[Paper Review] LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
Paper Review
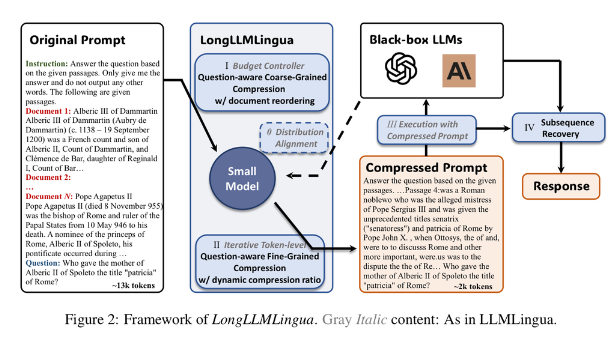
Abstract + Pipeline
LongLLMLingua는 prompt를 임의의 M개 segment로 나눈 후 token level compression을 하는 LLMLingua에 아래 모듈을 더했습니다. compression 기준이 되는 perplexity는 작은 LLM(LLAMA2-7B-Chat)으로 구하고 QA는 그보다 큰 LLM(GPT-3.5-Turbo와 LongChat-13b)로 합니다.
- Segment별로 나누는 이유는 token level compression을 하면서도 언어의 연결성을 최대한 보존하기 위해서라고 합니다. LongLLMLingua도 이를 그대로 이용했는데, segment size M 만 기존(100)과 다르게(200)했습니다.
- Question-aware Coarse-Grained Compression with document reordering
- Document별로 importance metric 를 구합니다.
- Filtering 기준은 perplexity인데, p(query|document)를 기준으로 filtering한 것이 성능에 가장 크게 기여한 것으로 보입니다. (일반적으로는 p(document|query) 사용)
- Dynamic Compression Ratio
- Token level compression을 적용할 때 document마다 compression ratio를 다르게 설정했습니다.
- Question-aware Fine-Grained Compression
- Compression(토큰을 없애는) threshold를 ‘contrastive perplexity’로 설정합니다.
- 한 토큰의 Contrastive perplexity는 document 앞에 question이 붙었을 때와 그렇지 않을 때 토큰의 perplexity의 차이입니다.
- Compression(토큰을 없애는) threshold를 ‘contrastive perplexity’로 설정합니다.
Method
1. Question-Aware Coarse-Grained Compression
이 단계에서는 각 document 의 importance score 를 구합니다. baseline인 LLMLingua에서는 를 document-level perplexity(Alpaca-7B로 구함)로 뒀는데, LongLLMLingua에서는 question과 관련 있는 document를 골라내기 위해 아래와 같이 를 계산합니다.(LLAMA-7B-Chat로 구함)
- perplexity of the question conditioned on different contexts
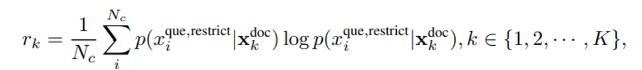
- 는 토큰 개수, 는 question에 를 붙인 것] - 여기서 는 'We can get the answer to this question in the given document's로, question과 document 같 interconnection을 강화해 hallucination을 완화하는 역할을 한다고 합니다. 또한 를 구하면 이를 가 낮은 document들은 걸러내고 개의 document만 남깁니다.
2. Document Reordering
Middle in lost를 완화하기 위해 document reordering을 하는 단계입니다. 이 때 를 기준으로 reodering을 합니다.(아마 내림차순 : 20pg figure7 compression 예시와 7pg table1에서 첫번째가 positive doc일 때 결과가 좋기 때문)
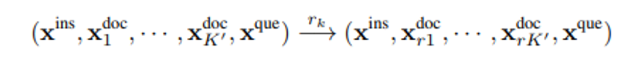
3. Question-Aware Fine-Grained Compression with dynamic compression ratio
위 step에서 filtering을 통해개의 document 가 남은 상황
→ Contrastive Perplexity 라는 metric을 기준으로 해당 metric이 낮은 token을 없애 compression을 합니다.
논문에서는 perplexity를 distribution shift caused by the condition of the question이라고 설명하는데, 이를 바탕으로 하나의 document 의 각 토큰 에 대한 importance metric 는 아래와 같습니다.
perplexity - perplexity
이후에는 전체 prompt를 구성하는 3가지 요소인 instruction, question, document마다 각기 다른 compression ratio 을 이용해 token level compression을 합니다. 다만 는 predefined이고, 는 아래와 같이 계산합니다.
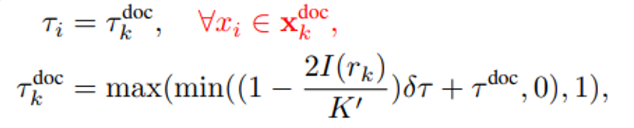
는 각각 token, document의 인덱스입니다. 아마 하나의 document 안에서는 같은 compression ratio가 적용된다는 맥락에서 둘 다 표기한 것 같습니다.
마지막으로, 계산한 Compression Ratio를 바탕으로 token level compression을 진행합니다. 아래 Experiments를 보면 알 수 있듯이 2배, 4배 compress한 Prompt를 QA에 사용했습니다.
4. Subsequence Recovery
이는 Token level compression의 결과로 정답 entity의 형태가 무너지는 현상을 완화하기 위한 모듈입니다. 아래를 보면 Compression 과정에서 가 낮은 토큰을 없애는 과정에서 정답 entity가 변형(일부 토큰 삭제)되고, Prompt에 있는 entity를 그대로 뱉는 LLM의 경향에 따라 최종 prediction도 변형되는 문제를 볼 수 있습니다.

- 이러한 문제를 해결하기 위해 논문에서는 Subsequence Recovery를 사용합니다.
1. prediction에서 compressed prompt와 겹치는 가장 긴 문자열 찾기 2. 해당 문자열과 가장 비슷하고 짧은 subsequence를 Originial Prompt에서 찾기 3. 2에서 찾은 문자열로 대치 → 원래의 entity 형태 보존
