
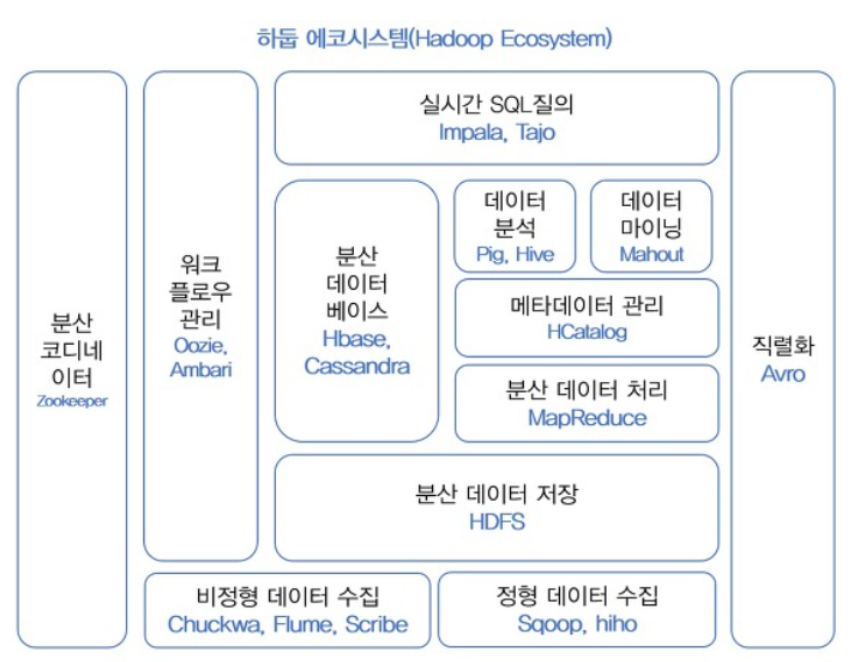
하둡에코시스템
하둡 에코시스템 우리는 위에서 여러 프레임워크를 알아보았다. 하둡에서 데이터를 분석 유지 저장 관리 할 때 필요한 모든 것들을 에코시스템이라 한다. 즉, 하둡은 효율적인 데이터 처리와 분석을 위해 맵리듀스, 분산형 파일시스템(HDFS) 말고도 많은 구성요소로 포함된다.
맵리듀스
이번에는 맵리듀스에 대해서 알아보자 하둡은 분산처리가 가능한 시스템과 분산되어 저장된 데이터를 병렬로 처리가능하게 하는 맵리듀스 프레임워크의 결합한 단어라 할 수 있다. 즉, 하둡 분산 파일 시스템(HDFS)은 대용량 파일을 지리적으로 분산되어 있는 수많은 서버에 저장
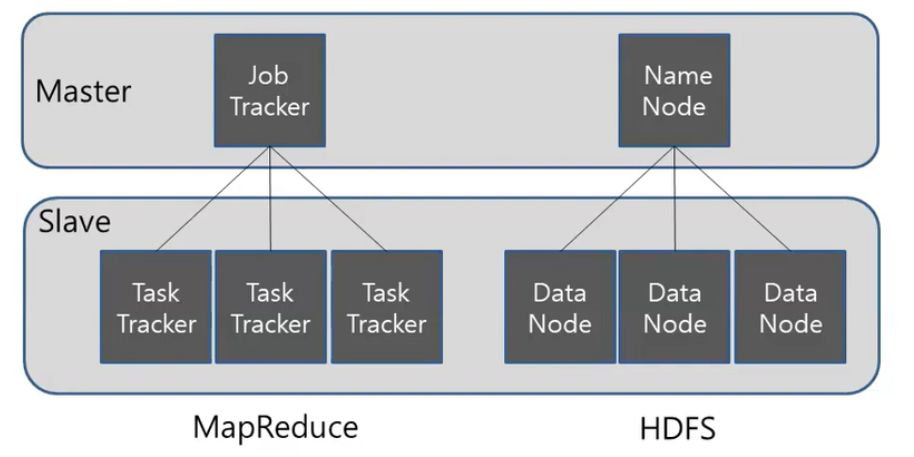
HDFS
HDFS 구조(Architecture) 기본적으로 HDFS는 마스터 슬레이브 구조야마스터 슬레이브 구조마스터/슬레이브(Master/slave)는 장치나 프로세스(마스터)가 하나 이상의 다른 장치나 프로세스(슬레이브)를 통제하고 통신 허브 역할을 하는 비대칭 통신 및 제
하둡이란
아파치 하둡은 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크야.Hadoop (High-Availability Distributed Object-Oriented Platform) 자바 소프
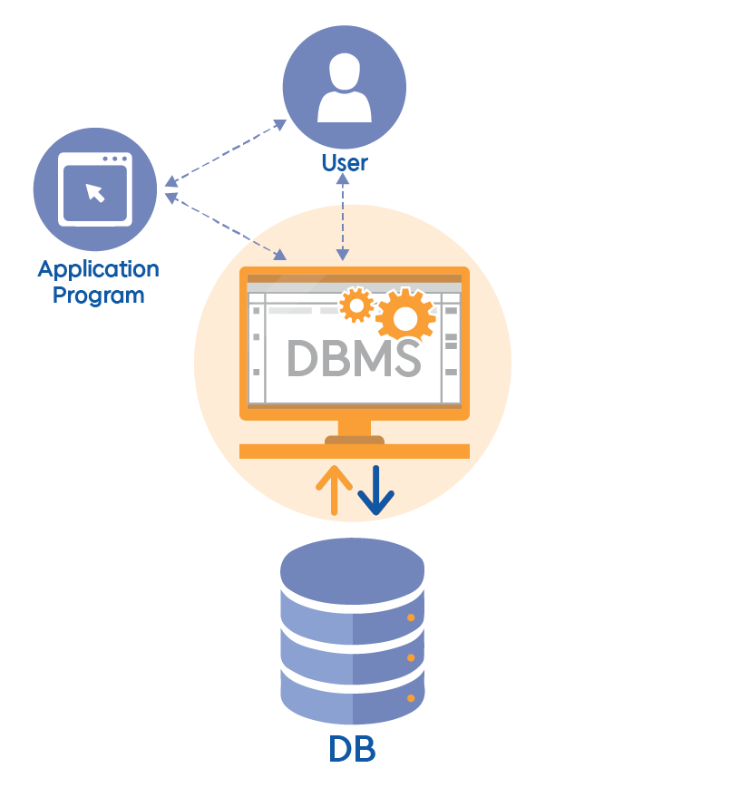
데이터베이스 관리 시스템(DBMS)
이전에 파일시스템의 단점을 보완하여 데이터베이스 시스템이 등장했다고 했어.DBMS는 이 데이터베이스 시스템을 관리해주는 관리 시스템이야. 즉 데이터베이스 관리 시스템(DataBase Management System, DBMS)은 데이터베이스를 조작하는 별도의 소프트웨어
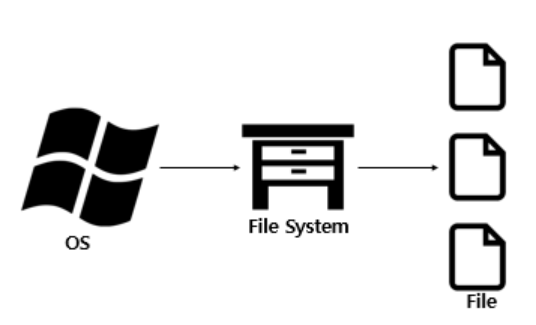
파일시스템과 데이터베이스
데이터를 저장하는 방법에는 여러가지 존재하지만 과거에는 파일시스템으로 저장을 했었어.파일 시스템은 파일(데이터의 모임)을 저장 장치에 저장하고 사용하기 위한 일종의 규칙이나 체계를 뜻해.파일의 이름을 붙이고, 쉽게 파일에 접근할 수 있도록 배치를 신경 쓰는 등 파일과
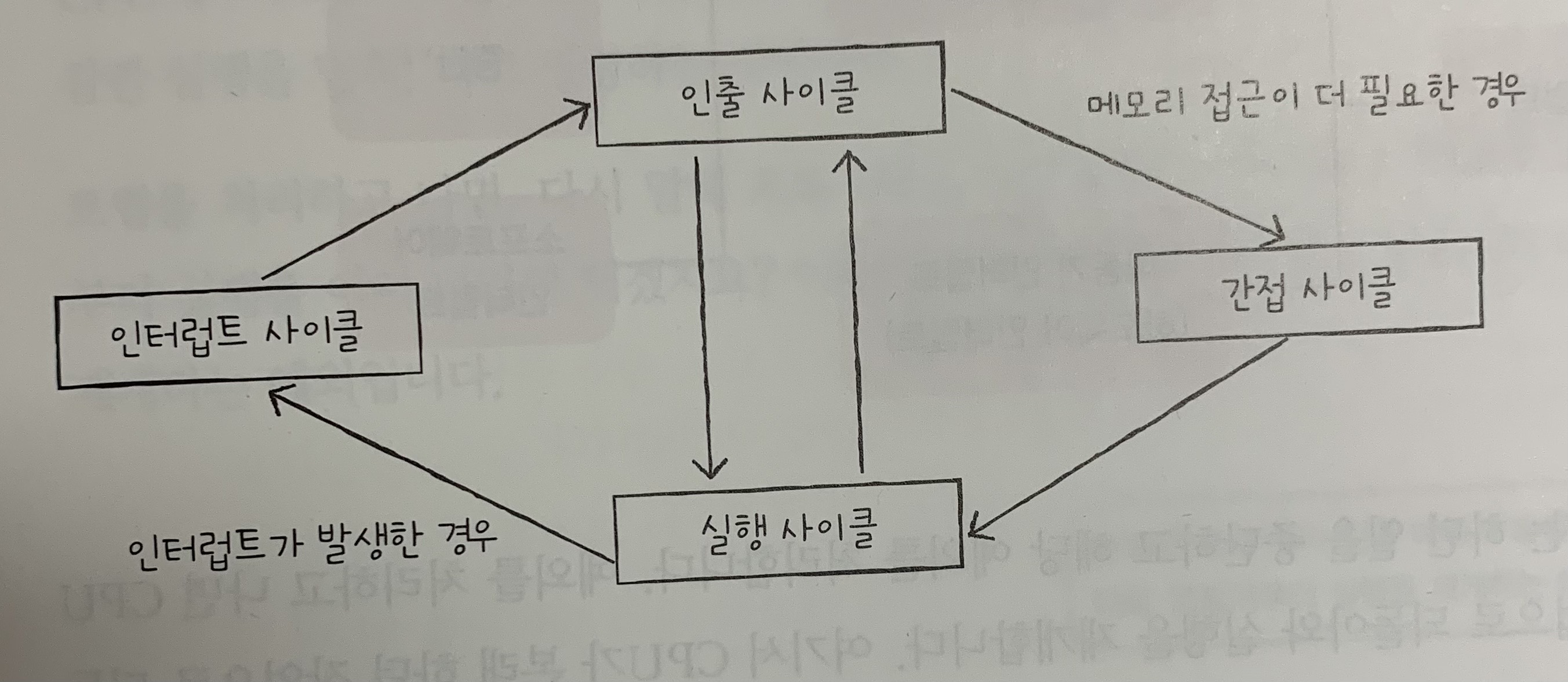
[컴퓨터 구조] 명령어 사이클과 인터럽트
CPU가 하나의 명령어를 처리하는 과정에는 어떤 정해진 흐름이 있고, CPU는 그 흐름을 반복하며 명령어들을 처리해나가. 이렇게 하나의 명령어를 처리하는 정형화된 흐름을 명령어 사이클이라고 해.CPU는 정해진 흐름에 따라 명령어를 처리해 나가지만, 간혹 이 흐름이 끊어
[컴퓨터 구조] 레지스터
CPU안에는 ALU, 제어장치 말고도 레지스터라는 작은 임시장치가 존재해.프로그램 속 명령어와 데이터는 실행 전후로 반드시 레지스터에 저장되지.그래서 레지스터 속 값을 유심히 관찰하면 프로그램을 실행할 때 CPU내에서 무슨일이 벌어지고 있는지, 어떤 명령어가 어떻게 수
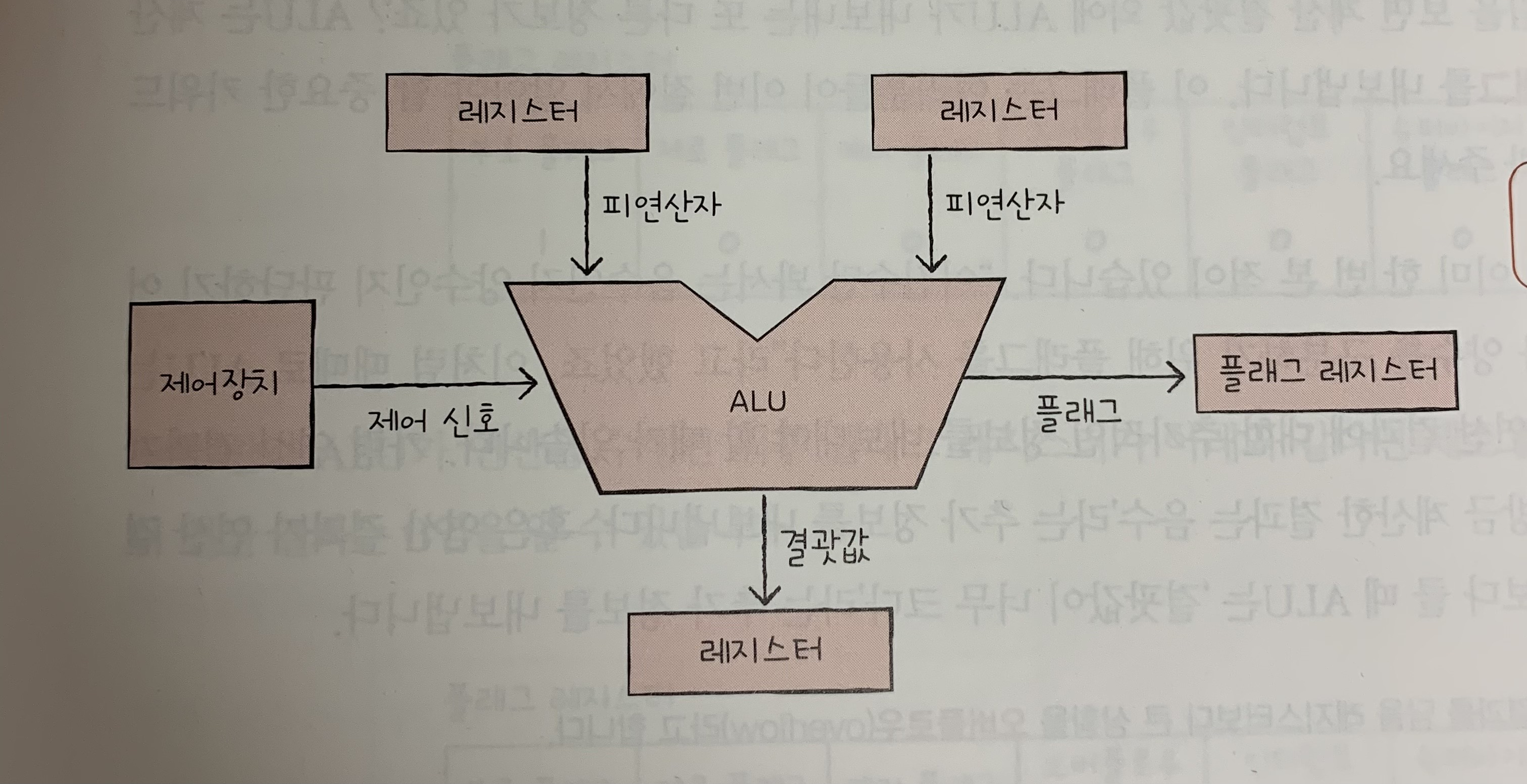
[컴퓨터 구조] ALU와 제어장치
ALU는 계산기 역할을 해. 컴퓨터 내부에 있는 계산기라고 볼 수 있지.ALU는 계산하는 부품이야. 즉 피연산자와 수행할 연산이 필요해.그래서 ALU는 레지스터를 통해 피연산자를 받아들이고, 제어장치로부터 수행할 연산을 알려주는 제어 신호를 받아들여연산 수행의 결과는
[자료구조] 그래프 탐색
기본적인 그래프 탐색 방법인 깊이 우선 탐색과 너비 우선 탐색에 대해 알아보겠다.스택을 사용하지 않고 순환 개념을 사용하여 깊이우선탐색을 진행방문 정점을 제외한 인접정점을 방문할 때, 바로 v를 기준으로 순환함수를 실행하면서 깊은 부분을 우선적으로 탐색하는 깊이우선탐색
[자료구조] 이진탐색트리 삭제
이진 탐색트리의 삭제연산은 3가지 Case를 고려해야한다.단말 노드 삭제자식이 하나인 노드 삭제두개의 자식을 모두 갖는 노드의 삭제각각의 Case를 개별 함수로 정의하고 하나의 delete 함수가 필요하다.삭제할 노드가 단말 노드인 경우이다. 삭제할 노드가 자기 부모의