Weight initialization 을 진행해야되는 이유?
- 아래의 그래프와 같이 학습된 결과 값의 에러값을 비교해 봤을때, good initializaion이 일어났을 때, 더 좋은 예측 손실 값을 얻은 것을 알 수 있다. ( initializaion - 뒤에 N 표시)
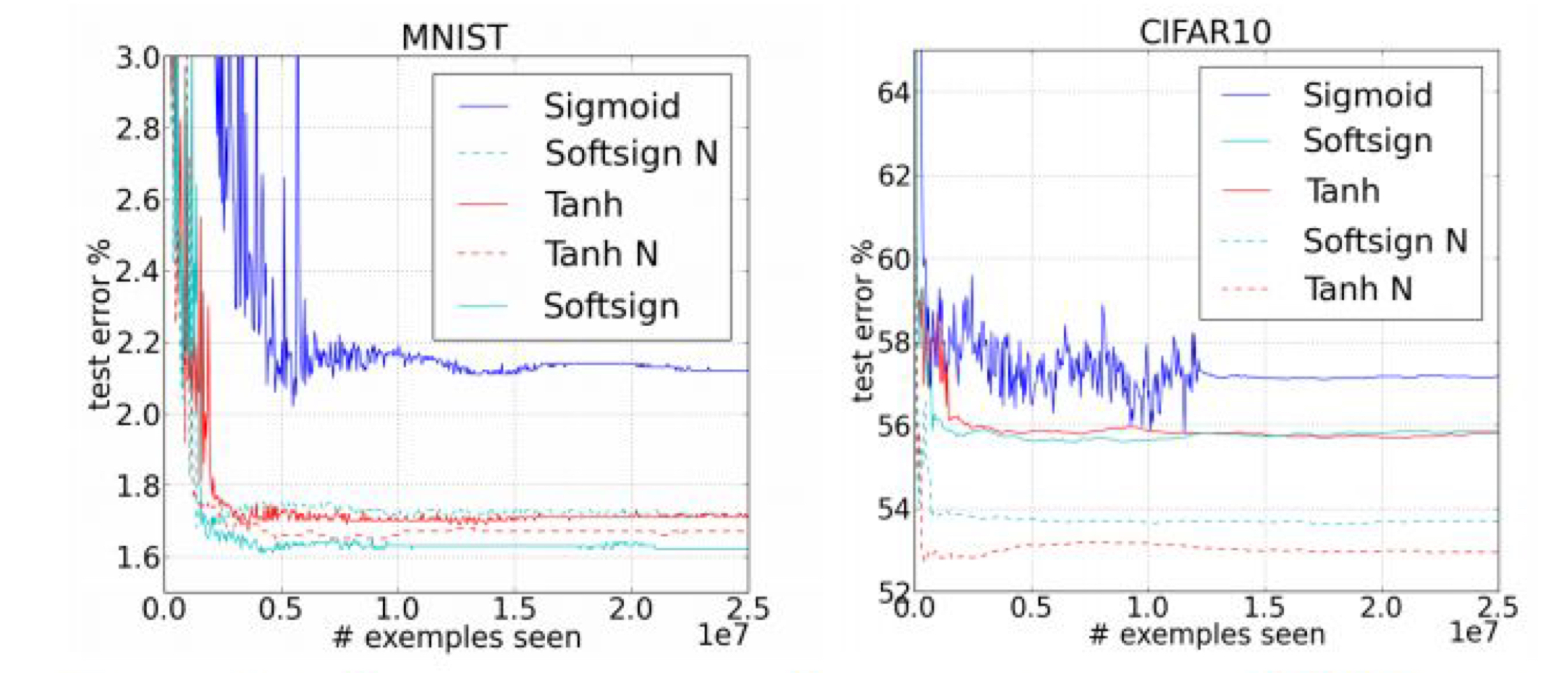
- 현명한 initialization 방법 :
- 0으로 초기화 하지 않는다.
- Geoffrey Hinton (2006) - " A Fast learning Algorithm for Deep Belief Nets" - Restricted Boltzmann Machine
- Xavier initiallization/ He initializaion
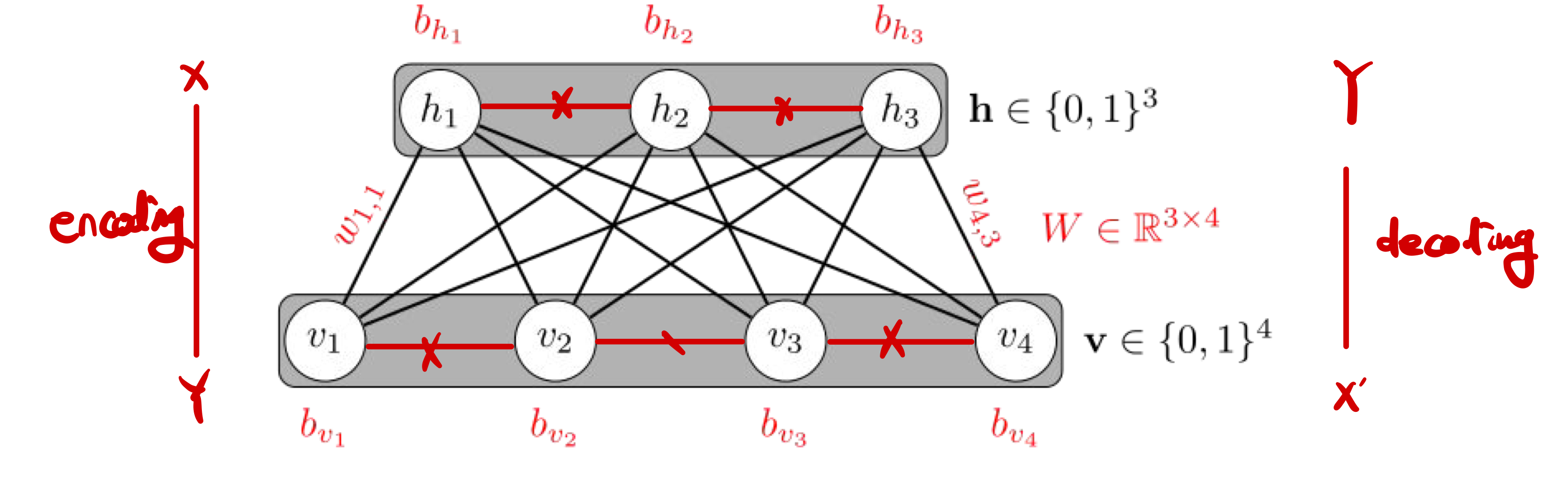
Initializaion 의 초창기 - Restricted Boltzman Machine ( RBM )
RBM 이란 : 같은 layer에 있는 node끼리는 연결하지 않으며, layer끼리 fully connection을 이용해서, Weight값을 초기화 하는 방법이다. Pre-training과 Fine tuning과정을 거쳐 initialize를 하는 초창기 모델이다.
- Pre Training/ Fine Tuning 과정( 도식화)
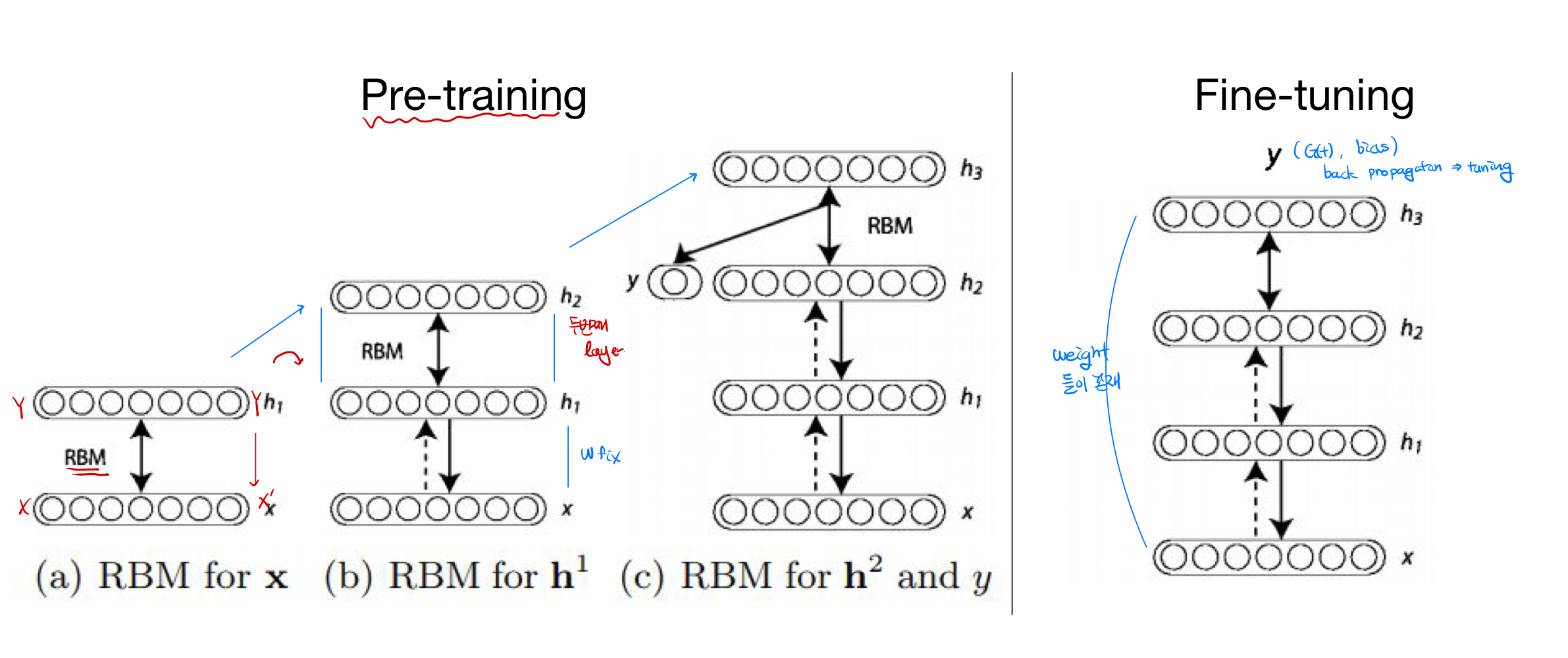
- 현재에는 잘 활용되지 않음( Pre-training과 Fine Tuning이 번거로움)
Xavier / He initializaion
- Pre-training과 Fine Tuning과정이 없음
- Xavier initialization : n은 layer수, 평균은 0, 표준편차는 2로 맞춘 모델, Normal,과 Uniform모델 존재
- He initialization : n은 layer수, 평균은 0, 표준편차는 2로 맞춘 모델, Normal,과 Uniform모델 존재, xavier과 차이점은 nout값이 존재 하지 않는 초기화 모델

- Mnist NN with Xavier
# Lab 10 MNIST and softmax
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import random
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# for reproducibility
random.seed(777)
torch.manual_seed(777)
if device == 'cuda':
torch.cuda.manual_seed_all(777)
# parameters
learning_rate = 0.001
training_epochs = 15
batch_size = 100
# MNIST dataset
mnist_train = dsets.MNIST(root='MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/',
train=False,
transform=transforms.ToTensor(),
download=True)
# dataset loader
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
# nn layers
linear1 = torch.nn.Linear(784, 256, bias=True)
linear2 = torch.nn.Linear(256, 256, bias=True)
linear3 = torch.nn.Linear(256, 10, bias=True)
relu = torch.nn.ReLU()
# xavier initialization
torch.nn.init.xavier_uniform_(linear1.weight)
torch.nn.init.xavier_uniform_(linear2.weight)
torch.nn.init.xavier_uniform_(linear3.weight)
# model
model = torch.nn.Sequential(linear1, relu, linear2, relu, linear3).to(device)
# define cost/loss & optimizer
criterion = torch.nn.CrossEntropyLoss().to(device) # Softmax is internally computed.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
total_batch = len(data_loader)
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader:
# reshape input image into [batch_size by 784]
# label is not one-hot encoded
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning finished')
사회적 가치를 실현하는 프로그래머