RNN - Time Series
Time Series data
Time Series Data란? 시계열 데이터라고 불리며, 일정한 시간 간격으로 배치된 데이터를 말한다. 대표적인 예로는 주가 데이터를 예로 들 수 있다.
Apply RNN
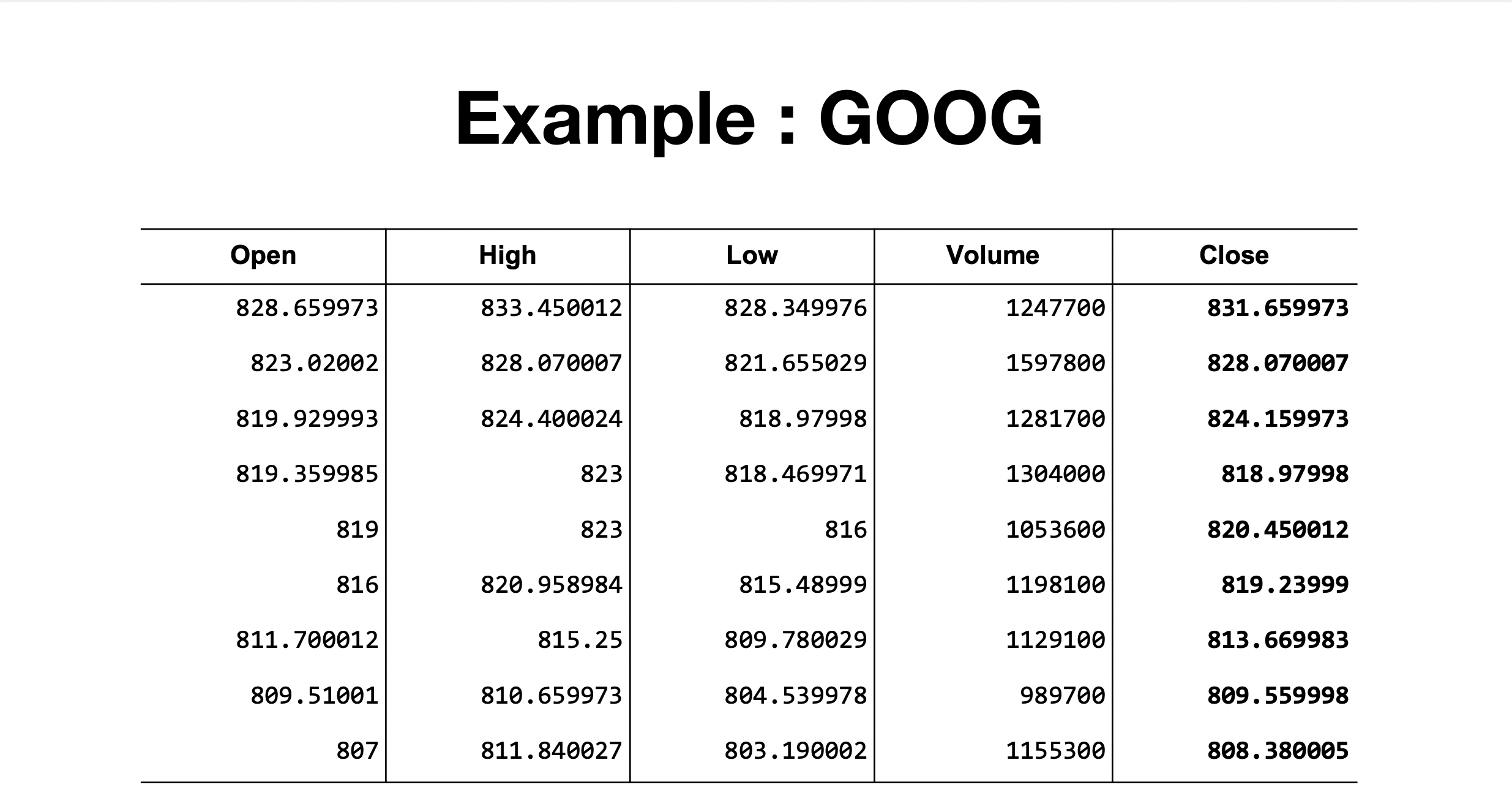
- 사용할 데이터 : 구글 주가 데이터
Many-to-one
- 이 모델은 7일간의 주가데이터를 이용해 8일차의 주가데이터를 예측하는 모델을 전제함(물론 맞은 전제는 아님. 8일차를 이용하기 위해 7일차의 데이터만 필요하거나 필요하지 않을 수도 있음. 다만 이 모델은 그렇게 전제하고 있음)
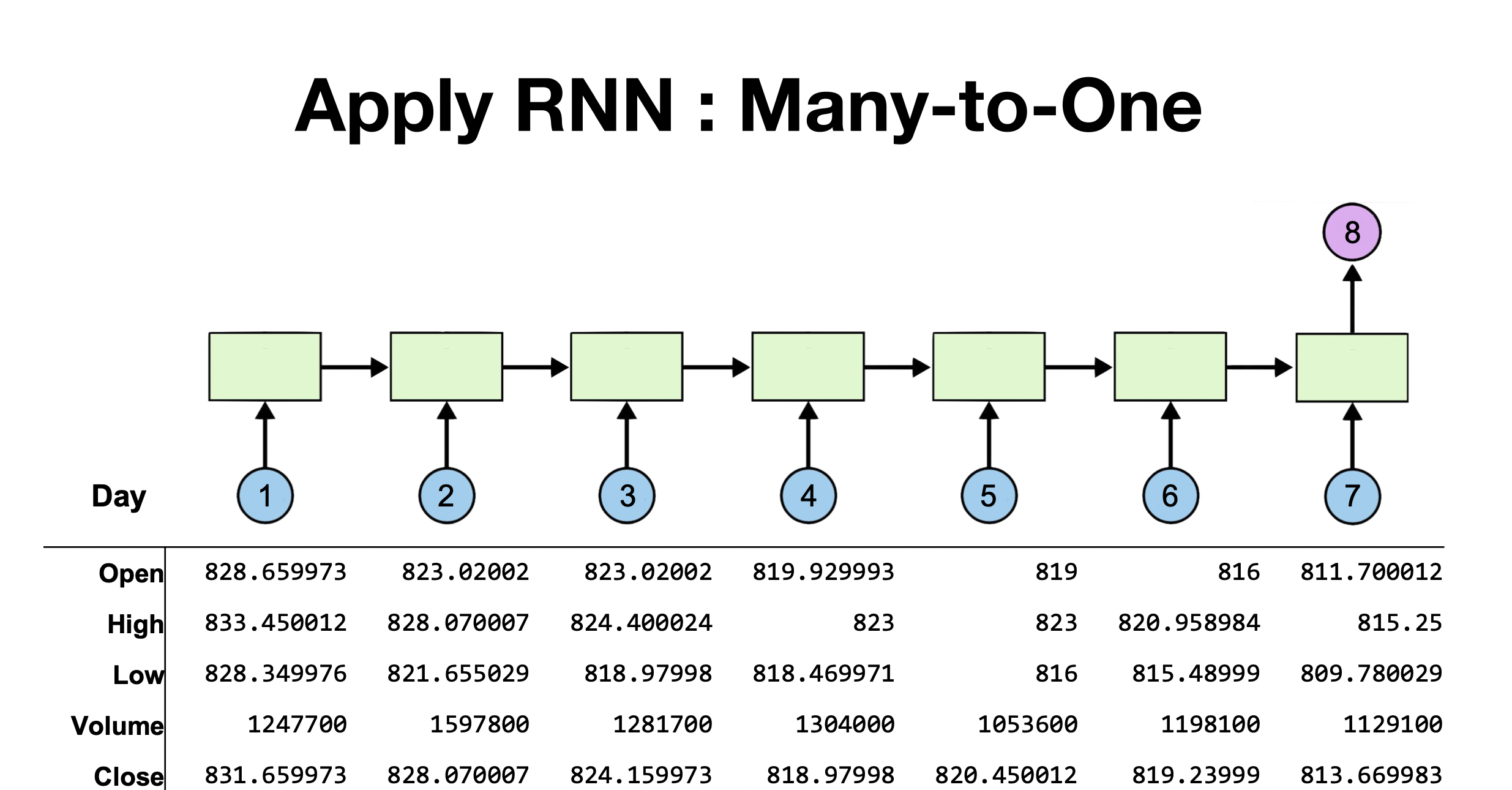
- FC layer가 없다면 5개의 dimesion을 가지고 잇는 데이터를 입력을 받아, 그전날의 hidden state를 전달받아 넘기게 되고 1개의 dimesion으로 출력하게 됨.
- 다만 1개의 디멘션으로 압축하는 것은 모델에 많은 부담을 주게 됨으로, 추가로 데이터를 맞추는 FC Layer을 줘 1개의 dimension으로 출력하지 않을 수있도록, 모델의 부담을 덜어줌.
Data Reading
- 미리 데이터를 스케일링을 해주어, 학습될 때 부담을 줄여줌
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# Random seed to make results deterministic and reproducible
torch.manual_seed(0)
# scaling function for input data
def minmax_scaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7)
# hyper parameters
seq_length = 7
data_dim = 5
hidden_dim = 10
output_dim = 1
learning_rate = 0.01
iterations = 500
# load data
xy = np.loadtxt("data-02-stock_daily.csv", delimiter=",")
xy = xy[::-1] # reverse order
# split train-test set
train_size = int(len(xy) * 0.7)
train_set = xy[0:train_size]
test_set = xy[train_size - seq_length:]
# scaling data
train_set = minmax_scaler(train_set)
test_set = minmax_scaler(test_set)
# make train-test dataset to input
trainX, trainY = build_dataset(train_set, seq_length)
testX, testY = build_dataset(test_set, seq_length)
# convert to tensor
trainX_tensor = torch.FloatTensor(trainX)
trainY_tensor = torch.FloatTensor(trainY)
testX_tensor = torch.FloatTensor(testX)
testY_tensor = torch.FloatTensor(testY)Neural Net Setting
class Net(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, layers):
super(Net, self).__init__()
self.rnn = torch.nn.LSTM(input_dim, hidden_dim, num_layers=layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, output_dim, bias=True)
def forward(self, x):
x, _status = self.rnn(x)
x = self.fc(x[:, -1])
return x
net = Net(data_dim, hidden_dim, output_dim, 1)
# loss & optimizer setting
criterion = torch.nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
Train & Evaluation
# start training
for i in range(iterations):
optimizer.zero_grad()
outputs = net(trainX_tensor)
loss = criterion(outputs, trainY_tensor)
loss.backward()
optimizer.step()
print(i, loss.item())
plt.plot(testY)
plt.plot(net(testX_tensor).data.numpy())
plt.legend(['original', 'prediction'])
plt.show()
사회적 가치를 실현하는 프로그래머