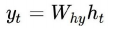Metrics
1. Regression
1) mean absolute error
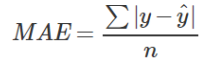
2) root mean square error
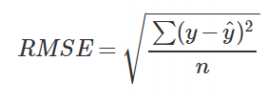
2. Classification
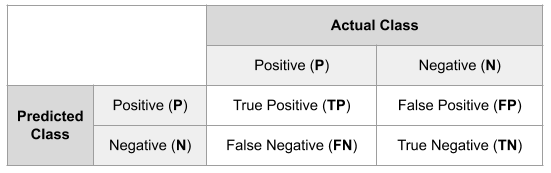
1) Precision = TP/(TP+FP)
positive 판정이 맞을 확률
2) Recall = TP/(TP+FN)
positive 사건이 잘 맞았는지
3) Accuracy = (TP+TN)/(TP+FN+FP+TN)
전체 중 모델이 바르게 분류한 비율
4) F1 score = 2/(1/Precision + 1/Recall)
Precision과 Recall의 밸런스를 고려하여 정확도 측정
데이터가 불균형할 때 Accuracy가 아닌 F1 score 사용
파이썬 라이브러리 Pandas 사용법
import pandas as pd
Pandas 자료구조
1) Series
'index'와 'value'로 이루어진 1차원의 structured data 형식
pd.Series(data=['a','b','c'])

pd.Series(data = ['a', 'b', 'c'], index = [1,2,3])

pd.Series(data = {'math': 90, 'english': 85, 'korean': 97})

2) DataFrame
여러 개의 Series로 이루어진 2차원의 structured data 형식
- DataFrame 각각의 열을 하나의 Series라고 보면 됨
- 하나의 'index'에 'column'별 'value'들이 존재
pd.DataFrame(data = [[20, 'Germany', 'computer science'], [24, 'China', 'math']], index = ['Harry', 'Linda'],columns = ['age', 'Orgin', 'major'])

dic2 = {'age': [20,24], 'Orgin': ['Germany', 'China'], 'major':['computer science', 'math']}
pd.DataFrame(data = dic2, index = ['Harry', 'Linda'] )

파일 불러오기 및 저장하기
1) csv 파일 불러오기 (pd.read_csv)
- 절대 경로
pd.read_csv('C:/Users/User/16th_futurelab/week09/titanic.csv') - 상대 경로
pd.read_csv('./titanic.csv')# './'은 현재 해당 파일이 있는 폴더를 의미 #'../'은 현재 해당 파일의 부모 폴더를 의미
2) csv 파일 저장하기 (pd.DataFrame.to_csv)
df.to_csv('my_df_index_false.csv', index=False)
Indexing & Slicing
1) 행
df4 = pd.DataFrame(data = dic4, index = ['Harry', 'Linda', 'Kim'] )- Indexing
df4.loc['Harry']
df4.loc[['Harry']]
df4.loc[['Harry', 'Linda']] - Slicing
df4.loc['Harry':'Kim']
df4.loc['Linda':'Kim', 'age':'orgin']
2) 열
URL = './heart.csv'
df = pd.read_csv(URL)
- Indexing
df['chol']
df.chol
df[['chol']]
df[['chol', 'age']] - Slicing
df.loc[:, 'cp':'ca']
행과 열 제거 및 결합
1) 행과 열 제거 (drop)
- labels: 제거하고 싶은 대상
df.drop(labels = 1)#axis=0이 default #index=1인 행 제거됨
df.drop(labels = 'Name', axis = 1)#변수명 Name인 열 제거됨 - axis: 0(행을 제거), 1(열을 제거)
- index: 선택한 행을 제거
df.drop(index=1) - columns: 선택한 열을 제거
df.drop(columns='Name')
2) 행과 열 결합
-
열끼리의 결합 (join)
df_col1 = df[['PassengerId', 'Survived']]
df_col2 = df[['Fare', 'Ticket']]
df_col1.join(df_col2) -
행끼리의 결합 (append)
df_r1 = df.iloc[:99]
df_r2 = df.iloc[100:199]
df_r1.append(df_r2)
누락, 중복 data 처리
1) 누락 data 확인
df.info()#DataFrame에 대한 요약 정보 담겨 있음 #한 번에 null의 개수 확인df.isna()#is.na(): 누락 data에서 True를 반환
2) 누락 data 채워 넣기
df.fillna(0)#0으로 채워 넣기each = {'Age':np.mean(df.Age), 'Embarked':0 }
df.fillna(value = each)#다르게 채워 넣기df.drop('Cabin', axis=1)#누락된 column 자체 제거
3) 중복 data 확인
df.duplicated()
4) 중복 data 제거
df.drop_duplicates()
data의 분포
df.describe()#각 columns에 대한 통계정보 확인df['Survived'].unique()#각 column이 어떤 값들을 갖는지 확인df['Survived'].value_counts()#각 column이 갖는 값들의 개수 확인df['Survived'].plot(kind='hist')#그림으로 분포 확인
RNN (Recurrent Neural Network)
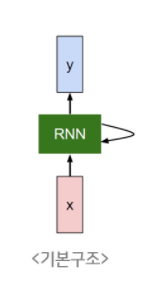
-
Cell: RNN의 기본 구성 단위
-> RNN은 여러 개의 cell로 구성되어 있다.
unit: Cell 내부의 hidden unit 개수 -
RNN의 종류: Fully-Connected Layer, Image Captioning, Sentiment Classification, Machine Translation, Video Classification
-
은닉층 계산
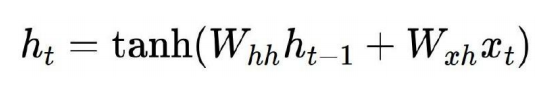
h_t : 현재 시점 t에서의 hidden state
x_t : input
W_x : 입력층의 입력값에 대한 가중치
W_h : 이전 시점 t-1의 hidden state값인 h_t-1에 대한 가중치
tanh : activation function -
출력층 계산