
개요 🦜️🔗
LangChain은 LLM을 사용하여 애플리케이션을 구축하기 위한 오픈 소스 프레임워크이다. 다양한 컴포넌트를 연결(chain)하여 LLM을 쉽게 다룰 수 있도록 하는 것이 핵심 목적이다.
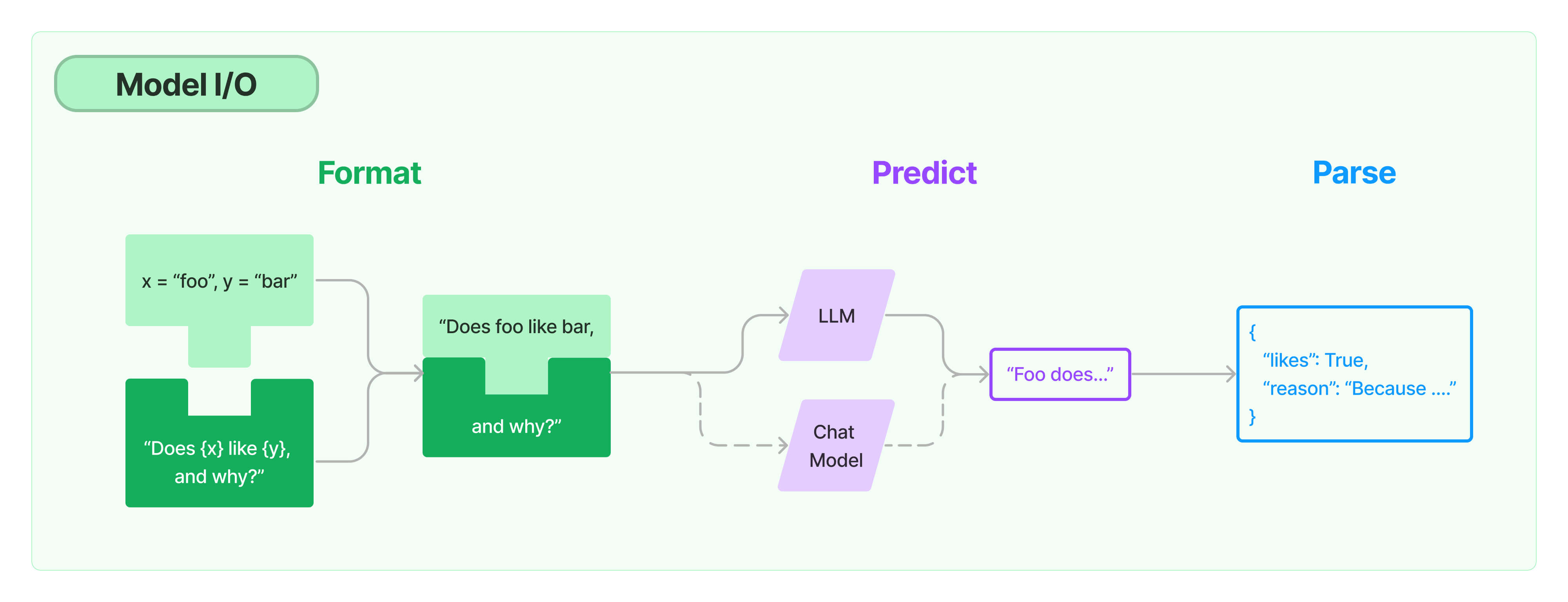
LangChain을 사용하여 챗봇을 만들어보자.
본 포스트에서는 LangChain의 여러 기능 중 Model I/O에 중점을 둔다.
코드
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
llm = ChatOpenAI(temperature=0.1)
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=80,
memory_key="chat_history",
return_messages=True,
)
def load_memory(input):
print(input)
return memory.load_memory_variables({})["chat_history"]
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI talking to human"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
chain = RunnablePassthrough.assign(chat_history=load_memory) | prompt | llm
def invoke_chain(question):
result = chain.invoke({"question": question})
memory.save_context(
{"input": question},
{"output": result.content},
)
print(result)
invoke_chain("My name is nam.")
invoke_chain("What's my name?")
출력:
{'question': 'My name is nam.'}
content='Hello Nam! How can I assist you today?'
{'question': "What's my name?"}
content='Your name is Nam.'LLM
llm = ChatOpenAI(temperature=0.1)
렝체인은 다양한 LLM을 제공한다. 여기서는 ChatOpenAI를 사용하였다. ChatOpenAI는 기본적으로 gpt-3.5-turbo 모델을 사용한다.
파라미터
- temperature: 다양성 정도를 의미한다. 값이 클 수록 창의적으로, 작을 수록 정확한 결과를 반환한다. 0.1~1.0 사이의 값을 전달할 수 있다.
Memory
memory = ConversationSummaryBufferMemory( llm=llm, max_token_limit=80, memory_key="chat_history", return_messages=True, )
대화를 기억하고 맥락을 이해하기 위해서는 대화 내용을 저장해야 한다. 이 때 memory를 사용한다. 메모리 용량이 과도하게 커지면 모델에 전달하는 Prompt의 길이도 길어지기에 적절한 메모리를 선택할 필요가 있다.
LangChain에서 제공하는 메모리는 다음과 같은 것들이 있다.
- Conversation Buffer: 그동안의 모든 대화를 저장한다. 대화가 길어질 수록 메모리 용량이 증가한다는 점이 단점이다.
- Conversation Buffer Window: 마지막 k개의 대화만 저장한다. 최근 대화만 저장하기에 메모리 용량이 과도하게 늘어나지 않는다는 장점이 있지만, 이전 내용을 잊게 된다는 단점이 있다.
- Conversation Summary: LLM을 사용하여 대화 내용을 요약하며 저장한다.
- Conversation Summary Buffer: max_token_limit을 초과할 경우에 요약하여 저장한다. Buffer Window와 Summary의 결합이다.
- Conversation Knowledge Graph: 대화 속 주요 entity를 추출해 지식 그래프(knowledge graph)를 생성한다.
그 외에도 여러 메모리가 있다.
여기서는 Conversation Summary Buffer를 사용하였다.
파라미터
- llm: 요약을 하며 메모리에 저장하기에 llm이 필요하다.
- max_token_limit: 토큰 수가 80을 넘어가면 요약한다.
- memory_key: 메모리에 "chat_history"라는 키로 대화를 저장한다. Default 값은 history이다.
- return_messages: True로 설정 시 각 메시지를 딕셔너리로 저장한 리스트를 반환한다. False로 설정 시 string으로 반환한다. Default 값은 False이다.
load_memory
def load_memory(_): return memory.load_memory_variables({})["chat_history"]
후술할 RunnablePassthrough을 사용하여 chain을 만들 때 메모리의 채팅 기록을 반환하는 함수가 필요하다. chian을 invoke() 하였을 때 값이 자동으로 전달되기에 input을 반드시 선언해야 한다. 여기서는 필요하지 않으므로 언더바_로 값을 무시한다.
Prompt
prompt = ChatPromptTemplate.from_messages([ ("system", "You are a helpful AI talking to human"), MessagesPlaceholder(variable_name="chat_history"), ("human", "{question}"), ])
LangChain에서 제공하는 ChatPromptTemplate를 통해 프롬프트 엔지니어링을 쉽게 수행할 수 있다.
템플릿을 만들어 두고, 상황에 맞게 원하는 템플릿을 사용할 수 있다. ChatPromptTemplate의 메서드로는 from_template()과 from_messages()가 있다.
프롬프트를 생성할 때 중괄호{ } 사이에 변수명을 넣어 사용한다. 생성된 프롬프트는 format() 메서드를 통해 인자로 파라미터 이름으로 변수명을, 값으로 내용을 전달하여 완성할 수 있다. (return type: str)
from_template()
예시 코드:
template = """
You are a helpful AI talking to human
{message}
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt.format(message="hi"))출력:
You are a helpful AI talking to human
hi템플릿을 str 타입으로 전달할 때 사용한다.
from_messages()
예시 코드:
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI talking to human"),
("human", "{question}"),
])
print(prompt.format(question="hi"))출력:
System: You are a helpful AI talking to human
Human: hi메시지 형태로 프롬프트를 작성할 때 사용할 수 있다. 튜플 형태로 메시지를 전달한다.
MessagesPlaceholder()
MessagesPlaceholder(variable_name="chat_history"),이 곳에 대화 기록이 포함된다. 메모리의 chat_history키를 조회한다.
Chain
chain = RunnablePassthrough.assign(chat_history=load_memory) | prompt | llm def invoke_chain(question): result = chain.invoke({"question": question}) memory.save_context( {"input": question}, {"output": result.content}, ) invoke_chain("My name is nam.") invoke_chain("What's my name?")
LangChain의 핵심 기능이다. LangCahin은 LCEL(LangChain Expression Language)을 통해 여러 컴포넌트들을 묶을 수 있는 기능을 제공한다. 이는 리눅스의 pipline과 유사한 문법 형태로, 반환 값을 다음 컴포넌트의 입력 값으로 전달할 수 있도록 해 준다. 또한 LCEL은 streaming이나 비동기적 작동, 병렬 실행 등의 이점이 있다.
invoke_chain()
chain을 실행하여 llm으로부터 결과 값을 받고 메모리에 저장하는 함수이다.
chain.invoke()
chain을 호출하는 메서드이다. 여기서는 인자값으로 prompt에 전달될 변수명을 이름으로, 내용을 값으로 전달한다. llm의 반환값이 최종 반환값이 된다.
memory.save_context()
메모리에 기록을 수동으로 직접 저장하는 메서드이다.
체인의 흐름
chain = RunnablePassthrough.assign(chat_history=load_memory) | prompt | llm
LangChain의 핵심 기능인 Chain을 이해하는 것은 매우 중요하다. 값이 전달되는 흐름은 다음과 같다.
chain.invoke({"question": question})를 통해 사용자의 질문을 question키로 전달한다.- RunnablePassthrough(): 앞에서 전달받은 값을 변경 없이, 또는 다른 키를 추가하여 다음 컴포넌트로 그대로 전달한다. 여기서는 chat_history키에 대한 값으로 load_memory를 호출한 반환값을 전달하였다.
- prompt를 완성한다. 위 프롬프트를 완성하기 위해서는 question과 chat_history 두 키가 필요하다.
- 완성된 프롬프트가 llm로 전달되고, llm으로부터의 반환값이 최종 반환값이 된다.
off-the-shelf chain
미리 만들어진 off-the-shelf chain을 사용한다면 더 쉽게 사용할 수 있다. 단, 이는 Legacy이므로, 앞선 LCEL로 직접 구현한 방식이 권장된다.
chain = LLMChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True
)
chain.predict(question="My name is Nam")
chain.predict(question="What is my name?")위에 방식의 LCEL을 사용한 chain과 동일하게 작동한다. 메모리 저장 또한 자동으로 이루어진다. 간단하지만 작동 방식이 모호하고 커스텀하기 어렵다는 단점이 있다.
파라미터
- verbose: True로 설정 시 콘솔에 로그가 출력된다. 디버깅 시 사용된다.
출처 및 참고자료
https://python.langchain.com/docs
https://github.com/nomadcoders/fullstack-gpt

https://nomadcoders.co/fullstack-gpt