LOF(Local Outlier Factor)
Intro
- 이번 게시물에서는 학부연구생 활동 중에 사용하고 있는 사이킷런에서 제공하는 세가지 이상탐지 머신러닝 알고리즘,
LOF, Isolation forest, OC-SVM에 대해서 알아보고, 정리한 내용을 적어보려고 한다.
- 내용은 고려대학교 김성범 교수님 : 핵심 머신러닝 영상을 참고하며 공부했다.
LOF(Local Outlier Factor)
- LOF는 밀도 기반 이상탐지 알고리즘이다.
- 보통 이상치라고 여겨지는 것들은 기존 정상 element들의 분포와는 동떨어져있을 것이라고 가정하고, 정상 데이터들은 밀집되어 있을 것이라는 것을 가정한다.

먼저 LOF를 이해하기 위한 정의들을 알아보자.
1. K-distance of object P
- K-distance는 자기 자신 P를 제외하고 K번째로 가까운 이웃과의 거리를 뜻한다.
2. K-distance neighborhood of object p (Nk(p))
- 이번엔 거리가 아니라
개수로 표현한다.
- K번째로 가까운 이웃과의
거리를 원으로 표현한다면, 그 안에 포함되는 모든 요소들의 개수를 나타낸다.
ex)
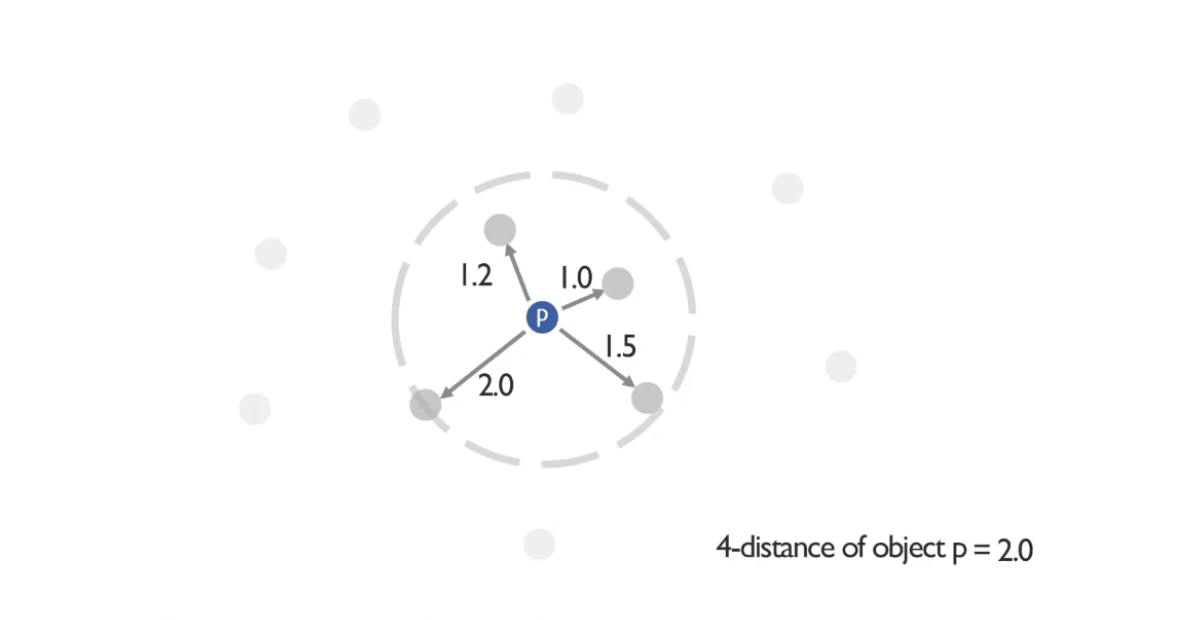
- 이 그림에서 K=4일때, k-distance는 2.0이 될 것이다.
- 4-distance of p = 2.0이므로, 그 안에 들어있는 요소들의 개수 (Nk(p)) = 4
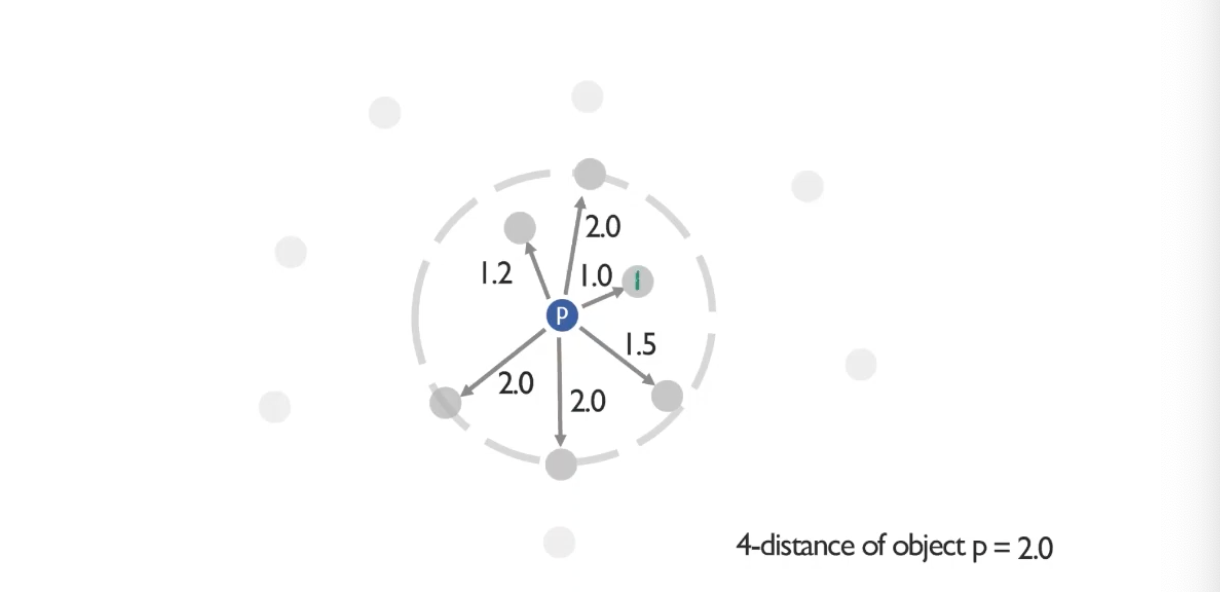
- 이 그림에서는 P로부터 3,4,5번째 거리가 모두 2.0이다. 그래도 4번째로 먼 거리는 2.0이라고 할 수 있겠다.
- (Nk(p)) = 6
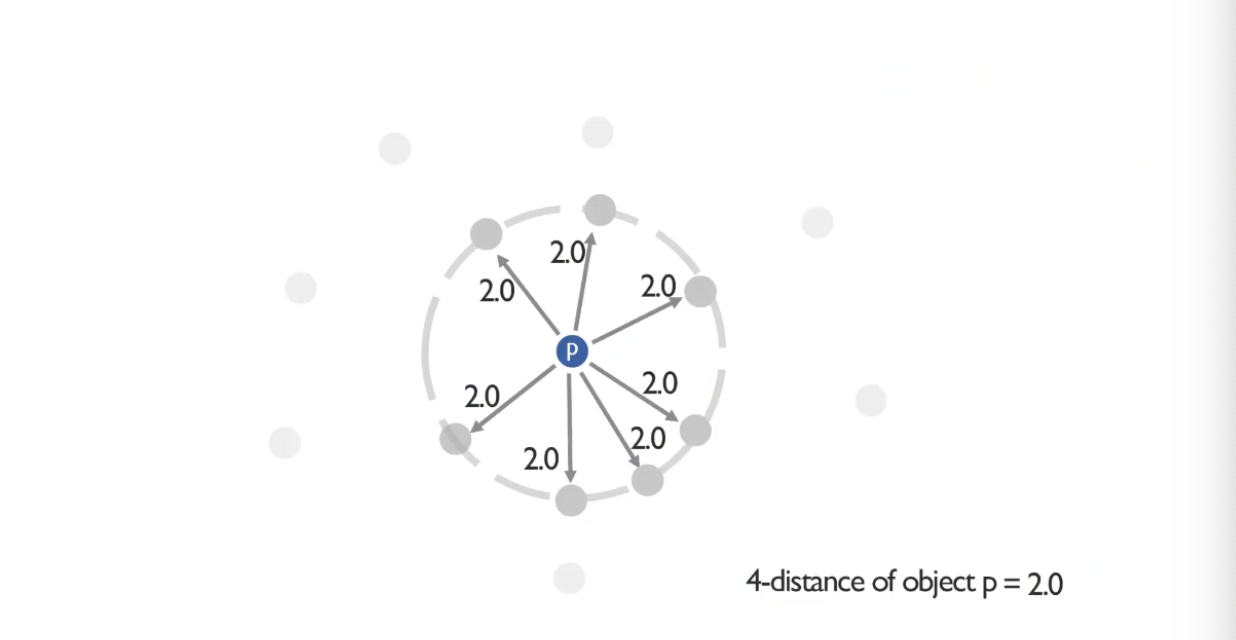
- 이런 경우는? 똑같이 정의에 충실하게 4번째로 먼 거리는 2.0이 될 것이다.
- (Nk(p)) = 7
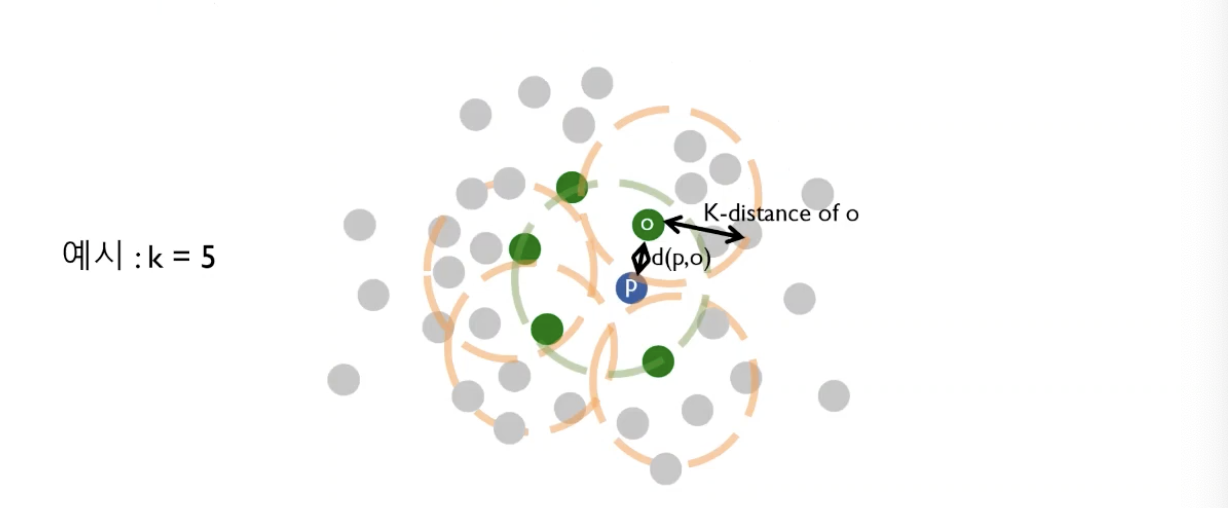
3. ReachabilityDistancek(p,o)
o를 기준으로 k번째 가까운 이웃과의 거리(k-distance of o)와 o와 p사이 거리 $d(p,o)$ 간의 최대값이다.- 우리가 계속 기준으로 가지던
p가 아닌, o라는 점을 기준으로 한 k-distance를 구하고, 그 거리와 p와 o 사이의 거리를 구한다음, 그중에서 큰 값이 Reachability Distance가 된다.
ex) 점들이 오밀조밀 모여있을때
- 여기서 보면 P를 기준으로 보았을때, 많은 점들이 밀집되어 있기 때문에,
$d(p,o)$는 짧을 것이다.
- 동시에
K-distance of o역시도 짧을 것이다.
이런 경우, 최종 Reachability Distance는 굉장히 짧을 것이라고 예상할 수 있겠다.
점들이 모여있지 않을때
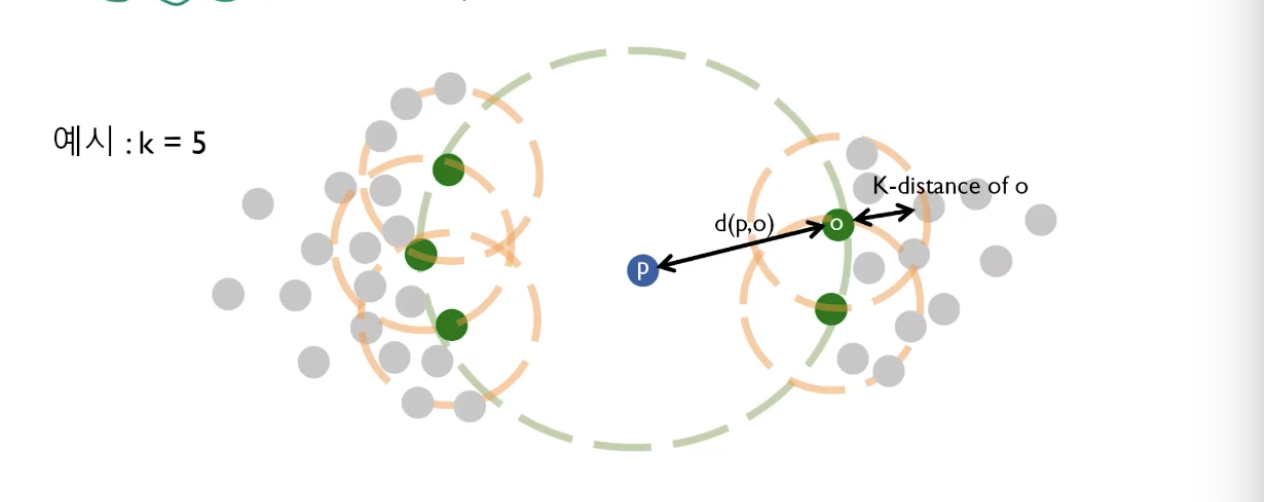
- 여기선
p가 혼자 동떨어져있다.
- 그러면
$d(p,o)$ > K-distance of o 일 확률이 굉장히 높을 것이다.
이런 경우, 최종 Reachability Distance는 굉장히 길 것이라고 예상할 수 있겠다. P가 이상치일 확률이 높다는 것이다.
4. Local reachability density of object p (lrdk(p))
- 우리가 세번째로 정의한 Reachability Distance의 역수라고 생각하면 된다.
- 간단하게 생각해서 밀집되어 있으면 크고, 밀집되지 않으면 작다라는 것.
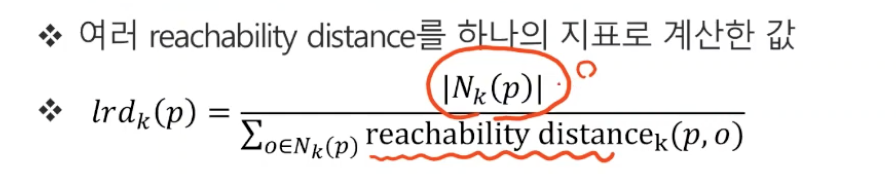
- Nk(p)는 두번째로 정의한 점들의 개수이다. 이는 여기서 weight로 작용한다.
(lrdk(p))는 Reachability Distance와 역수 관계 !
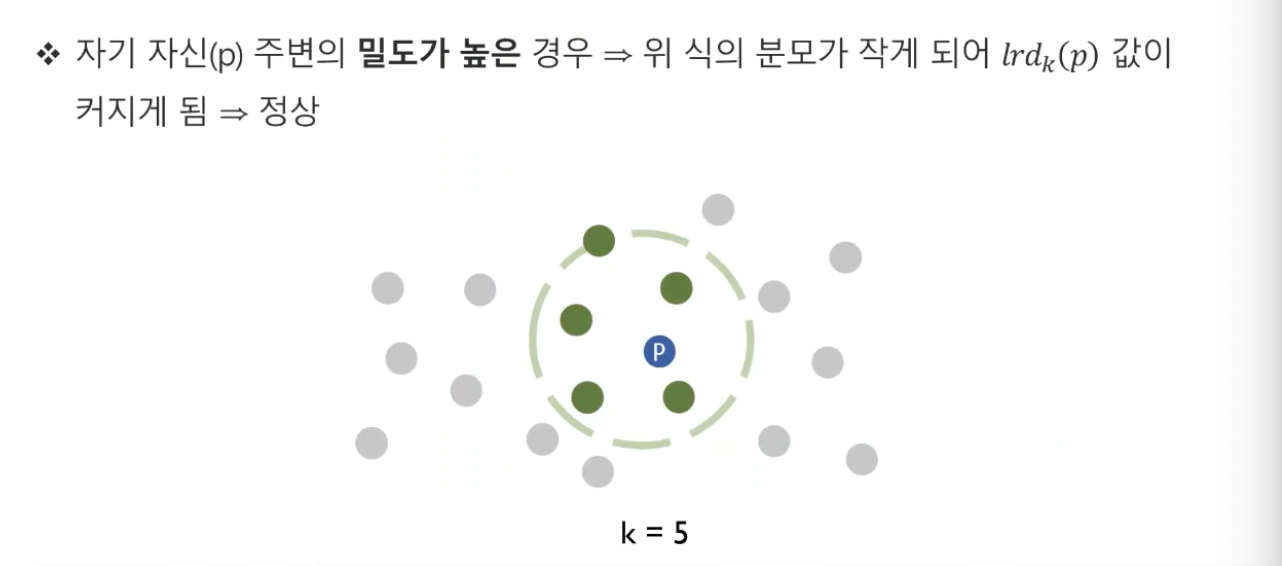
- 즉 밀도가 높을수록(정상치)
Reachability Distance가 작기 때문에, (lrdk(p)) 값은 커지게 될 것이다.
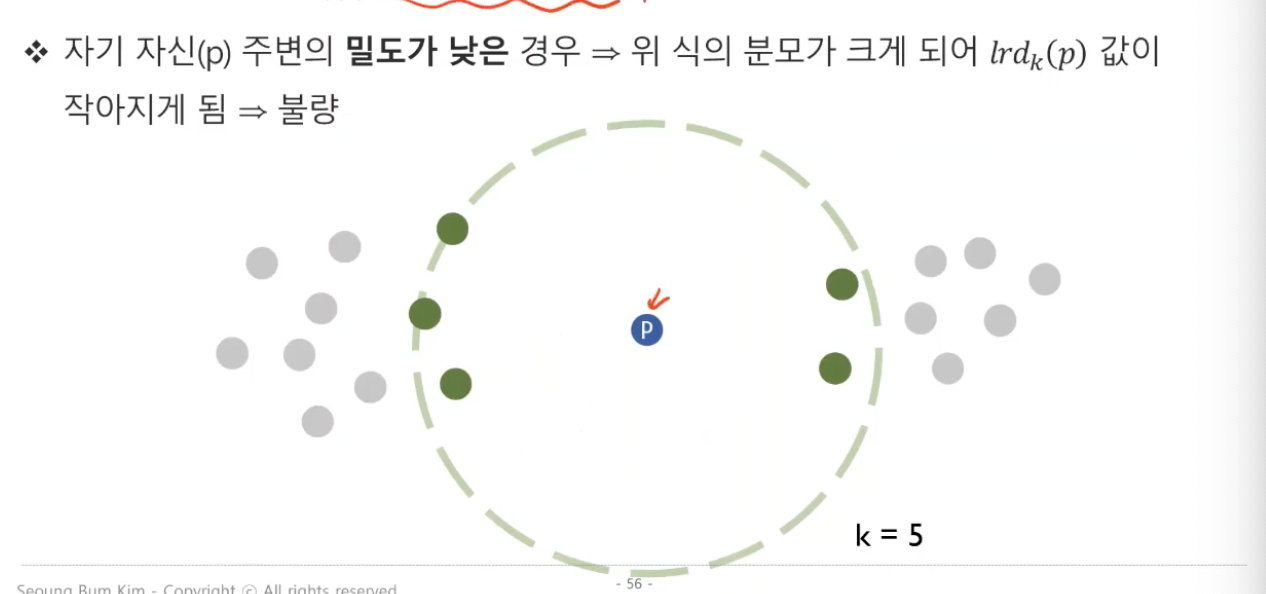
- 반대로 밀도가 낮을수록(이상치),
Reachability Distance가 크기 때문에, (lrdk(p)) 값은 작아지게 될 것이다.
5. 최종 LOF score
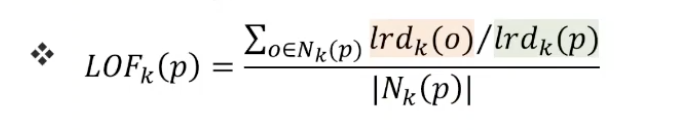
- (lrdk(p))와 (lrdk(o))의 값을 중점적으로 최종 score를 산출하게 된다. 예시를 보면서 이해하는 것이 좋겠다.
p와 o 주변 밀도가 모두 높은 경우
- 이 경우에는 (lrdk(p))와 (lrdk(o)) 둘다 큰값이 될 것이다.
- 따라서 LOF score는 1에 가까운 값이 나올 것이다.
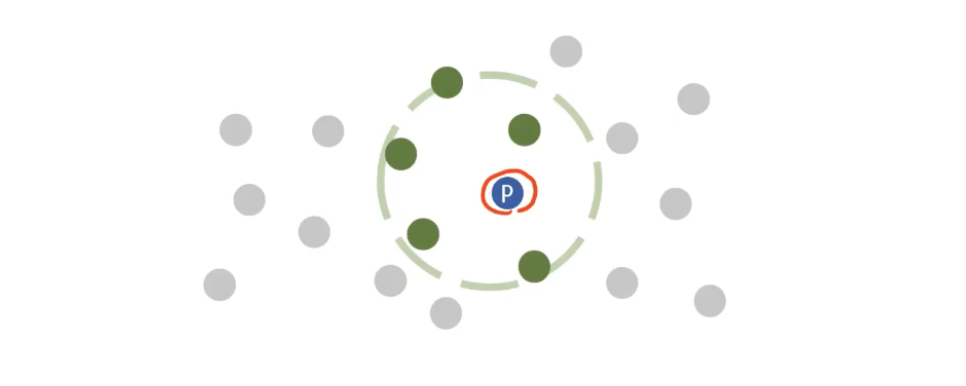
p주변 밀도가 낮고 o 주변 밀도가 높은 경우(이상치일 경우!)
- 이때는 (lrdk(p))는 작은 값이지만, (lrdk(o))는 큰값이 될 것이다.
- 따라서 LOF score는 아주 큰 값이 나올 것이다.
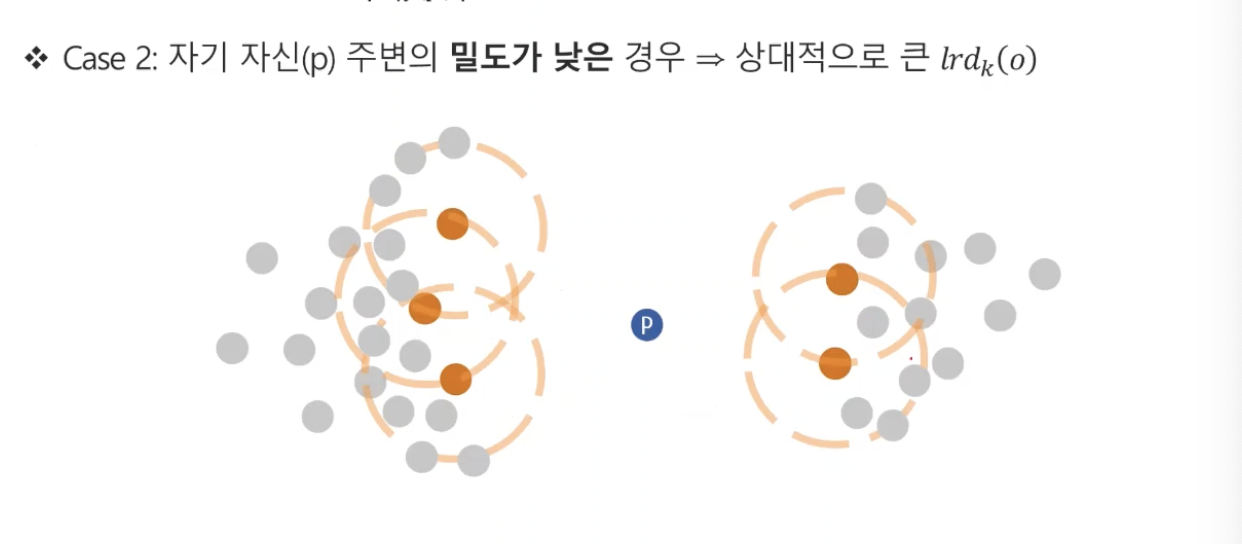
p와 o 주변 밀도가 모두 낮을 경우(헷갈리지만 정상인 경우.)
- 이 경우는 아주 헷갈릴 수 있지만, 정상치라고 꼭 분포가 몰려있는 것은 아니다.
- 균일한 거리를 유지하는 분포를 가지는 것도 정상치라고 여길 수 있을 것이다.
- 이 경우에는 (lrdk(p))와 (lrdk(o)) 둘다 작은 값이 나오게 될 것이다.
- 따라서 1번의 예시와 같이 LOF score는 1근방에서 나오게 될 것이다.
(lrdk(p)) 만 쓰면 되지 않을까?
- 4번째로 정의했던 (lrdk(p))으로도 충분히 anomaly score를 정의할 수 있을 것 같지만,3번째 예시처럼 거리가 멀지만 정상인 경우도 존재한다.
- 그렇기 때문에 (lrdk(p))와 (lrdk(o)) 두가지 경우를 모두 고려해야 하는 것이 좋다.
LOF의 한계점은 무엇일까?(중요)
K를 어떤 값으로 정할지
- 이건 하이퍼파라미터이기 때문에, 어떻게 하면 좋을지.. 너무 값을 크게 해버리면 문제가 생길수도 있다.
threshold의 문제
- score까지는 오케이. 근데 어떻게 하면 합리적인 threshold를 정의할 수 있을까? 이게 아주 중요한 문제이다.
- 보편적으로
비율로 정하는 방법이 있겠다. 다만 이것 역시 하이퍼파라미터..
데이터셋마다 다른 기준
- 같은 LOF score를 가져도 그게 데이터셋마다
anomaly일수도, normal일수도 있다.
계산복잡도 문제
- 거리기반이기 때문에 계산복잡도가 아주 복잡하다. KNN 기반의 알고리즘의 고질적인 문제이다.
고차원이라면?
- 2차원이라면 직관적으로 괜찮지만, 고차원일수록 일반적인 거리 기법들이 정확하게 나오지 않게 된다.
