이글은 Mathematics for Machine Learning 의 Chapter 6의 일부분을 정리한 글입니다. 의역이 포함되어 있으며, Google ML BootCamp 스터디에서 정리한 글을 보고 싶으시다면 이 링크를 따라가시면 됩니다.
회귀(Regression)의 정의
이번 챕터에서는 이전 Chapter 2, 5, 6, 7 개념을 이용하여 선형회귀(Linear Regression) 또는 곡선 피팅(curve fitting)에 대해서 다룰 것이다. 회귀(Regression)는 를 만족하는 입력 를 에 맵핑하는 함수 를 찾는 것을 목표로 한다. 이 챕터에서는 이 훈련 세트(training Set)로 주어지고, 이에 상응하는 잡음(noise)가 섞인 관측 이 주어졌다고 가정한다. 이 챕터 전체에서 평균이 0인 가우시안 노이즈(Gaussian Noise)를 가정한다. 회귀 모델의 목적은 단순히 훈련 데이터에 대해 모델링할 뿐만이 아니라 훈련 데이터에 주어지지 않은 값에 대해서도 잘 예측할 수 있도록 설계 하는 것이다.(Chapter 8 참고)
참고1. εε은 잠재적으로 모델 프로세스에 포함되지 않을 측정/관측 오류 값을 의미한다. ε에 대해서는 Chapter 9에서 자세히 담고 있지는 않다.
예시1
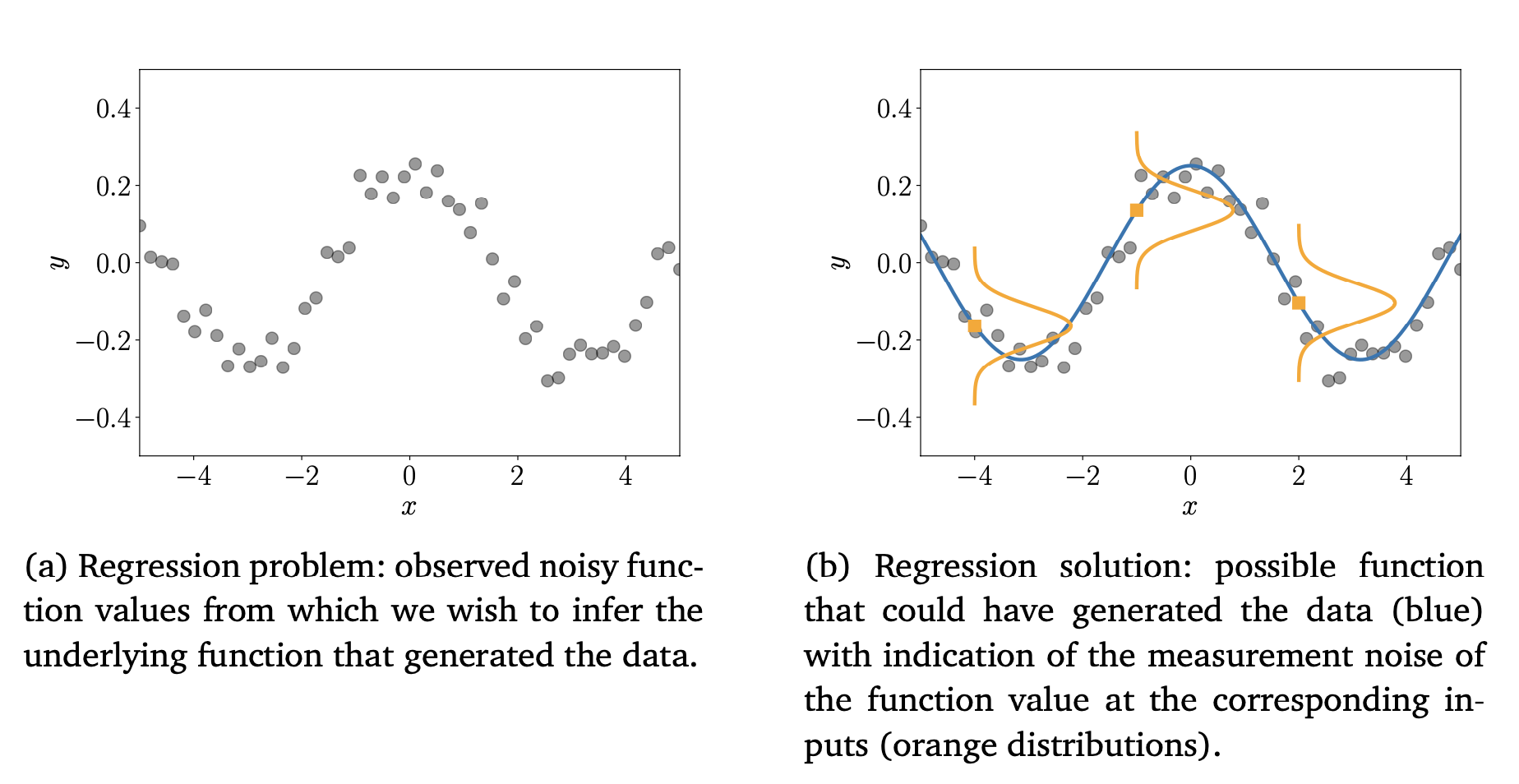
그림1에서 회귀에 대한 예시를 보여준다.
그림 1(a) : 주어진 입력값 에 대해서 우리는 노이즈가 섞인 함수 을 관찰할 수 있다. 여기서 회귀는 새로운 입력값에 대해서도 잘 예측할 수 있으며, 입력된 데이터에도 잘 작동할 수 있는 일반화된 함수 f를 추론하는 것이다.
그림 1(b) : 그림9.1(a)의 해결책이 제시되어 있으며, 이 그림에서 데이터안에 있는 노이즈를 나타내는 함수 f(x)를 중심으로 한 세 가지 확률 분포를 보여준다.
머신러닝과 선형회귀
회귀는 머신러닝의 필수적인 요소이며, 회귀는 시계열 분석(예: 시스템 식별), 제어 및 로봇 공학(예: 강화 학습, 정방향/역방향 모델 학습), 최적화(예: 선형 검색, 전역 최적화), 그리고 딥 러닝 애플리케이션(예: 컴퓨터 게임, 음성-텍스트 번역, 이미지 인식, 자동 비디오 주석)을 포함한 다양한 연구 영역과 응용 분야에서 사용된다. 또한, 회귀는 분류 알고리즘의 핵심 요소이기도 하다. 회귀 함수를 활용하기 위해서는 다음 조건을 만족하거나 문제를 해결해야 한다.
선형회귀를 사용하기 위한 선행 조건
1. 모델(유형) 선정과 회귀 함수 매개변수화 : 데이터 세트가 주어졌을 때, 어떤 함수가 데이터를 모델링하는데 적합한 후보이며, 어떤 특정 매개변수화를 적용해야 되는지 적합한 방식을 선택해야한다.(예: 다항식, 일차식 등 다양한 모델 후보를 선정하고 선택) Section 8.6에서 언급한 것처럼 모델 선택(Model Selection)을 통해 다양한 모델을 비교하여 데이터를 합리적으로 잘 설명하는 가장 간단한 모델로 선택해야한다.
2. 좋은 매개 변수를 선택하기 : 좋은 회귀 모델을 선택했다면, 어떤 것이 모델의 좋은 매개변수인지 선택해야한다. '좋은 적합'을 만들어 낼 수 있는 다양한 손실함수를 살펴보고 손실을 최소화 할 수 있는 최적화 알고리즘을 살펴보면서 최적의 매개 변수를 선택해야한다.
3. 과적합(Overfitting)을 피하고, 좋은 모델 선정하기 : 과적합(Overfitting)이란 훈련 데이터에 너무 잘 적합되어 보여지지 않은, 즉 주어지지 않은 데이터에 대해 잘 일반화 되지 않는 상황을 이야기한다. Section 8.6에서 이야기한 것처럼 과적합은 일반적으로 기본 모델(또는 그 매개 변수화)가 지나치게 잘 구부러지고, 훈련데이터에 대한 표현력이 강할때 발생한다. 따라서 과적합을 일으키는 근본적인 원인을 살펴보고 선형 회귀의 관점에서 과적합을 완화할 수 있도록 해당 문제를 해결해야한다.
4. 매개변수 사전확률과 손실함수와의 관계 : 손실함수는 자주 확률론적 모델에에서 파생되거나 유도된다. 따라서, 손실 함수와 이러한 손실을 유발하는 기본 사전 가정 사이의 연관성을 파악해야한다.
5. 모델의 불확실성 : 모델을 정하고 매개변수를 선택하는 과정에서 유한하고 잠재적으로 큰 데이터에 대해서만 접근할수 있다. 이 제한된 양의 훈련 데이터는 모든 가능한 시나리오를 설명할 수 없다는 점을 감안한다면, 테스트 시 모델 예측의 신뢰도를 얻기 위해 나머지 매개 변수 불확실성을 설명하고자 할 수 있다. 또한, 훈련 세트가 더 작을수록 불확실성 모델링이 더 중요하다. 불확실성 모델의 일관성은 신뢰도를 갖춘 모델일 때만 가능하다.
Chpater 9. 선형 회귀 Content
- 이 챕서테엇는 3장, 5장, 6장, 7장의 수학적 개념을 사용하여 선형 회귀를 정의할 것이다 .
- 최적의 모델 매개 변수를 찾기 위해 최대 가능성(maximum likelihood)과 최대 사후 추정(maximum a posteriori estimation)에 대해 논의할 것이다.
- 이러한 매개 변수 추정치를 사용하여 일반화 오류와 과적합에 대해 간략하게 살펴 볼 것이다.
- Chapter의 마지막 부분에서, 최대 가능성과 최대 사후 추정에서 마주하는 일부 문제를 제거한 베이지안 선형 회귀(Bayesian Linear Regression)에 대해 논의할 것 이다. 해당 선형 회귀 모델은 더 높은 수준에서 모델 매개 변수에 대해 추론할 수 있게 해줄 것이다.
