RNN seq2seq
seq2seq
- Seq2Seq가 잘 적용되는 예 : chatbot, 번역

- 다음과 같은 상황에서는 잘 대답할 수 있을까? 대부분의 모델은 단어가 입력됨에 동시에 다음단어를 예측해서 출력됨으로 긍정-부정으로 이어지는 문장같은 경우 예측해서 대답하기가 쉽지 않음. 이러한 경우 seq2seq모델이 사용됨

Apply Seq2seq
Encoder - decoder
- seq2seq모델의 대표적인 특징으로 Encoder에 모든 문장이 입력되고 난뒤, decoder에 모든 문장을 입력받아 전달함. 그리고 hidden state를 통해 단어가 모두 입력된 다음 셀로 전달하게 되어, 모든 문장을 듣고, 말하는 방식이 적용될 수 있는 모델임
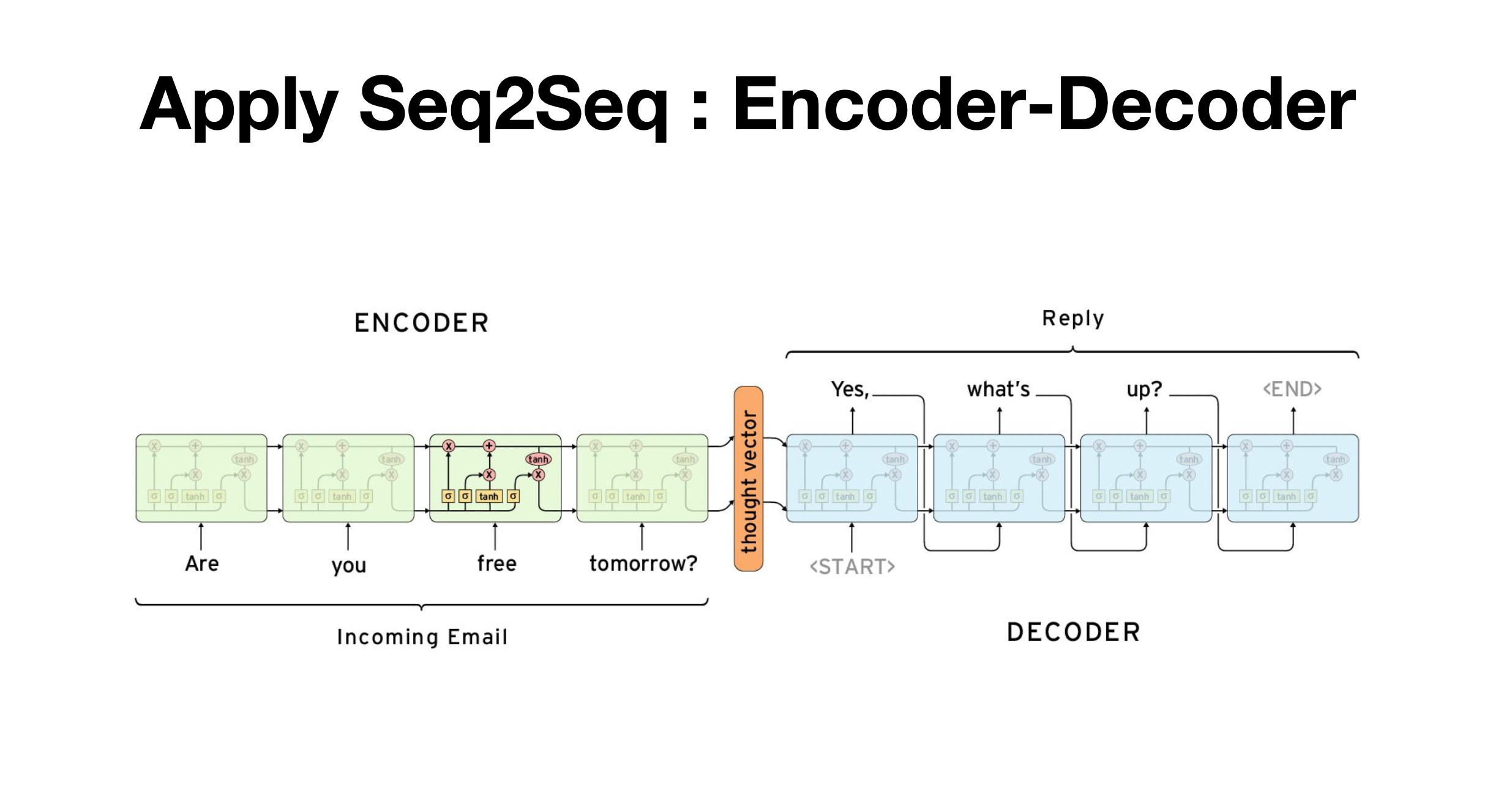
- source text를 target text로 바꿔야하는 과정임. 각각 training/test set으로 나눠줘야함
- 아래의 코드로 전반적인 흐름을 파악할 수 있음
import random
import torch
import torch.nn as nn
from torch import optim
# declare max length for sentence
SOURCE_MAX_LENGTH = 10
TARGET_MAX_LENGTH = 12
# preprocess the corpus
load_pairs, load_source_vocab, load_target_vocab = preprocess(raw, SOURCE_MAX_LENGTH, TARGET_MAX_LENGTH)
print(random.choice(load_pairs))
# declare the encoder and the decoder
enc_hidden_size = 16
dec_hidden_size = enc_hidden_size
enc = Encoder(load_source_vocab.n_vocab, enc_hidden_size).to(device)
dec = Decoder(dec_hidden_size, load_target_vocab.n_vocab).to(device)
# train seq2seq model
train(load_pairs, load_source_vocab, load_target_vocab, enc, dec, 5000, print_every=1000)
# check the model with given data
evaluate(load_pairs, load_source_vocab, load_target_vocab, enc, dec, TARGET_MAX_LENGTH)Data Processing
torch.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
raw = ["I feel hungry. 나는 배가 고프다.",
"Pytorch is very easy. 파이토치는 매우 쉽다.",
"Pytorch is a framework for deep learning. 파이토치는 딥러닝을 위한 프레임워크이다.",
"Pytorch is very clear to use. 파이토치는 사용하기 매우 직관적이다."]
# fix token for "start of sentence" and "end of sentence"
SOS_token = 0
EOS_token = 1
# class for vocabulary related information of data
class Vocab:
def __init__(self):
self.vocab2index = {"<SOS>": SOS_token, "<EOS>": EOS_token}
self.index2vocab = {SOS_token: "<SOS>", EOS_token: "<EOS>"}
self.vocab_count = {}
self.n_vocab = len(self.vocab2index)
def add_vocab(self, sentence):
for word in sentence.split(" "):
if word not in self.vocab2index:
self.vocab2index[word] = self.n_vocab
self.vocab_count[word] = 1
self.index2vocab[self.n_vocab] = word
self.n_vocab += 1
else:
self.vocab_count[word] += 1
# filter out the long sentence from source and target data
def filter_pair(pair, source_max_length, target_max_length):
return len(pair[0].split(" ")) < source_max_length and len(pair[1].split(" ")) < target_max_length
# read and preprocess the corpus data
def preprocess(corpus, source_max_length, target_max_length):
print("reading corpus...")
pairs = []
for line in corpus:
pairs.append([s for s in line.strip().lower().split("\t")])
print("Read {} sentence pairs".format(len(pairs)))
pairs = [pair for pair in pairs if filter_pair(pair, source_max_length, target_max_length)]
print("Trimmed to {} sentence pairs".format(len(pairs)))
source_vocab = Vocab()
target_vocab = Vocab()
print("Counting words...")
for pair in pairs:
source_vocab.add_vocab(pair[0])
target_vocab.add_vocab(pair[1])
print("source vocab size =", source_vocab.n_vocab)
print("target vocab size =", target_vocab.n_vocab)
return pairs, source_vocab, target_vocab
Neaural Net Setting
- Encoder, Decoder를 정희하는 코드부분
# declare simple encoder
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
x, hidden = self.gru(x, hidden)
return x, hidden
# declare simple decoder
class Decoder(nn.Module):
def __init__(self, hidden_size, output_size):
super(Decoder, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, x, hidden):
x = self.embedding(x).view(1, 1, -1)
x, hidden = self.gru(x, hidden)
x = self.softmax(self.out(x[0]))
return x, hidden
# convert sentence to the index tensor
def tensorize(vocab, sentence):
indexes = [vocab.vocab2index[word] for word in sentence.split(" ")]
indexes.append(vocab.vocab2index["<EOS>"])
return torch.Tensor(indexes).long().to(device).view(-1, 1)
Training
tensorize: sentence를 one-hot encoding으로 바꿔주는 함수
# convert sentence to the index tensor
def tensorize(vocab, sentence):
indexes = [vocab.vocab2index[word] for word in sentence.split(" ")]
indexes.append(vocab.vocab2index["<EOS>"])
return torch.Tensor(indexes).long().to(device).view(-1, 1)
# training seq2seq
def train(pairs, source_vocab, target_vocab, encoder, decoder, n_iter, print_every=1000, learning_rate=0.01):
loss_total = 0
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
training_batch = [random.choice(pairs) for _ in range(n_iter)]
training_source = [tensorize(source_vocab, pair[0]) for pair in training_batch]
training_target = [tensorize(target_vocab, pair[1]) for pair in training_batch]
criterion = nn.NLLLoss()
for i in range(1, n_iter + 1):
source_tensor = training_source[i - 1]
target_tensor = training_target[i - 1]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device)
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
source_length = source_tensor.size(0)
target_length = target_tensor.size(0)
loss = 0
for enc_input in range(source_length):
_, encoder_hidden = encoder(source_tensor[enc_input], encoder_hidden)
decoder_input = torch.Tensor([[SOS_token]]).long().to(device)
decoder_hidden = encoder_hidden # connect encoder output to decoder input
for di in range(target_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
loss += criterion(decoder_output, target_tensor[di])
decoder_input = target_tensor[di] # teacher forcing
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
loss_iter = loss.item() / target_length
loss_total += loss_iter
if i % print_every == 0:
loss_avg = loss_total / print_every
loss_total = 0
print("[{} - {}%] loss = {:05.4f}".format(i, i / n_iter * 100, loss_avg))Evaluation
# insert given sentence to check the training
def evaluate(pairs, source_vocab, target_vocab, encoder, decoder, target_max_length):
for pair in pairs:
print(">", pair[0])
print("=", pair[1])
source_tensor = tensorize(source_vocab, pair[0])
source_length = source_tensor.size()[0]
encoder_hidden = torch.zeros([1, 1, encoder.hidden_size]).to(device)
for ei in range(source_length):
_, encoder_hidden = encoder(source_tensor[ei], encoder_hidden)
decoder_input = torch.Tensor([[SOS_token]], device=device).long()
decoder_hidden = encoder_hidden
decoded_words = []
for di in range(target_max_length):
decoder_output, decoder_hidden = decoder(decoder_input, decoder_hidden)
_, top_index = decoder_output.data.topk(1)
if top_index.item() == EOS_token:
decoded_words.append("<EOS>")
break
else:
decoded_words.append(target_vocab.index2vocab[top_index.item()])
decoder_input = top_index.squeeze().detach()
predict_words = decoded_words
predict_sentence = " ".join(predict_words)
print("<", predict_sentence)
print("")
사회적 가치를 실현하는 프로그래머