Red]에 매치된다고 할 수 있을 것이다.
이 Y들은 어떻게 구분이 될까? 그것들은 X라는 특성들을 통해서 구분이 될 것이다. 우리는 이 그림을 트리형태로 표현할 수 있다.
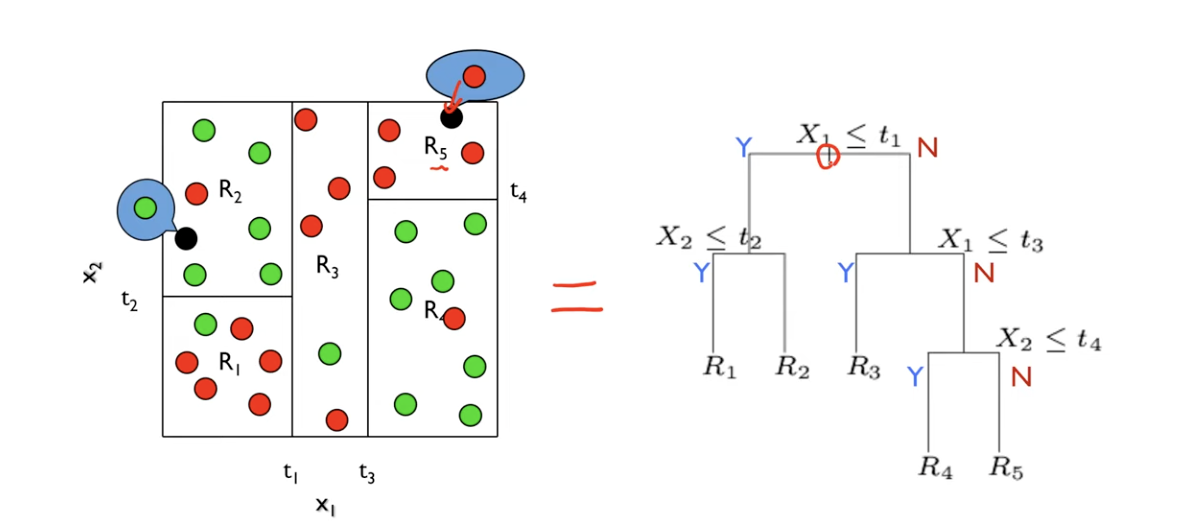
- 트리 형태로 나타나면 최종적으로 총 5개의 노드가 생긴다. 이 끝 노드들을
터미널 노드라고 부른다.
- 바로 이
터미널 노드에서 의사결정이 일어나는 것이다.(빨간색과 초록색의 분류)
- 그리고 이 마지막 노드까지 가는 과정에서,
X라는 특성들을 통해 각 점들을 분류하게 될 것이다.
트리로 어디까지 분류할 수 있을까?
- 트리의 터미널 노드의 개수는 몇개까지 분기가 가능할까? 바로
각 점들의 개수만큼 가능할 것이다. 이때를 우리는 Full grown tree라고 한다.
- 다만 이 경우에는
overfitting의 우려가 있을 것이다.
분할변수와 분할점
- 분할변수 : x중에서 어떤 x를 선택할 것인지,
- 분할점 : 선택한 x값 중에서 어떤 값을 threshold로 선택할 것인지를 뜻한다.
즉 이 두가지를 어떻게 선택할지가 분류하는데 있어서 아주 중요한 문제이다.
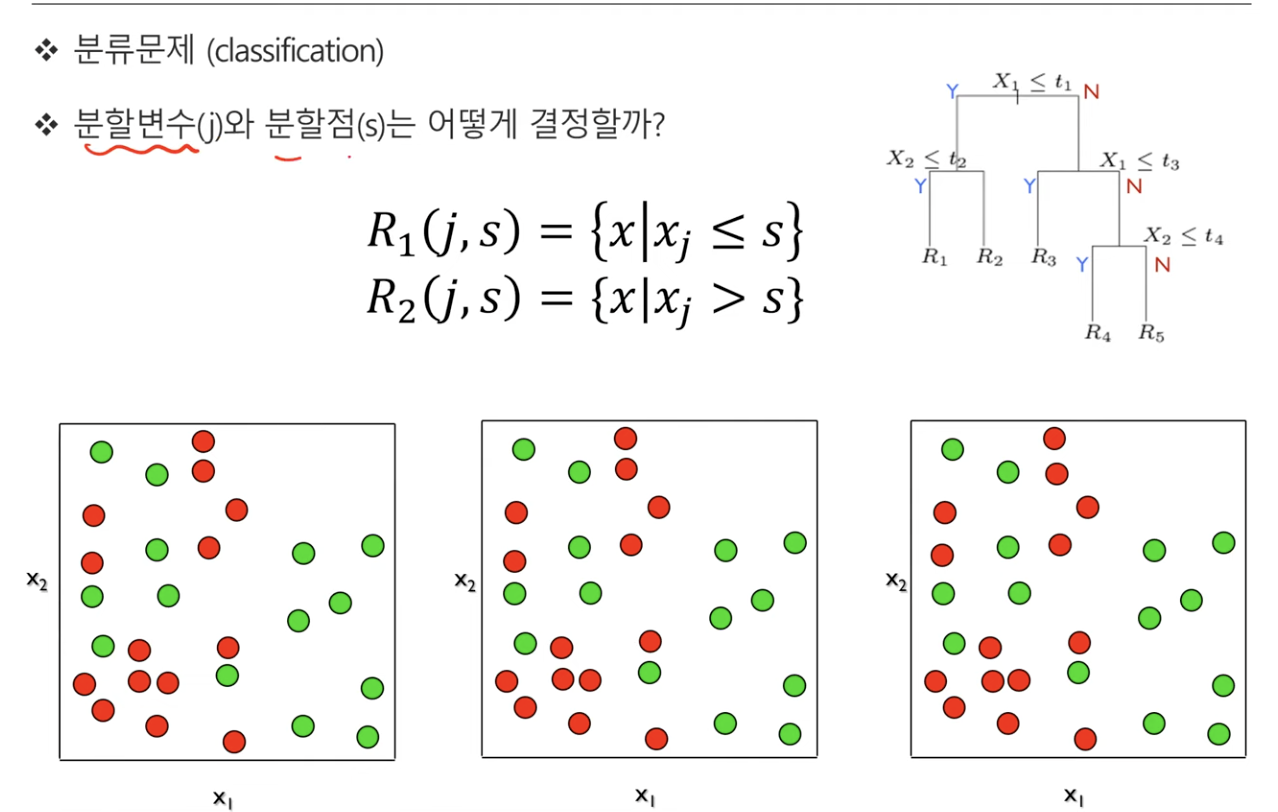
- 이 3가지 그림에서 과연 어떤 경우가 제일 잘 분류했다고 할 수 있을까?
- 사실 이건 모르는 일이다. 얼핏보면 t2가 처음에 잘 분류했다고 생각할 수 있지만, 시행이 늘어나게 되면 또 어떻게 될지 모르는 일이다.
- 어떻게 하면 Y가 균일해지는 방향일까?
이는 사람이 보고 할 수 없는 일이기 때문에, 따라서 최대한 Y의 엔트로피가 최소화되는 방향으로 분할변수와 분할점을 정하게 된다.
비용 함수
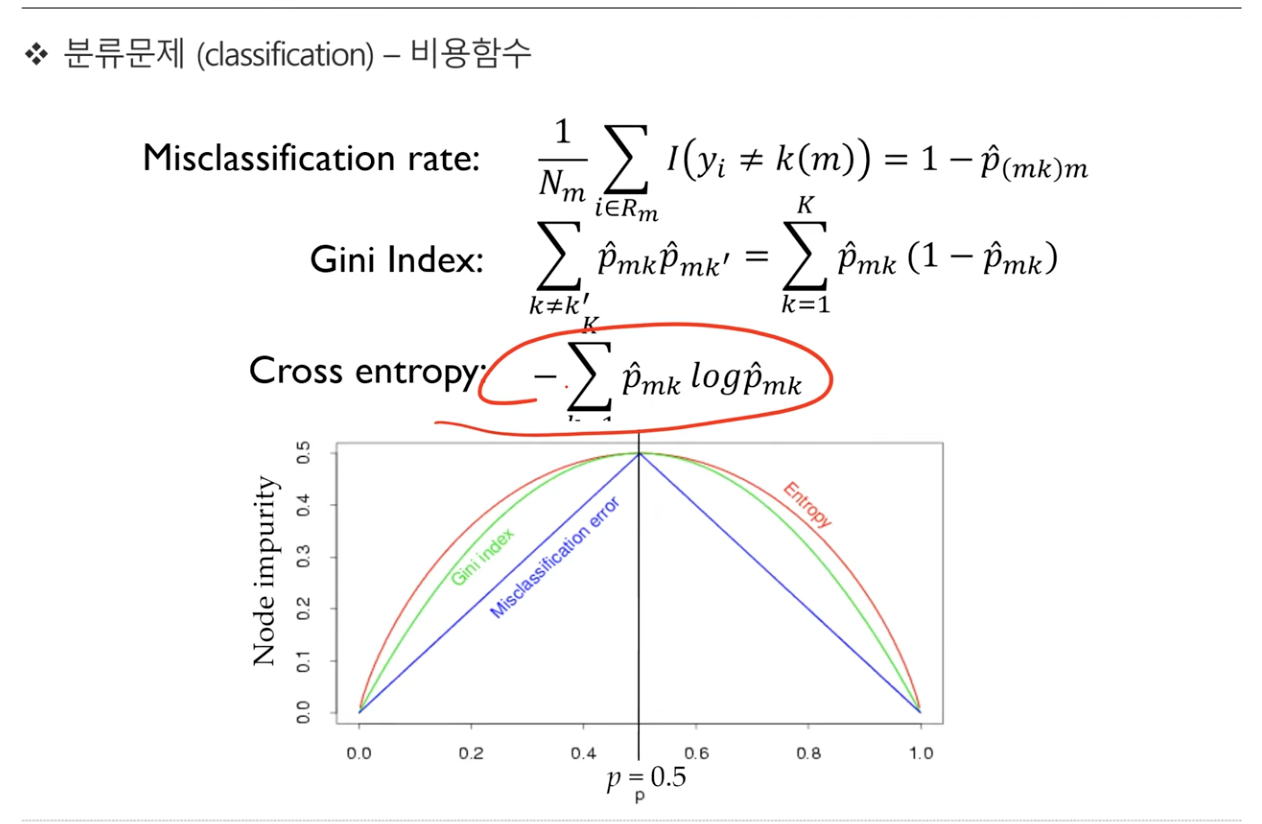
- 비용함수는 우리가 잘 알고있는 Cross entropy부터 지니불순도, Misclassification rate 관점에서 볼 수 있는데, 전부 비슷한 관점이라고 생각하면 좋을 것 같다.
Y값이 균일해지는 방향이 이 비용함수로 표현이되고, 이 비용함수를 최소화하는 방향으로 학습시키게 된다.
Regression 문제
- 이 Tree모델을 사용하면 Regression문제도 해결할 수 있다.
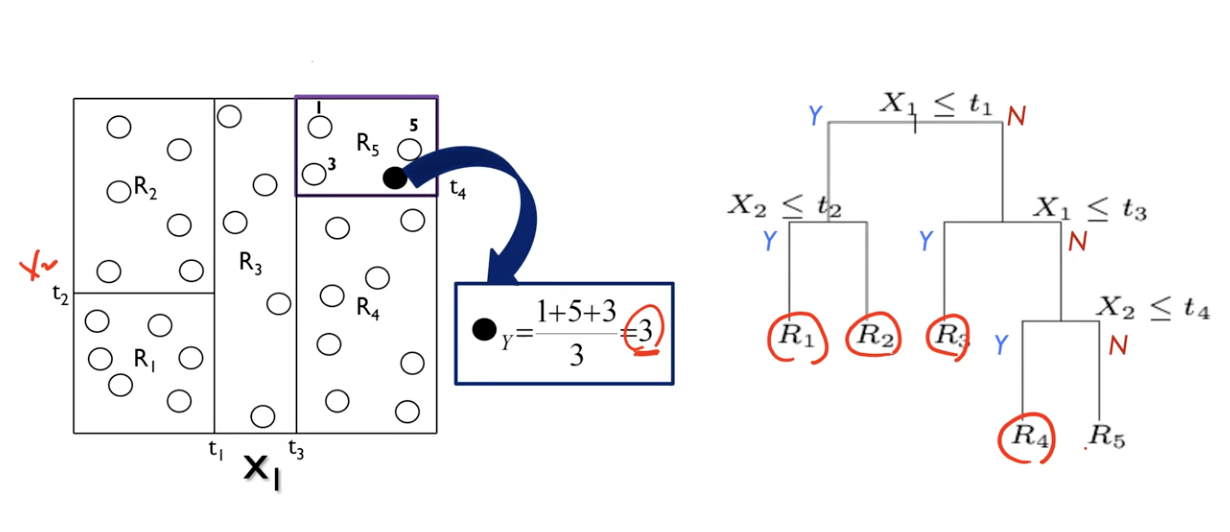
- regression 문제의 경우, 주어진 분포를 가장 잘 설명하는 모델을 만드는 것이다. 기존과 똑같이 여러개의 node를 사용해서 [R1,R2,R3,R4,R5]이라는 터미널 노드들을 만들 수 있다.
이때 각 터미널 노드에 들어가는 값은 각 터미널 노드에 해당하는 X의 Y값들의 평균값이 들어가게 된다.
- 따라서 이후 어떤 관측값이 Ri로 분류가 된다면, Ri에 해당하는
Y값들의 평균값이 관측값의 Y값이 될 것이다.
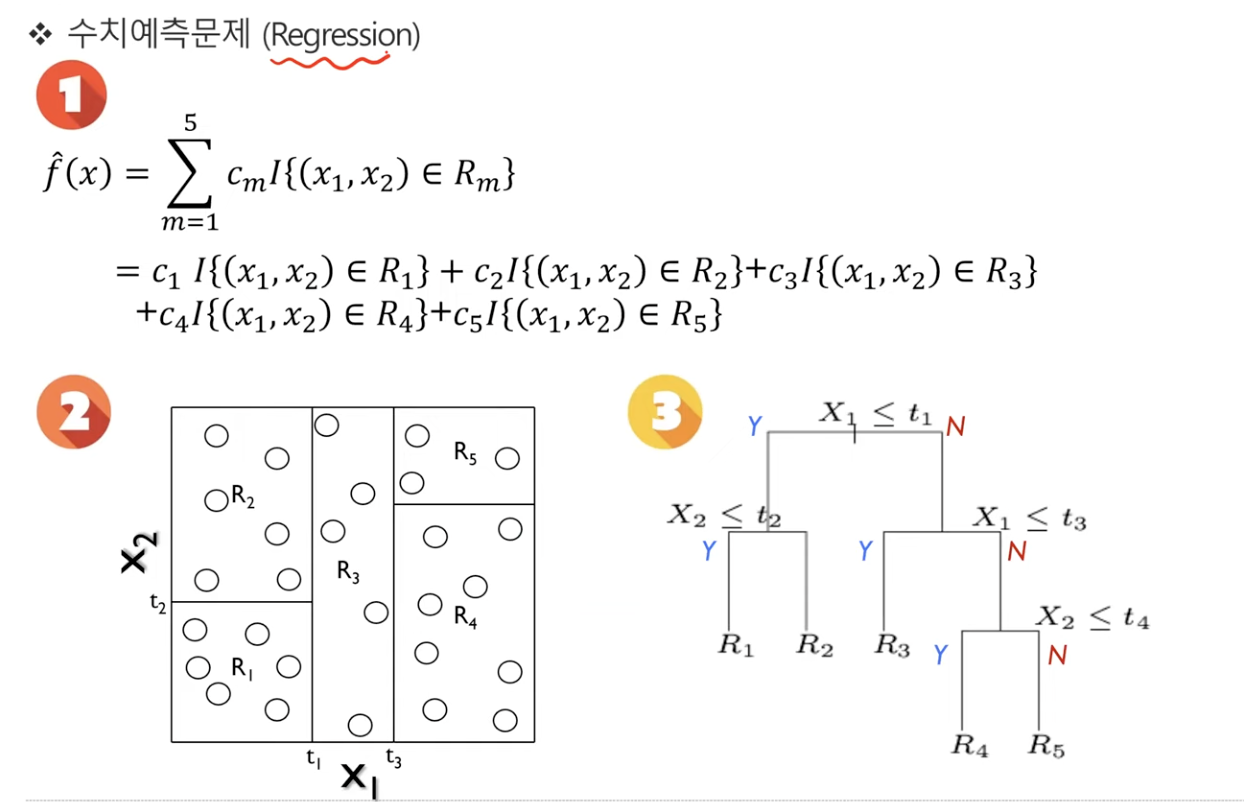
- 이 문제를 우리가 익숙한
f(x) 형태로 나타내보자.
- I 함수는 안의 조건이 True면 1, False면 0을 나타내는 함수라고 생각하면 된다.
만약 새로운 관측값 X가 R4에 포함된다면?
- c4에 해당하는 항만 1이 될 것이고, F(x)는 R4의 평균값인 c4의 값을 가지게 될 것이다.
근데 이게 왜 평균이 되어야할까?

- MSE값을 우리가 loss함수로 많이 쓰는데, 이 비용함수를 최소화하는 Cm을 찾아보면, 그게 평균을 구하는 문제가 되더라. 자연스레 도출되는 결과이다.
분할변수와 분할점 구하기
- classification에서는 y의 엔트로피가 줄어드는 방향으로 변수와 점을 선택하면 된다.
- 다만 여기는 범주가 아니라 실제 값들이다. 따라서 엔트로피가 아닌 여기서도 MSE 형식을 사용한다.
- j와 s를 계속 변경해가면서, MSE Loss의 argmin값을 구하는 것이다.
지금까지는 의사결정나무에 대해서 알아봤다. 이제 알아볼 Isolation forest의 경우 비지도, 즉 y가 없다.
Isolation forest
- 관측치를 고립시키기 위한 분리 횟수를 이상치 점수로 활용한다.
- 이상치라면 멀리 떨어져있기 때문에 분리 횟수(path length)가 작을 것이다.(금방 분리될 것이다.)
정상 노드는 분리하기 어렵다

- 여기서 파란색 노드를 고립시키려면, 몇번을 분리해야할까?
- 이 노드는 주위에 노드들과 뭉쳐있기 때문에 고립시키려면 적어도 4번 이상의 분리 과정을 거쳐야할 것이다.
이상치 노드는 분리되기 쉽다
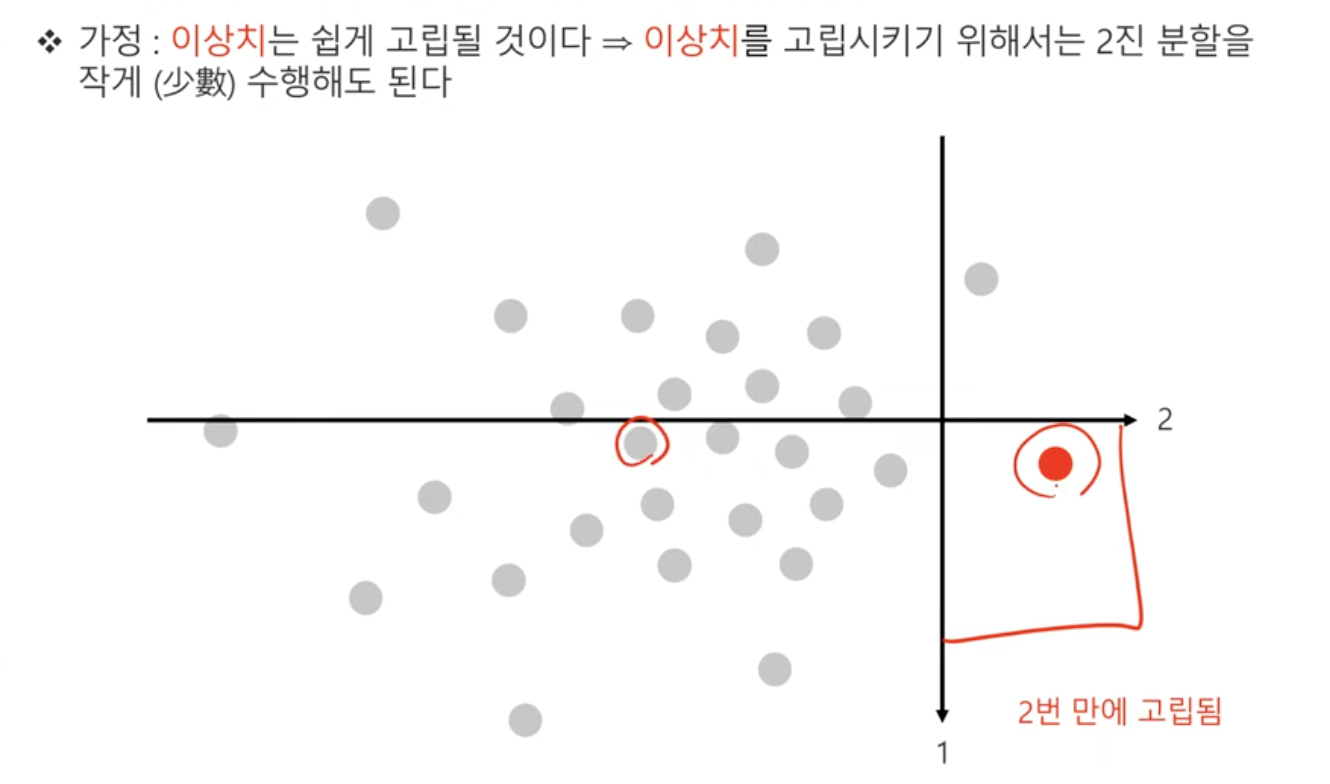
- 지금 이 상태를 보면, 바로 2번의 분리 과정을 거쳐 이상치를 탐지하게 된다. 즉, 빠르게 고립되는 것이 이상치인 것이다.
isolation forest는 이 분리 횟수를 이상치 점수로 활용하겠다.
그럼 분할변수와 분할점을 어떻게 선택할까?
- 의사결정나무에서는 Y의 엔트로피를 줄이는 방향, 또는 MSE Loss가 최소가 되는 분할변수와 분할점을 선택했다.
- 다만 Isolation Forest 같은 경우는
Y레이블을 전혀 사용하지 않는다.
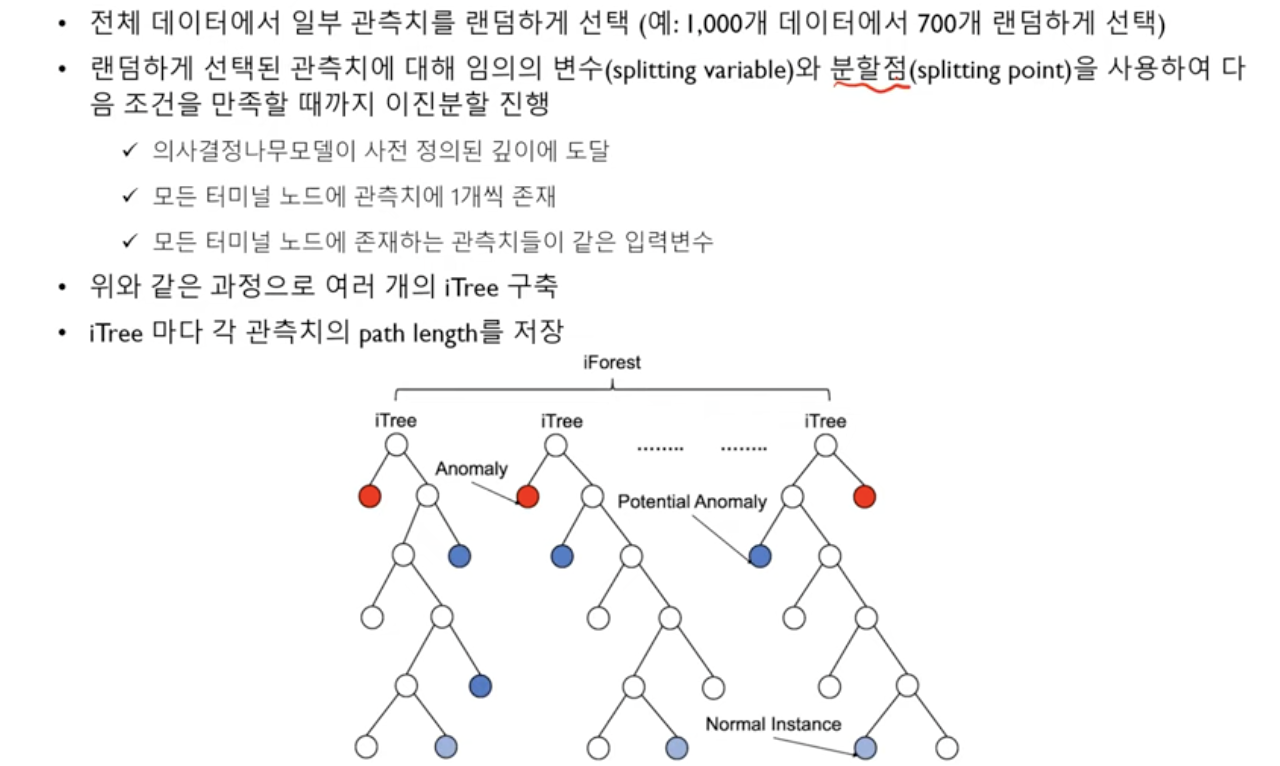
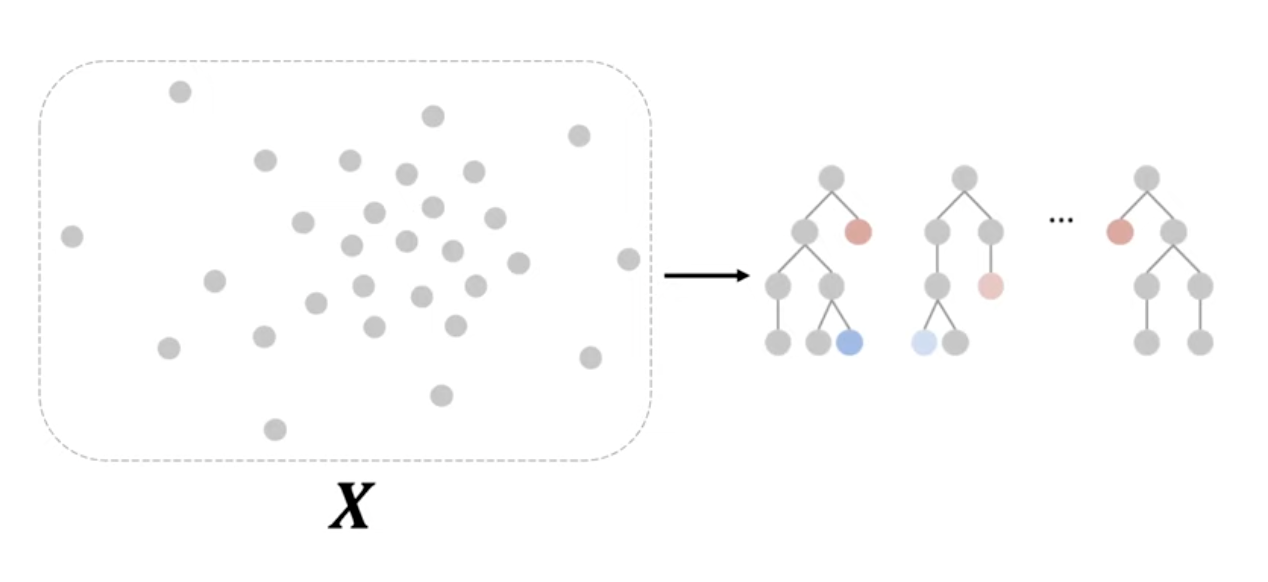
- 따라서 그냥 랜덤으로 나눠버리자! 임의로 몇개의 관측치를 랜덤으로 뽑아서, 임의의 조건을 만족할때까지 한번 트리를 만들어보자는 것이다.
- 이렇게 여러번의 트리가 만들어질 것이고, 이것들은 iTree 라고 불린다. 이 iTree들은 모든 터미널 노드에 관측치가 하나씩 있는 full Tree여야한다!
- 이런 iTree들을 여러개 만들어서, 각 트리마다 관측치의 path length를 구하고 이를 평균내는 방법으로 iForest 모델을 구축한다.
이상치 스코어 정의
- 그러면 우리는 path length가 작은 관측치가 이상치구나!라고 간단하게 생각해볼 수 있을 것이다.
- 다만 path length에는 간과해선 안되는 특징 있다. 바로 Path length는
0부터 무한대까지 존재할 수 있다는 점이다.

- 최종적으로 Anomaly score는 지수형태로 표현된다.
- E(h(x)) = 관측치 1개에 대한 Path length의 평균(여러개의 itree이기 때문)
- c(n) = 모든 관측치들의 평균 path length
이 두가지 식을 통해서 Anomaly score를 최종적으로 normalization한다.
s(x,n)=2−c(n)E(h(x))
E(h(x)) -> 0
- c(n)E(h(x))가 작으면?
- 20에 가까워지므로 1에 가까움. 이상 데이터.
E(h(x)) -> n-1
- c(n)E(h(x))가 1에 가까우면?
- 2−1에 가까워지므로 0.5에 가까움. 정상 데이터.
E(h(x)) -> c(n)
- c(n)E(h(x))가
- 2−큰수에 가까워지므로 0에 가까움. 정상 데이터.
