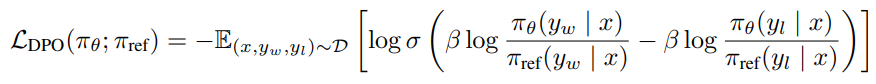[Paper Review] Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Paper Review

Abstract
DPO는 Pretrained LM에 human preference에 반영하려는 기존의 RLHF(Reinforcement Learning from Human Feedback) 를 단순한 classification loss로 풀어냈다. 그리하여 기존 RLHF pipeline(Reward Model 학습 -> Policy Update) 에서 Reward Model 학습 과정을 생략하면서도 안정적인 학습 방법을 제시한다.
Preliminaries
RLHF Pipeline
기존의 RLHF Pipeline은 아래 3개의 phase로 진행된다.
1) SFT(Supervised Fine-Tuning)
Pretrained LM은 우리가 원하는 내용 혹은 형태로 답변하지 않을 수 있다. 그러므로 Reward Model을 학습하기 위한 데이터셋을 LM으로부터 얻기 이전에 미리 정제된 데이터로 supervised fine-tuning 단계를 거쳐 model 를 얻는다.
2) Reward Modeling
Reward Model 을 학습하기 위해, 먼저 위에서 학습한 에 prompt 를 Input으로 주고, 인간이 선호할 만한/그렇지 않은 답변 pair 를 생성하도록 한다. (Human Labeling)
이후에는 각 pair에 대한 선호로부터 전체 선호도를 모델링하는 bradley-Terry 모델 등을 기반으로 Reward Model을 학습하며, NLL Loss 형태로 이를 나타내면 아래와 같다.
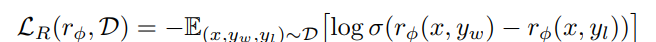
3) RL Fine-Tuning
마지막으로는 LM을 학습시키는데, 위에서 학습한 Reward Model이 출력하는 reward를 기반으로 KL-constrained Reward Maximation Objective를 구성한다. 를 사용하는 것은 Reference model과 policy(update된 LM)이 너무 멀어지지 않도록 하기 위함이다.
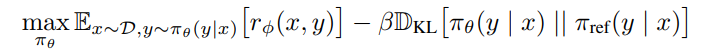
위와 같은 방식으로
Main Apporach : DPO
논문에서 제시하는 DPO는 위 3)의 KL-constrained objective를 변형하여 아래의 새로운 objective로 만들어낸다.

여기서 은 desired policy이고, 는 식 유도를 위해 쓰인 partition function이며, 기존 RLHF와 같이 relative log likelihood objective를 구성하는 과정에서 소거된다. 위 식을 유도하는 과정과 최종 Loss function은 아래와 같다.