Paper Review
1.[Paper Review] Text Embeddings by Weakly-Supervised Contrastive Pre-training (E5)

E5는 CCPairs라는 새로운 text pair dataset을 만들고, contrastive learning을 적용하여 retrieval과 같은 여러 single-vector representation이 필요한 task에서 좋은 성능을 보이는 모델이다. 사실 논문의
2.[Paper Review] node2vec : Scalable Feature Learning for Networks
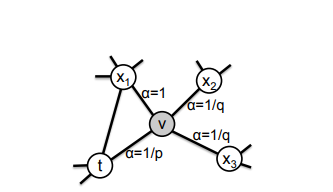
Node2vec은 2016년 논문으로, Node Classification, Link Prediciton 등의 task를 수행하기 위해 node와 edge의 정보를 담은 representation이 필요하다전문 지식에 기반한 domain-specific feature의
3.[Paper Review] Hierarchical Graph Transformer with Adaptive Node Sampling
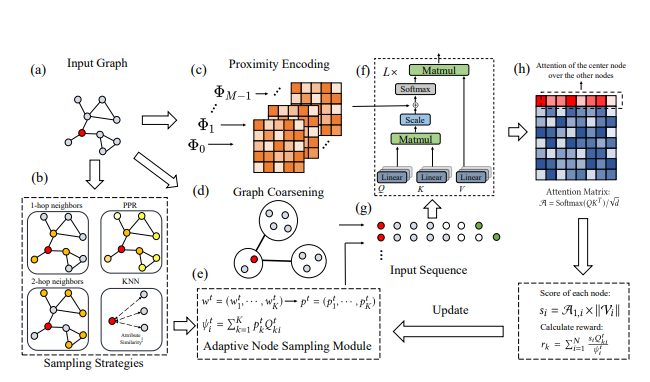
Computationally inefficientFull Attention Mechanism이 전체 그래프 특성과 상관 없는 노드 정보를 많이 반영(noise). \-> 그래서 기존 Graph Transformer Architecture들은 Receptive Fiel
4.[Paper Review] do transformers really perform bad for graph representation (Graphormer)
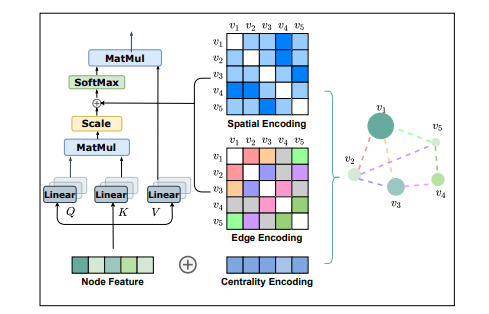
자연어처리, 컴퓨터비전 등 많은 분야에서 이미 Transformer의 활용성이 검증된 반면, 그래프 데이터에 대해서는 그 활용성이 확실히 검증되지 않았습니다. Transformer를 그래프 데이터에 잘 활용하려면 sequence modeling을 위해 설계된 Trans
5.[Paper Review] Towards Debiasing Sentence Representations (ACL 2020)

기존 debiasing method는 주로 단어 임베딩에 대한 debiasing에 집중한다. 하지만 단어가 등장하는 맥락에 따라 단어의 의미가 변하므로 문장에 대한 debiasing이 필요하다. 이에 논문에서는 문장 내의 bias를 제거하면서 sentence-level
6.[Paper Review] SURE: SUMMARIZING RETRIEVALS USING ANSWER CANDIDATES FOR OPEN-DOMAIN QA OF LLMS
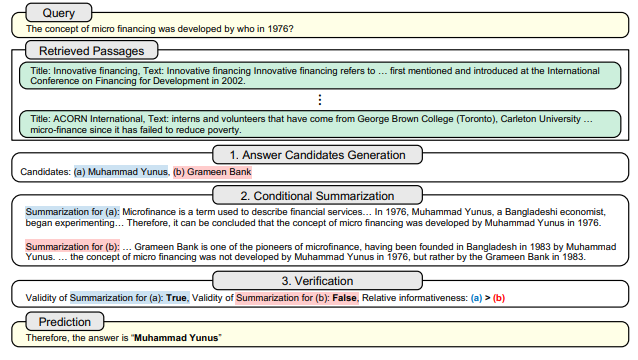
Open-Domain QA Task에서 LLM을 할 때, 널리 사용하는 방법은 외부 Retriever로 Retrieve한 Passages를 Question과 같이 Prompt로서 주는 Retrieval-Augmented Generation(RAG)입니다. 하지만 이러한
7.[Paper Review] LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
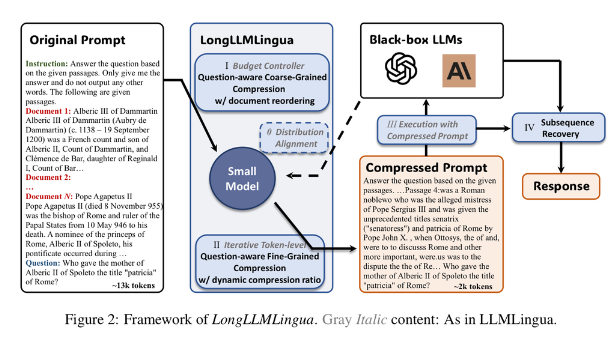
LongLLMLingua는 prompt를 임의의 M개 segment로 나눈 후 token level compression을 하는 LLMLingua에 아래 모듈을 더했습니다. compression 기준이 되는 perplexity는 작은 LLM(LLAMA2-7B-Chat)
8.[Paper Review] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
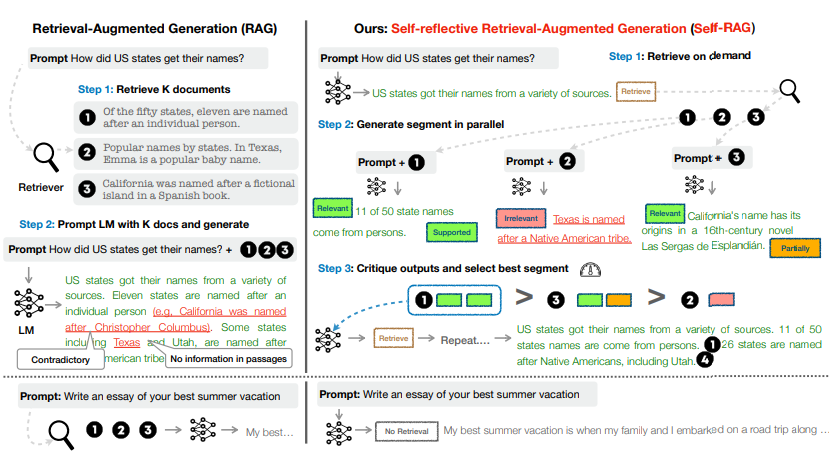
SELF-RAG는 Open-Domain QA Task에서 기존 RAG의 Limitation : Parametric Knowledge로 충분한 상황에서 Retrieval이 방해되는 문제, Question과 관계가 적은 Passages를 Retrieve하는 문제 등을 해결
9.[Paper Review] Merging Generated and Retrieved Knowledge for Open-Domain QA
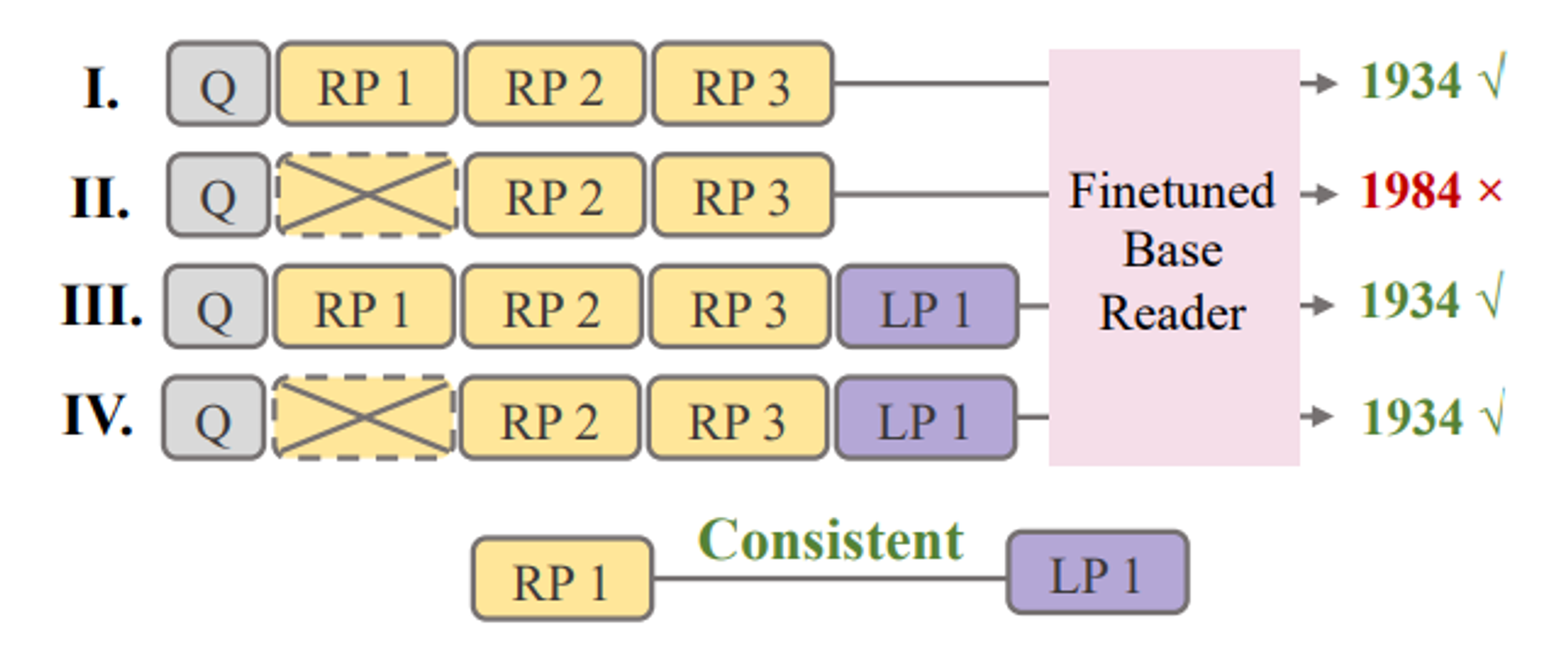
기존 ODQA는 Retrieval module로 External corpus의 지식을 활용하지만 External corpus의 Knowledge coverage가 insufficient함LLM에 Question을 주고 관련 knowledge를 생성해 활용할 수 있음Ha
10.[Paper Review] Direct Preference Optimization: Your Language Model is Secretly a Reward Model

\[Link]DPO는 Pretrained LM에 human preference에 반영하려는 기존의 RLHF(Reinforcement Learning from Human Feedback) 를 단순한 classification loss로 풀어냈다. 그리하여 기존 RLHF