Holdout Validation
Hyperparameter : 모델링할 때 사용자가 직접 세팅해주는 값
ex) learning rate, of layer, # of unit of each layer, activation, iteration
Data split : training set, validation set, test set 세 종류로 split한다.
-
training set
모델을 학습시키는 data
최적의 parameter를 찾는 과정 = gradient descent = parameter update -
validation set
내가 선택한 모델(hyperparameter의 조합)이 최적의 모델인지 학습하지 않은 data(validation set)으로 검증
최적의 hyperparameter인지 검증 -> 결과에 따라 tuning함 -
test set
수차례의 검증을 마치고 최종 test에 사용하는 data
한 번의 Epoch는 인공 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
Underfitting vs Overfitting
Fit 한다는 것은 Train 한다는 것이랑 같음
Bias-Variance tradeoff
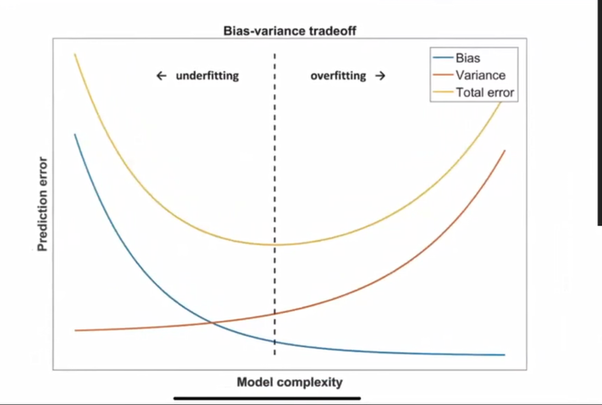
-> x축의 오른쪽으로 갈수록 모델은 복잡해지고 bias는 낮아지지만 variation은 높아진다. (Overfitting)
-> x축의 왼쪽으로 갈수록 모델은 단순해지고 variation은 낮아지지만 bias는 높아진다. (Underfitting)
Error = Bias + Variance
Bias: 참 값들과 추정 값들의 차이
Variance: 추정값들의 흩어진 정도
Variance도 낮고 Bias도 낮은 trade-off 관계를 잘 만족시키는 모델을 선택해야한다.
-
Underfitting
Bias가 크다.
Training error, validation error 높다.
모델이 너무 간단하여 학습 오류가 줄어들지 않는다. -
Overfitting
Variance가 크다.
Training error 낮고, validation error 높다.
새로운 데이터에 대해 예측을 잘 못한다.
