Gradient Vanishing / Exploding
- Gradient Vanishing : Sigmoid Activation Function과 같이, Gradient값이 Back propagation이 되면서 소멸하는 문제를 말한다.
- Gradient Exploding : Gradient Vanishing과 반대로 Gradient 값이 너무 커져서 발산하는 것을 말한다.(Nand와 같은것)
Solution
- Change Activation Function: Sigmoid Function을 ReLU function으로 바꾼것처럼 Activation 함수를 변경해서 문제를 해결하는 것을 말한다.
- Weight Initialization: He / Xavier Initializaion처럼 weight값을 섬세하게 초기화하여 문제의 발생을 막는 것을 말한다.
- Small Learning Rate : learning rate를 줄여서 exploding을 예방해준다.
- Batch Normalization : 아래에서 다룰 예정이다. 직접적인 해결방법으로, 학습 안정확, 속도 향상에도 영향을 준다.
원인 분석
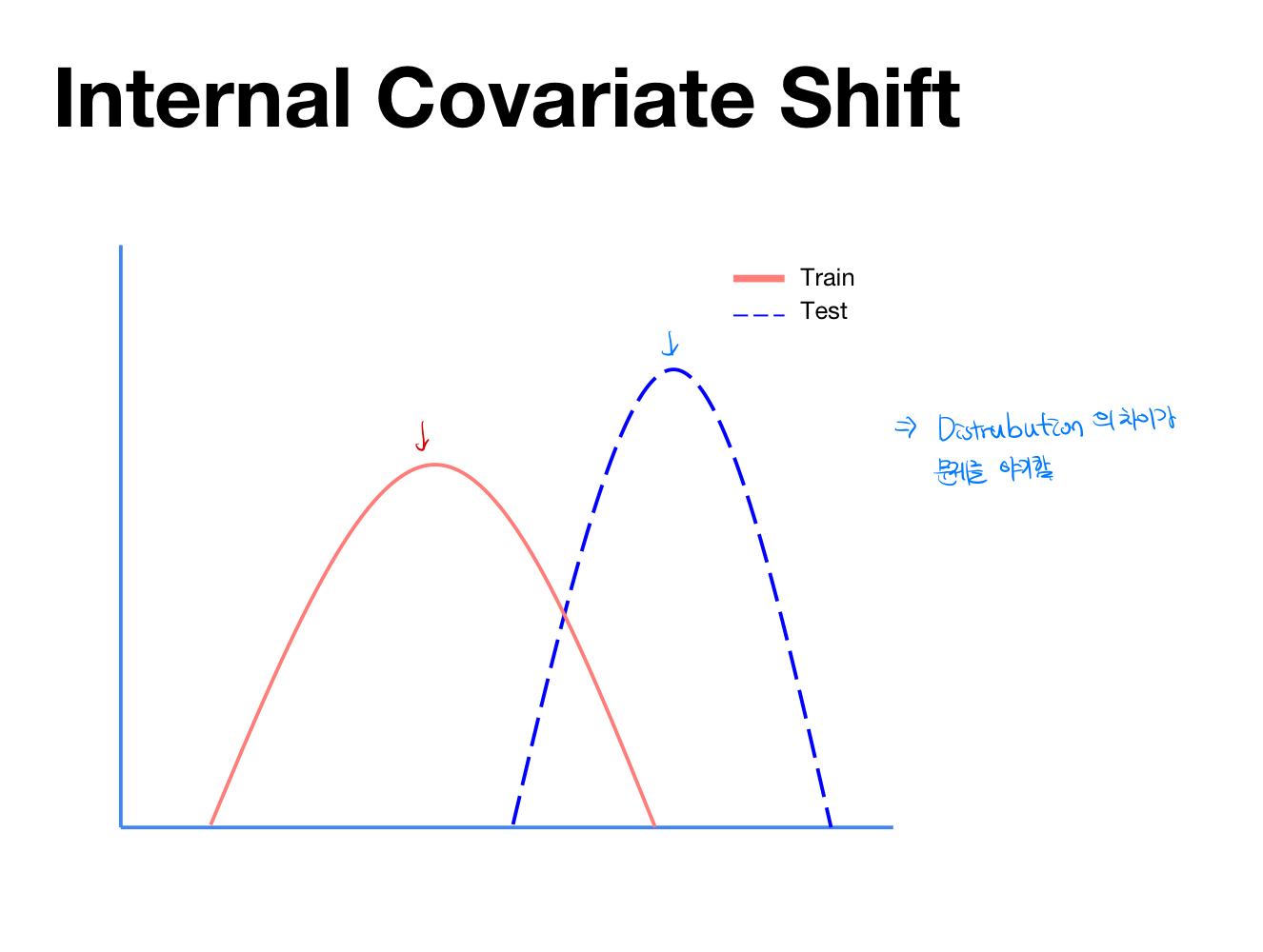
Internal Covariate Shift
- 신경망 모델에서 학습을 하면서 각 layer에서 input과 output값의 distribution정도가 다른 현상을 Covariate Shift라고 부른다. Internal Covarite Shift는 이로 인해 각 layer의 최종 값의 분포값이 처음에 의도한 input값과 매우 다른 결과를 만들어 낼때를 의미한다.
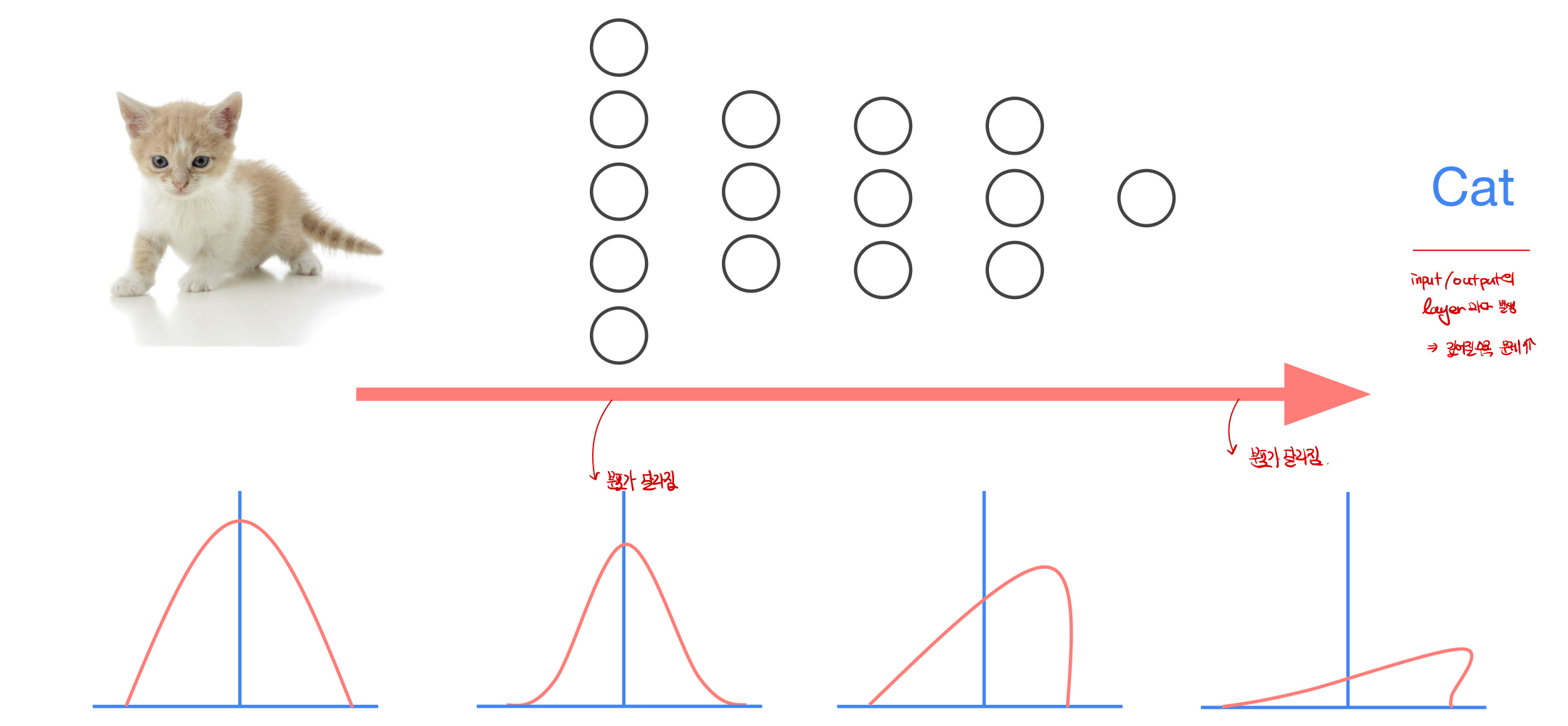
Batch Normalizaion
- 각 layer마다 normalization을 해주는 것을 의미하는데, 각 layer의 batch들을 normalize를 하여 문제를 해결해준다. 아래는 모두를 위한 딥러닝에서 제공하는 필기의 일부이다.

- 코드 작성시 유의 사항 :
bn=torch.nn.BatchNorm1d(number)와 같은 방식으로 layer들을 선언할 때 작성해준다. Train 모델일 때는model.train()을 test를 할때에는model.eval()을 이용해준다. 그 이유는 배치마다 mean, variance값이 다른데, eval()을 이용해주면, 훈련데이터의 배치마다 mean과 variance를 normalize를 이용하여 변하지 않는 값 learning mean과 variance 값을 이용하기 때문에 꼭 선언해줘야한다.
# Lab 10 MNIST and softmax
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pylab as plt
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
torch.manual_seed(1)
if device == 'cuda':
torch.cuda.manual_seed_all(1)
# parameters
learning_rate = 0.01
training_epochs = 10
batch_size = 32
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
# dataset loader
train_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset=mnist_test,
batch_size=batch_size,
shuffle=False,
drop_last=True)
# nn layers
linear1 = torch.nn.Linear(784, 32, bias=True)
linear2 = torch.nn.Linear(32, 32, bias=True)
linear3 = torch.nn.Linear(32, 10, bias=True)
relu = torch.nn.ReLU()
bn1 = torch.nn.BatchNorm1d(32)
bn2 = torch.nn.BatchNorm1d(32)
nn_linear1 = torch.nn.Linear(784, 32, bias=True)
nn_linear2 = torch.nn.Linear(32, 32, bias=True)
nn_linear3 = torch.nn.Linear(32, 10, bias=True)
# model
bn_model = torch.nn.Sequential(linear1, bn1, relu,
linear2, bn2, relu,
linear3).to(device)
nn_model = torch.nn.Sequential(nn_linear1, relu,
nn_linear2, relu,
nn_linear3).to(device)
# define cost/loss & optimizer
criterion = torch.nn.CrossEntropyLoss().to(device) # Softmax is internally computed.
bn_optimizer = torch.optim.Adam(bn_model.parameters(), lr=learning_rate)
nn_optimizer = torch.optim.Adam(nn_model.parameters(), lr=learning_rate)
# Save Losses and Accuracies every epoch
# We are going to plot them later
train_losses = []
train_accs = []
valid_losses = []
valid_accs = []
train_total_batch = len(train_loader)
test_total_batch = len(test_loader)
for epoch in range(training_epochs):
bn_model.train() # set the model to train mode
for X, Y in train_loader:
# reshape input image into [batch_size by 784]
# label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
bn_optimizer.zero_grad()
bn_prediction = bn_model(X)
bn_loss = criterion(bn_prediction, Y)
bn_loss.backward()
bn_optimizer.step()
nn_optimizer.zero_grad()
nn_prediction = nn_model(X)
nn_loss = criterion(nn_prediction, Y)
nn_loss.backward()
nn_optimizer.step()
with torch.no_grad():
bn_model.eval() # set the model to evaluation mode
# Test the model using train sets
bn_loss, nn_loss, bn_acc, nn_acc = 0, 0, 0, 0
for i, (X, Y) in enumerate(train_loader):
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
bn_prediction = bn_model(X)
bn_correct_prediction = torch.argmax(bn_prediction, 1) == Y
bn_loss += criterion(bn_prediction, Y)
bn_acc += bn_correct_prediction.float().mean()
nn_prediction = nn_model(X)
nn_correct_prediction = torch.argmax(nn_prediction, 1) == Y
nn_loss += criterion(nn_prediction, Y)
nn_acc += nn_correct_prediction.float().mean()
bn_loss, nn_loss, bn_acc, nn_acc = bn_loss / train_total_batch, nn_loss / train_total_batch, bn_acc / train_total_batch, nn_acc / train_total_batch
# Save train losses/acc
train_losses.append([bn_loss, nn_loss])
train_accs.append([bn_acc, nn_acc])
print(
'[Epoch %d-TRAIN] Batchnorm Loss(Acc): bn_loss:%.5f(bn_acc:%.2f) vs No Batchnorm Loss(Acc): nn_loss:%.5f(nn_acc:%.2f)' % (
(epoch + 1), bn_loss.item(), bn_acc.item(), nn_loss.item(), nn_acc.item()))
# Test the model using test sets
bn_loss, nn_loss, bn_acc, nn_acc = 0, 0, 0, 0
for i, (X, Y) in enumerate(test_loader):
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
bn_prediction = bn_model(X)
bn_correct_prediction = torch.argmax(bn_prediction, 1) == Y
bn_loss += criterion(bn_prediction, Y)
bn_acc += bn_correct_prediction.float().mean()
nn_prediction = nn_model(X)
nn_correct_prediction = torch.argmax(nn_prediction, 1) == Y
nn_loss += criterion(nn_prediction, Y)
nn_acc += nn_correct_prediction.float().mean()
bn_loss, nn_loss, bn_acc, nn_acc = bn_loss / test_total_batch, nn_loss / test_total_batch, bn_acc / test_total_batch, nn_acc / test_total_batch
# Save valid losses/acc
valid_losses.append([bn_loss, nn_loss])
valid_accs.append([bn_acc, nn_acc])
print(
'[Epoch %d-VALID] Batchnorm Loss(Acc): bn_loss:%.5f(bn_acc:%.2f) vs No Batchnorm Loss(Acc): nn_loss:%.5f(nn_acc:%.2f)' % (
(epoch + 1), bn_loss.item(), bn_acc.item(), nn_loss.item(), nn_acc.item()))
print()
print('Learning finished')
def plot_compare(loss_list: list, ylim=None, title=None) -> None:
bn = [i[0] for i in loss_list]
nn = [i[1] for i in loss_list]
plt.figure(figsize=(15, 10))
plt.plot(bn, label='With BN')
plt.plot(nn, label='Without BN')
if ylim:
plt.ylim(ylim)
if title:
plt.title(title)
plt.legend()
plt.grid('on')
plt.show()
#그래프 비교
plot_compare(train_losses, title='Training Loss at Epoch')
plot_compare(train_accs, [0, 1.0], title='Training Acc at Epoch')
plot_compare(valid_losses, title='Validation Loss at Epoch')
plot_compare(valid_accs, [0, 1.0], title='Validation Acc at Epoch')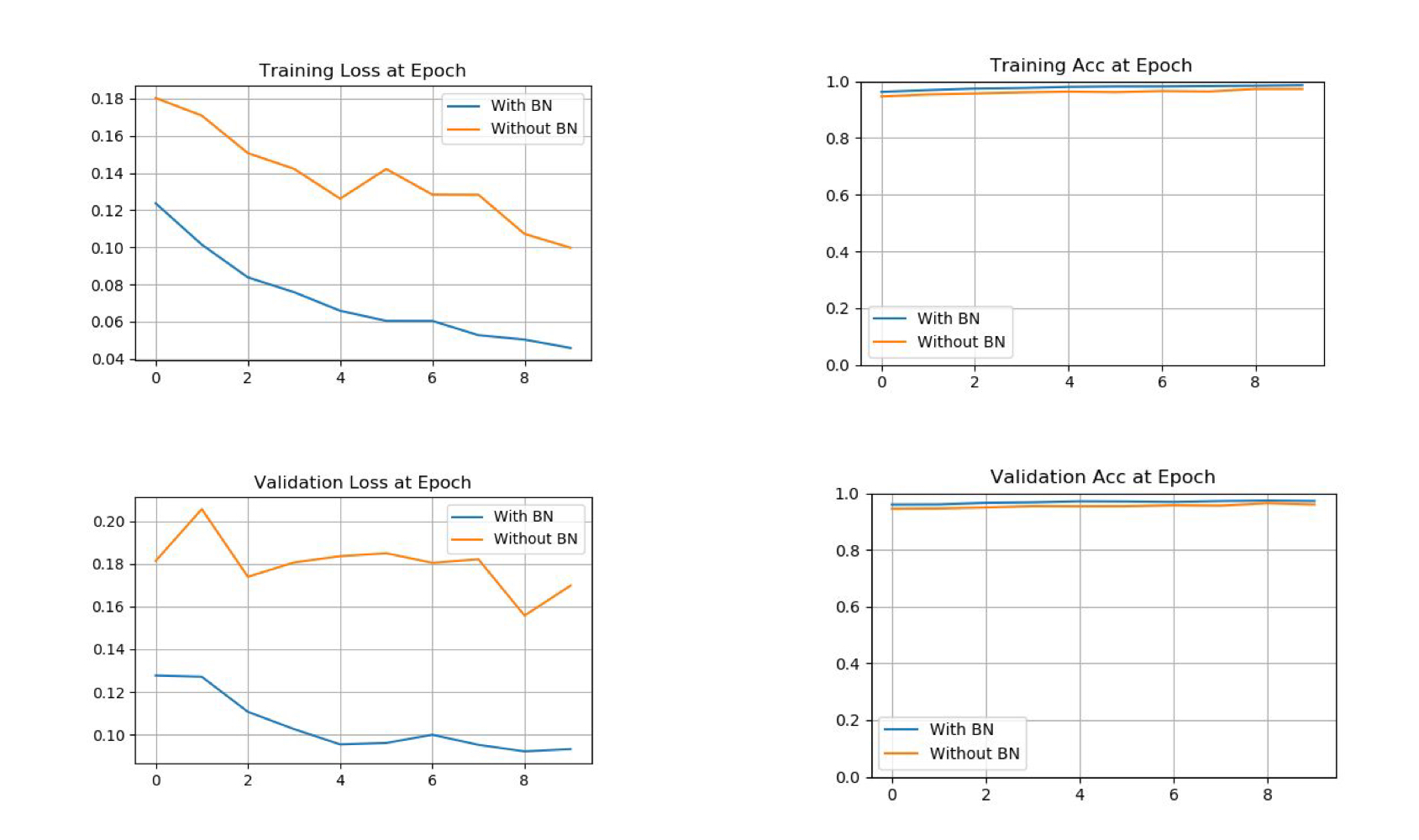

사회적 가치를 실현하는 프로그래머