[Paper Review] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Paper Review
Abstract
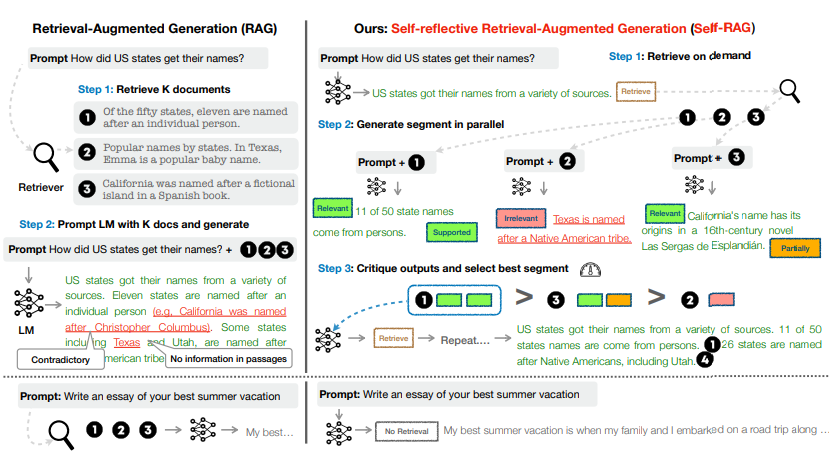
SELF-RAG는 Open-Domain QA Task에서 기존 RAG의 Limitation : Parametric Knowledge로 충분한 상황에서 Retrieval이 방해되는 문제, Question과 관계가 적은 Passages를 Retrieve하는 문제 등을 해결하려는 논문입니다.
SELF-RAG에서는 Retrieval 필요 여부, Retrieved Passages의 유효성, 최종 generation의 유효성 등을 판단하는 4가지(Retrieve, IsRel, IsSup, IsUse)의 Reflection token을 기존 출력에 더해 추가로 출력하도록 LLAMA-7B를 Fine-Tuing합니다. Reflection Token이 있는 데이터셋은 GPT-4를 이용해 만든 다음 LLAMA-7B에 Distill했습니다.
Reflection Tokens
SELF-RAG에는 Reflection Token이라는 4가지의 Special Token이 있습니다.
- Retrieval Token : Question 와 이전까지의 Answer 사이에 추가적인 Factual Grounding이 필요한지 여부를 결정합니다.
- Input : Question , Answer
- Output : Yes, No, Continue to use evidence
- Relevant Token : Retreived Passage 가 Question 와 Relevant한지 여부를 결정합니다.
- Input : Question , Answer , retrieved passage
- Output : Yes, No
- Supported Token
- Input : Question , Answer , retrieved passage
- Output : Yes, No
- Useful Token
- Input : Question , Answer , retrieved passage
- Output : Yes, No
Inference on SELF-RAG

Inference는 Generator Model 으로 이뤄집니다.
- 각 segment(sentence) step t마다 Reflection Token들과 새로운 sentence 를 생성합니다.
- 각 timestep t마다 sentence level beam search(size: B=2)로 top-B개 segment(sentence) continuation을 얻고, 마지막에 best sequence를 정합니다.
- Retrieval 여부는 Retrieval Token의 확률 를 Thresholding하여 정합니다.
- 생성된 sentence 의 score는 LM () probability와 Reflection Token의 가중합으로 평가합니다.
-
Retrieve ==YES일 때
1-1) Passages 를 Retrieve합니다.
1-2) 를 Input으로 받아 Relevant Token을 생성합니다.
1-3) 를 Input으로 받아 를 생성합니다.
- 각 Passage d에 대해 parallel하게 처리합니다.
1-4) 를 Input으로 받아 Useful Token, Support Token을 생성합니다.
1-5) LM( probability + Relevant, Useful, Support Token으로 만든 점수로 를 평가합니다.
-
Retrieve ==NO일 때
2-1) 를 input으로 를 생성합니다.2-2) 를 input으로 Useful Token을 생성합니다.
2-3) LM prob + Useful Token으로 만든 점수로 를 평가합니다.
Training SELF-RAG

- 위 Algorithm에서 x,y는 QA Task에서 Question, Answer에 해당합니다.
- Inference는 으로만 이뤄지지만 Training은 로 이뤄집니다.
- Reflection Token을 Corpus에 추가한 다음 모델을 학습합니다. (는 기존 Corpus로, 은 Token을 추가한 Corpus로 학습합니다.)
SELF-RAG의 학습은 크게 아래 과정으로 나뉩니다.
- Data Collecting for Critic Model with GPT-4
- GPT-4 → Distillation(Training with original corpus)
- Data Collecting for Generator Model
- Training (with curated corpus)
- 모두 LLAMA-7B를 사용합니다.
1. Data Collecting for Critic Model with GPT-4
각 Reflection Token에 맞는 prompt를 GPT-4에 주고 Token을 생성하도록 합니다.
2. GPT 4 → Distillation
아래 Objective로 Critic Model 를 Train합니다.
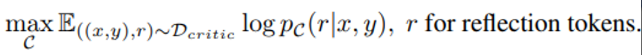
3. Data Collecting for Generator Model
Inference Time에서의 방법대로, 기존 학습 데이터의 input-output pair 을 Critic Model 에 넣어 Reflection Token을 구합니다. 이렇게 구한 Reflection Token을 output에 augment하여 input-output-reflection triple 을 만들어 에 추가합니다.
4. Training
Generator Model 은 input 를 받아 을 출력하도록 학습됩니다.
- Retrieved text chunks는 와 로 mask합니다.
- Masking을 안하면 이 retrieved passages 자체를 생성하도록 잘못 학습될 우려가 있다고 합니다. Without masking, SELF-RAG would learn to generate the inserted passages by itself, instead of learning how to effectively incorporate retrieved passages, causing train-test time discrepancy.
