Vanishing Gradient
값이 매우 크거나 작을 때, gradient가 0에 가까워서 backpropagation 하는 데에 어려움이 발생한다. gradient가 사라지는 이 상황을 Vanishing Gradient라고 한다.
- 현상
activation의 미분 계수(접선 기울기)가 0에 가까우면
=> dJ/dW의 감소
=> gradient descent가 잘 일어나지 않음 (학습이 잘 일어나지 않음) - 용어
saturation : weight의 update가 잘 일어나지 않는 현상
vanishing gradient : gradient가 0에 가까워지는 (소실되는 현상)
Activation function
Activation function을 취해줌으로써 우리가 원하는 비선형성을 얻을 수 있게 된다.
매 layer가 끝날 때마다 nonlinear activation을 해준다.
-
Sigmoid
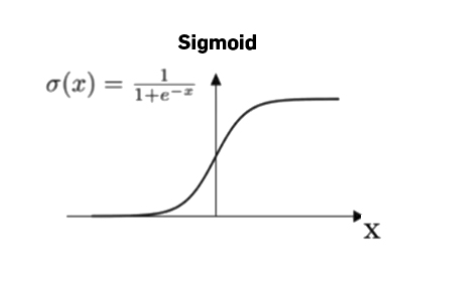
① 0<g(z)<1 => 장점1: binary classification의 output layer라는 특수한 상황에 적합
② g'(z)가 0에 가까운 구간이 많다 => 단점2: gradient descent의 속도 저하 -
tanh (hyperbolic tangent)
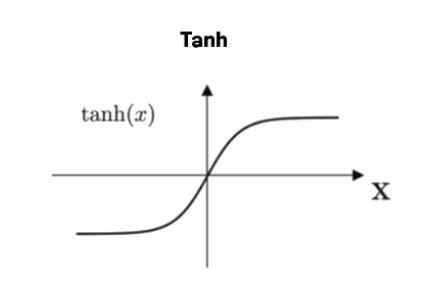
① -1<g(z)<1
② g'(z)가 0에 가까운 구간이 많다 (0<g'(z)<1)
=> 장점1: sigmoid보다는 vanishing gradient가 덜하다.
=> 단점1: gradient descent 속도 저하
-
ReLU (Rectified Linear Unit)
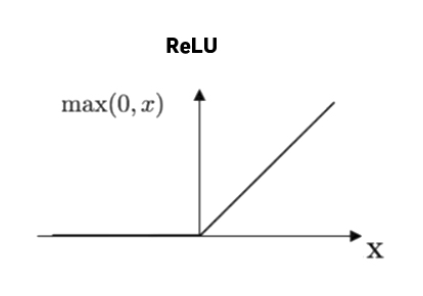
① g'(z)=1인 구간이 절반이다
=> 장점1: sigmoid, tanh의 vanishing gradient 문제 해결
=> 단점1: 그래도 절반이 gradient가 0 (dying ReLU 현상)
-
Leaky ReLU
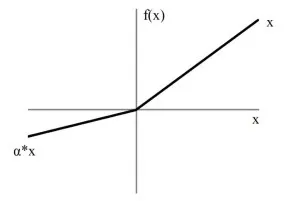
① gradient가 0인 구간이 없다
=> 장점1: dying ReLU 현상을 해결
- activation이 non-linear해야 하는 이유
Neural Network는 거대한 합성함수이다.
Non-linear activation을 하지 않는다면, layer가 하나만 있을 때로부터 얻는 결과와 다를 바가 없다.
Random initialization
W들을 initialization 해줘야 한다.
zero initialization의 문제점
- row symmetric 현상이 발생한다. 그러면 node를 여러 개 설정했음에도 node가 1개인 효과를 갖게 된다.
- vanishing gradient 현상이 발생한다.
대책 : Random Initialization
- Xavier Initialization
input node와 output node의 개수 고려 - Glorot Initialization
input node와 output node의 개수 고려 - He Initialization
input node의 개수만 고려
