LLM, 양보다 질? 단 1,000개의 데이터로 GPT-4와 경쟁한 LIMA 이야기
개발자 커뮤니티에서 거대 언어 모델(LLM)은 늘 뜨거운 주제입니다. 우리는 흔히 ChatGPT와 같은 강력한 AI를 만들기 위해선 수백만, 수천만 개의 방대한 데이터와 복잡한 강화 학습(RLHF)이 필수라고 생각합니다. 그런데 만약 이 통념을 뒤집는 연구가 있다면 어떨까요?
"더 적은 것이 더 낫다(Less Is More)"는 도발적인 제목의 LIMA 논문은 바로 그 질문에 대한 답을 제시합니다. 이 논문은 단 1,000개의 엄선된 데이터만으로도 최첨단 모델과 경쟁할 수 있는 LLM을 만들 수 있음을 보여주며, 우리에게 LLM 튜닝의 본질에 대해 다시 생각하게 합니다.
이 글에서는 LIMA 논문의 핵심을 파헤치고, 이것이 왜 우리 개발자들에게 중요한 의미를 갖는지 알아보겠습니다.
LLM 튜닝의 두 단계: 천재의 탄생과 전문가로의 성장
LLM은 보통 두 단계를 거쳐 학습됩니다.
사전 학습 (Pre-training): 인터넷의 방대한 텍스트 데이터를 읽으며 세상의 지식, 언어의 패턴, 문맥 등을 스스로 학습합니다. 이 과정을 통해 모델은 엄청난 잠재력을 지닌 '뇌'를 갖게 됩니다.얼라인먼트 (Alignment): 사전 학습된 모델이 사용자의 지시를 더 잘 따르고, 유용하며 안전한 답변을 생성하도록 미세 조정(fine-tuning)하는 과정입니다. 보통 수만 개 이상의 지시 데이터셋과 인간 피드백 기반 강화학습(RLHF)이 이 단계에서 사용됩니다.
LIMA 연구팀은 이 두 단계의 중요성에 대해 근본적인 질문을 던졌습니다.
“모델의 거의 모든 지식은 사전 학습 단계에서 이미 학습된 것이 아닐까? 얼라인먼트는 단지 그 지식을 특정 스타일로 꺼내 쓰는 방법을 가르치는 과정이 아닐까?”
이 가설을 표면적 얼라인먼트 가설(Superficial Alignment Hypothesis)이라고 부릅니다.
'답안지 작성법'만 가르친 천재, LIMA의 실험
이 가설을 비유를 통해 쉽게 이해해 봅시다.
- 사전 학습된 LLM (e.g., LLaMa) : 세상의 모든 책을 읽어 박학다식하지만, 시험은 한 번도 본 적 없는
천재 학생 - 얼라인먼트 : 이 천재 학생에게 시험 문제 유형과
모범 답안 스타일을 가르쳐주는 과정
기존의 방식은 이 천재에게 수만 개의 연습 문제를 풀게 하며(대규모 instruction tuning), 틀릴 때마다 채점하며(RLHF) 훈련시키는 것과 같습니다.
하지만 LIMA는 다른 접근법을 택했습니다. 연구팀은 이미 똑똑한 천재에게는 많은 연습 문제가 필요 없다고 생각했습니다. 대신, 아주 잘 만든 1,000개의 모범 답안만 보여주면 충분히 답안 작성법을 배울 것이라고 가정한 것이죠.
LIMA의 특별한 학습 자료 (1,000개)
LIMA는 양 대신 '질'과 '다양성'에 집중했습니다.
- Stack Exchange, wikiHow: 전문가 수준의 질의응답과 상세한 설명이 담긴 고품질 데이터를 선별했습니다.
- 저자들의 자체 제작: AI 비서 스타일에 맞는 일관된 톤을 유지하면서도 다양한 주제를 다루기 위해 250개의 프롬프트와 답변을 직접 작성했습니다.
이렇게 만들어진 단 1,000개의 데이터셋으로 사전 학습된 LLaMa-65B 모델을 파인튜닝하여 LIMA를 탄생시켰습니다. RLHF 과정은 전혀 없었습니다.
결과: 1,000개의 데이터가 만든 놀라운 성능
결과는 놀라웠습니다. LIMA는 52,000개의 데이터로 학습한 Alpaca는 물론, 인간 피드백 강화학습(RLHF)으로 튜닝된 OpenAI의 DaVinci003(GPT-3.5의 초기 모델)보다도 좋은 평가를 받았습니다.
심지어 현존 최고 모델인 GPT-4와의 비교에서도 43%의 경우에 "더 낫거나 비슷하다"는 평가를 받았습니다. 이는 1,000개의 예제만으로도 최상위 모델과 겨룰 수 있는 잠재력을 보여준 것입니다.
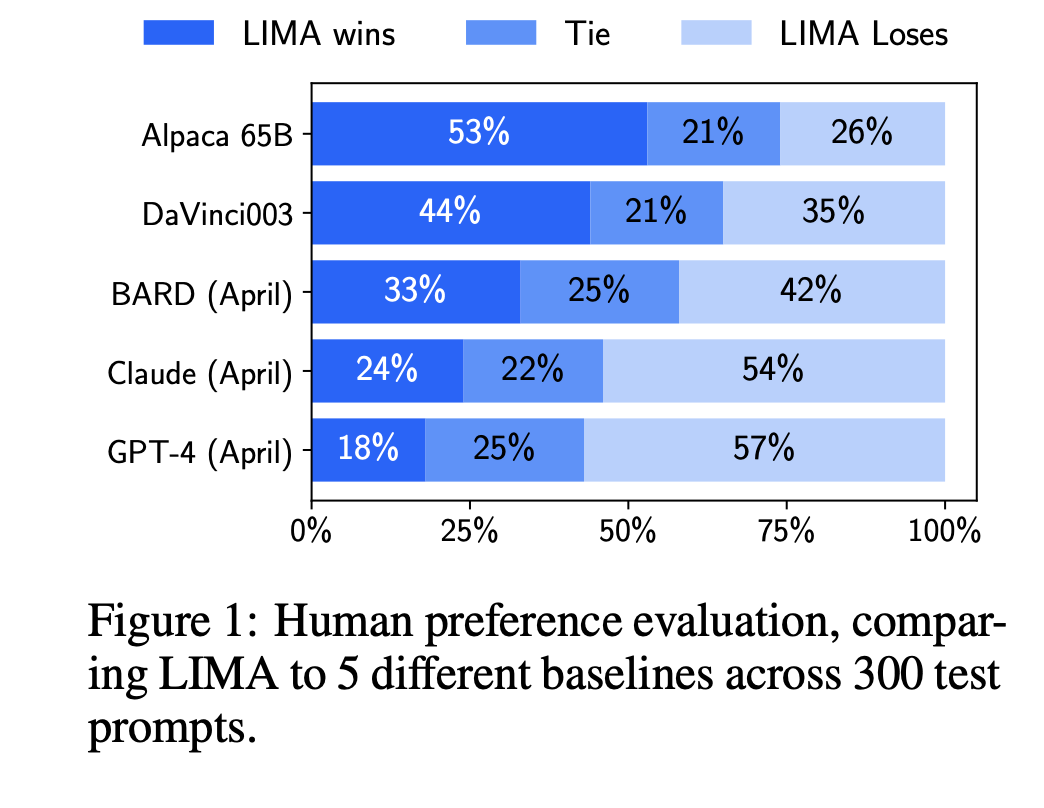
LIMA와 5개 베이스라인 모델에 대한 인간 선호도 평가.
LIMA가 52,000개 예제로 학습한 Alpaca 65B와 RLHF로 훈련된 DaVinci003을 상대로 뚜렷한 우위를 보이며, Bard와 GPT-4를 상대로도 상당한 비율로 선전했음을 보여줍니다.
이 결과는 LIMA의 표면적 얼라인먼트 가설을 강력하게 뒷받침합니다. 모델의 핵심 능력은 이미 사전 학습 단계에서 갖춰졌으며, 소량의 고품질 데이터만으로도 그 능력을 사용자와 상호작용하는 특정 '스타일'로 이끌어낼 수 있다는 것입니다.
무엇이 차이를 만들었나? 양, 질, 다양성
LIMA 연구팀은 왜 "더 적은 것"이 "더 나은" 결과를 낳았는지 알아보기 위해 추가 실험(Ablation Study)을 진행했습니다.
1. 데이터의 질(Quality)과 다양성(Diversity)이 핵심이다
- 다양성: 다양한 주제를 다루는 Stack Exchange 데이터로 학습한 모델이, 'How-to' 형식으로 형식이 비교적 일관된 wikiHow 데이터로 학습한 모델보다 훨씬 높은 성능을 보였습니다. (Figure 5의 Filtered Stack Exchange vs. wikiHow)
- 품질: 품질 필터링을 거친 Stack Exchange 데이터로 학습한 모델이, 필터링하지 않은 데이터로 학습한 모델보다 성능이 월등히 좋았습니다. (Figure 5의 Filtered vs. Unfiltered)
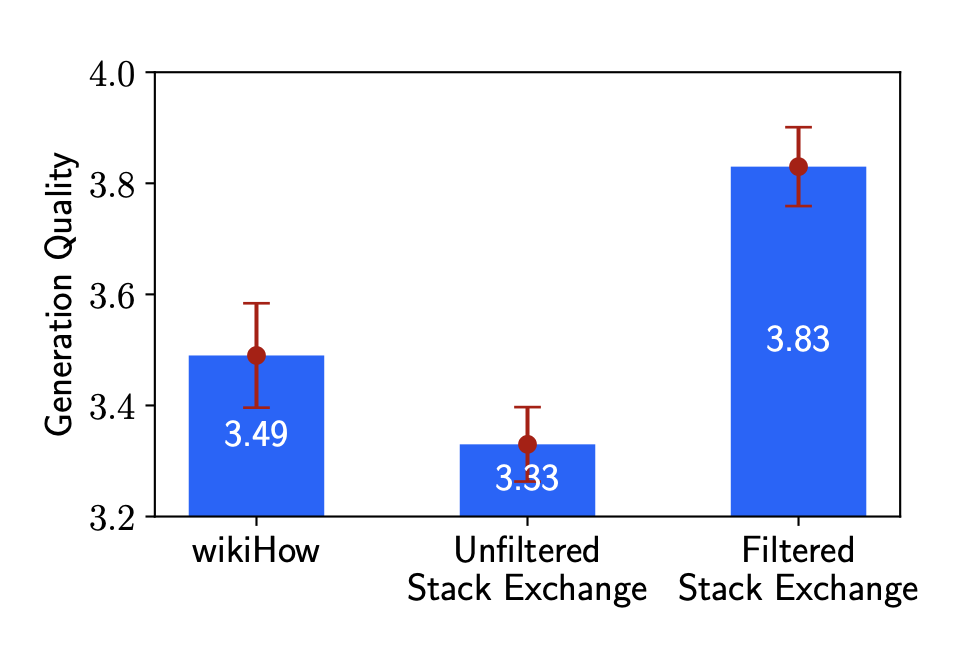
데이터 소스에 따른 성능 비교. 다양한 프롬프트와 고품질 응답을 가진 'Filtered Stack Exchange' 데이터가 가장 높은 성능을 보였고, 품질 필터링을 하지 않은 데이터나 프롬프트가 동질적인 데이터는 성능이 낮았습니다.
2. 양만 늘리는 것은 효과가 없다
놀랍게도, 고품질 데이터의 양을 2,000개에서 32,000개로 16배나 늘렸음에도 불구하고 모델의 성능은 거의 향상되지 않았습니다.
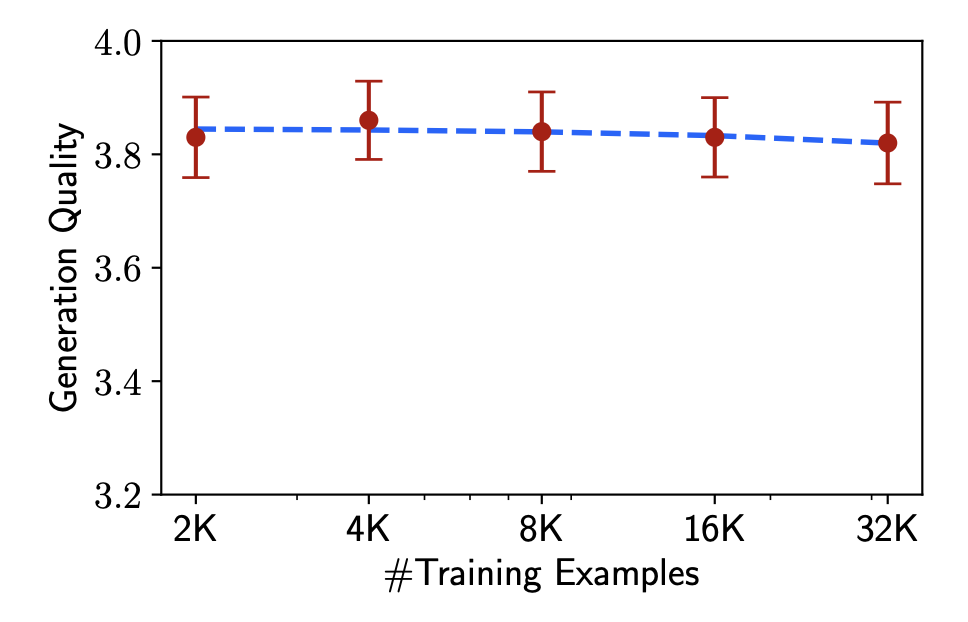
학습 데이터 양을 늘려도 성능이 정체되는 현상. 이는 일정 수준 이상의 품질과 다양성이 확보되면, 데이터의 양만 늘리는 것은 얼라인먼트에 큰 도움이 되지 않음을 시사합니다.
이 실험들은 LLM 얼라인먼트의 핵심이 '무작정 많은 데이터'가 아니라 '잘 정제되고 다양한 소수의 데이터'임을 명확히 보여줍니다.
보너스: 대화 능력도 타고났다?
LIMA의 학습 데이터 1,000개에는 다중 턴(multi-turn) 대화 예제가 전혀 없었습니다. 그럼에도 LIMA는 놀랍게도 여러 턴에 걸쳐 대화를 이어나가는 능력을 보여주었습니다.
더 놀라운 점은, 여기에 단 30개의 대화 예제를 추가하여 다시 학습시키자 대화 실패율이 극적으로 감소하고 '훌륭함(Excellent)' 등급의 응답 비율이 45%에서 76%로 급증했다는 사실입니다.
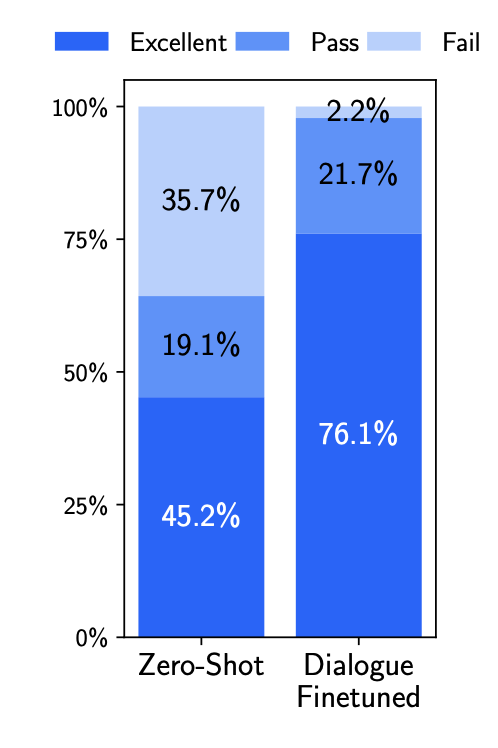
단 30개의 대화 예제를 추가했을 때의 성능 변화. 실패(Fail) 비율이 크게 줄고, 훌륭함(Excellent) 비율이 대폭 상승했습니다.
이는 대화와 같은 복잡한 능력조차 이미 사전 학습 단계에서 내재되어 있으며, 아주 적은 수의 예시만으로도 그 능력을 '활성화'할 수 있다는 것을 의미합니다.
결론: 개발자에게 LIMA가 시사하는 점
LIMA 논문은 LLM 분야에 중요한 메시지를 던집니다.
사전 학습의 힘: 모델의 지식과 능력 대부분은 사전 학습에서 나옵니다. 파인튜닝은 새로운 지식을 주입하는 것이 아니라, 이미 내재된 능력을 특정 목적에 맞게 '꺼내 쓰는 법'을 가르치는 과정입니다.품질과 다양성이 양보다 중요하다: 막대한 양의 데이터를 수집하고 레이블링하는 데 드는 비용과 시간 대신, 작지만 고품질의 다양한 데이터셋을 구축하는 것이 훨씬 효율적일 수 있습니다.- 새로운 가능성: 이 연구는
대규모 자본 없이도 고성능의 특화 모델을 만들 수 있는 길을 열어줍니다.개발자들은 특정 도메인에 맞는 소수의 고품질 데이터만으로도 자신만의 강력한 AI 어시스턴트를 만들 수 있습니다.
이제 우리는 LLM을 튜닝할 때, 무조건 데이터의 양을 늘리기보다 "우리의 천재 학생에게 어떤 모범 답안을 보여줄 것인가?"를 더 깊이 고민해야 할 것입니다. LIMA는 그 고민에 대한 값진 힌트를 우리에게 주었습니다.
