Abstract
- 기존 ODQA는 Retrieval module로 External corpus의 지식을 활용
- 하지만 External corpus의 Knowledge coverage가 insufficient함
- LLM에 Question을 주고 관련 knowledge를 생성해 활용할 수 있음
-
Hallucination 문제가 있음
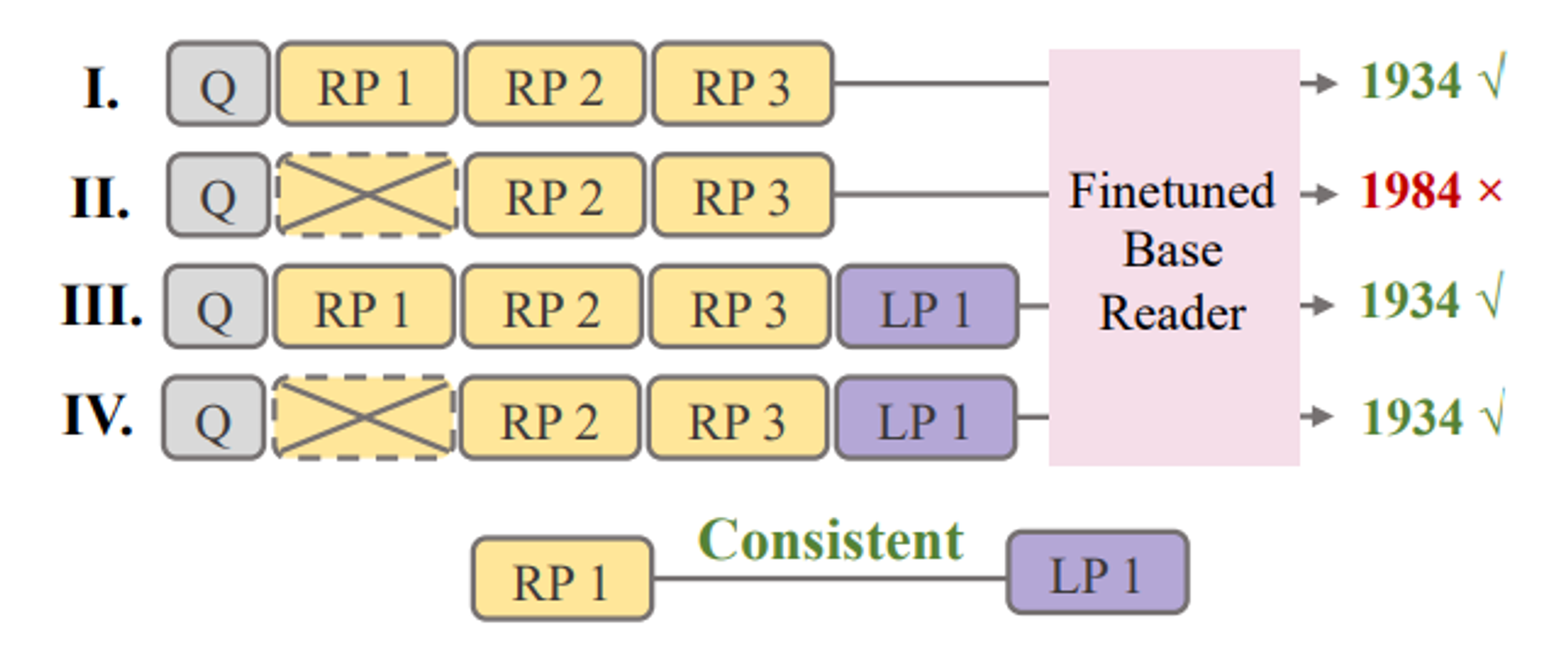
→ Idea : Evidential + Retrieved passage와 consistent한 LLM generated passage를 사용하자.
-
- evidentiality, consistency를 Roberta(Discriminator)로 predict
- FiD에 [Q+Retrieved Passage(RP) + Generated Passage(RP)] triple을 N(10)개 넣어준다.
- 이 때, RP-LP pair를 최대한 ‘consistent’하게 matching한다.
(Silver)Labeling Strategy + Discriminator Learning
Training set labeling for Discriminator(D_e, D_c for evidentiality, consistency)
- D_e : [Q+RP] → Evidential/Not Evidential
- D_c : [Q+RP(Evidential)+LP] → Consistent/Conflicting
1. Evidentiality
Evidentiality는 Question Q에 대해 모델이 정답을 맞추도록 돕는지 measure하는 척도
- Leave-One-Out(LOO) Generation → target passage p가 빠졌을 때 correct → incorrect로 prediction flip이 있을 때 p를 Evidential하다고 Label
2. Consistency
LLM generated passage LP에 대한 measurement. Evidential한 RP와 동일한 역할을 하는 LP가 있을 때 RP-LP pair를 Consistent하다고 Label
3. Compatible
a passage pair RP-LP is compatible if Evidential & Consistent
4. Discriminator Learning
1~3을 통해 준비한 Label로 Discriminator d_c와 d_e를 학습합니다. 모델은 RoBERTa-large를 사용합니다.
Compatibility-guided Optimal Matching
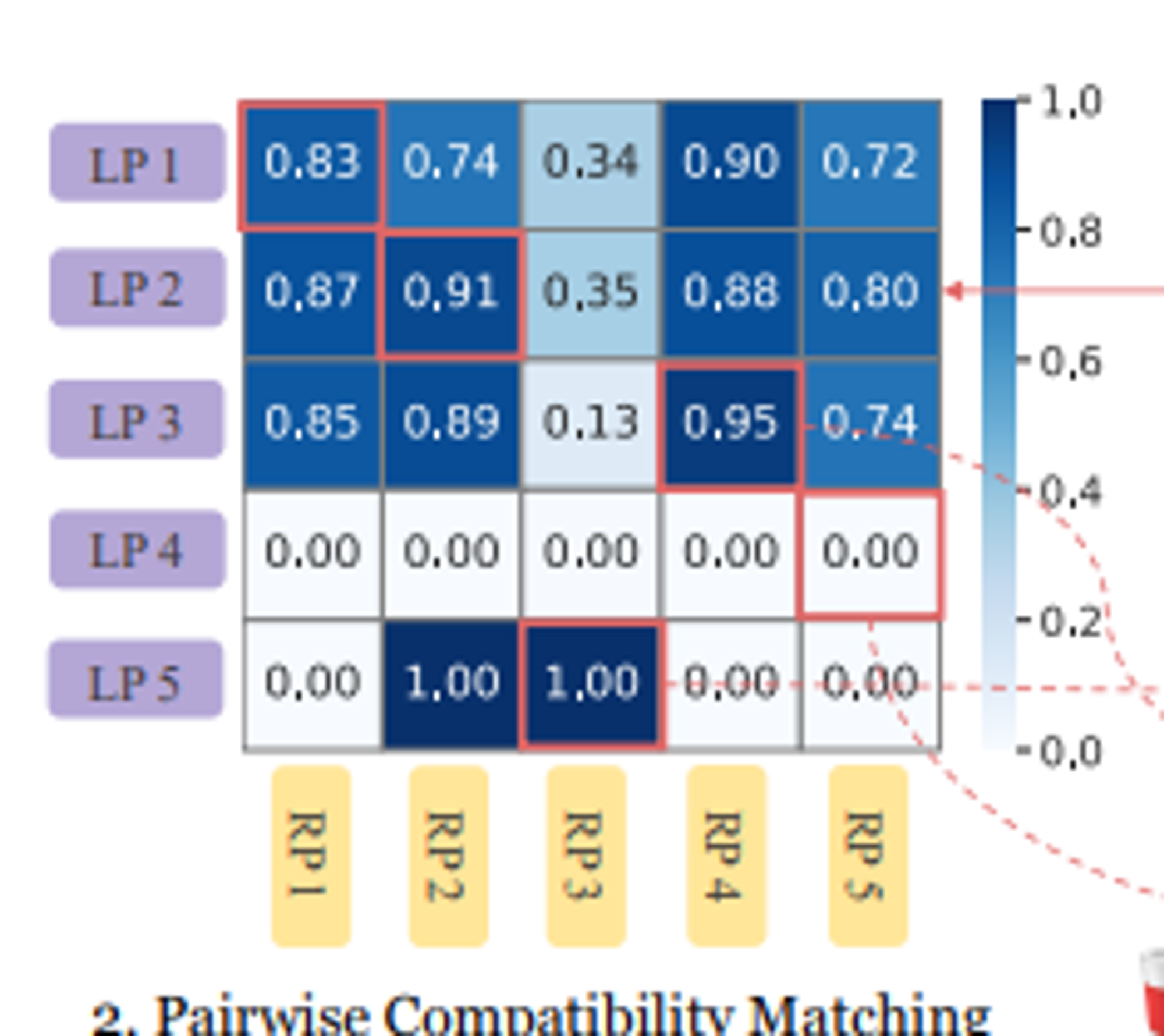
N개의 LP와 RP를 matching할 때는 Compatibility의 합이 최대가 되도록 하는데, 우선 Compatibility Score는 위에 언급한 Discriminator에 의한 분류 확률([0,1])을 기반으로 계산됩니다.
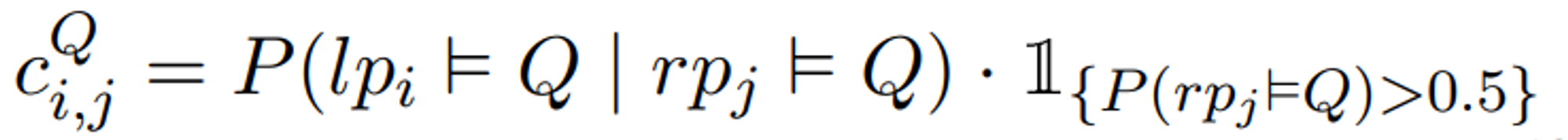
- 수식 앞단의 확률 P는 수식 상에서는 조건부 확률처럼 보이지만, 사실은 RP-LP pair의 Consistency를 판단하는 d_c가 RP-LP pair를 ‘consistent’하다고 분류한 확률입니다.
- 뒤에 붙은 indicator function은 RP의 evidentiality를 판단하는 d_e가 RP-LP pair 중 RP에 대해 ‘evidential’하다고 분류한 확률입니다.
→ 정리하자면, d_e를 통해 Evidential하다고 분류한 RP에 대해서 가장 consistent한 LP를 matching하여 ‘Compatible’한 pair를 만드는 과정입니다.
- 위 점수를 모든 pair(N*N=100개 pair)에 대해 계산하고, 최적화 알고리즘을 통해 점수의 합을 최대로 하는 pair N(10)개를 선택하여 FiD에 넣어줍니다.
- 이를 다른 종류의 노드 간에만 edge가 존재하는 bipartite graph에서의 weight를 최적화하는 문제로 보고 hungarian-matching algorithm을 사용합니다.
Final Prediction

FiD가 (Q-RP-LP) Pair N개(N=10)를 Input으로 받아 주어진 Question에 대한 prediction을 output으로 내놓습니다.
이 때, FiD에 special token을 추가합니다.
- ‘question’
- ‘generated passage’
- ‘retrieved passage’
위의 세가지 prefix를 special token으로 추가하고 Q,LP, RP 앞에 각각 넣어줍니다.
그리고 LP가 항상 RP 앞에 오도록 순서를 고정(성능에 큰 영향)함으로써 모델이 Conlicting information이 있을 때 RP(Factual하다는 보장이 있으므로)에 집중하도록 하는 역할을 합니다.
