[Paper Review] Text Embeddings by Weakly-Supervised Contrastive Pre-training (E5)
Paper Review

Abstract
E5는 CCPairs라는 새로운 text pair dataset을 만들고, contrastive learning을 적용하여 retrieval과 같은 여러 single-vector representation이 필요한 task에서 좋은 성능을 보이는 모델이다. 사실 논문의 주된 내용은 모델이 아니라 데이터셋을 설명하는 것에 가깝다. 특별한 architecture가 사용된 것은 아님에도 SOTA를 달성하는 모습을 보면, 모델의 성능에 있어 학습 데이터의 중요성을 확연히 느낄 수 있다.
CCPairs Dataset
논문에서는 기존의 text pair dataset의 경우 random cropping 등의 방법을 통해 데이터 규모를 증가시키기 때문에 noisy한 supervision signal을 준다고 지적한다.
이와 달리 CCPairs는 아래의 두 가지 방법을 이용해 '잘 정제된' dataset이므로 모델 성능 향상에 기여했다는게 논문의 내용이다.
- Semi-Structred Data Sources 를 모음
- Consistency-based filter를 사용해 모은 데이터를 정제
1. Semi-Structred Data Sources
CCPairs는 우선 아래 항목과 같은 다양한 semi-sturectured data source로 구성되었고, 형태는 (question-passage) pair의 형태로 되어있다.
- 커뮤니티 Reddit에서 가져온 post - comment pair
- Stackexchange에서 가져온 question - upvoted answer pair
- Wikipedia에서 가져온 entity name - section tile+passage pair
- Scientific papers의 citation pair
- Common Crawl에서 가져온 title - passage pair
여기서 semi-structured 란 각 q-a pair의 형태로 되어있는 것을 의미하는지, 혹은 위 5개 domain마다 각각의 특별한 형태(예를 들면 stackexchange에서는 code를 가져옴)를 갖는 것을 의미하는지는 잘 모르겠다. 중요한 건 꽤 정제된 데이터를 우선적으로 가져온 점인 것 같다. Stackexchange에서는 모든 answer보다 upvoted answer(정확한 기준은 모르지만)를, Reddit에서는 4096자 이하의 간결하고 신뢰성 있는 comments만을 가져오고 높은 perplexity를 가진 text는 모두 제외시켰다고 한다.
2. Consistency-based filtering
위의 과정을 통해 1.3B개의 데이터를 얻은 다음에는 데이터 품질 향상 및 계산 비용을 고려해 consistency-based data filtering을 적용했다고 한다. 과정은 아래와 같다.
- 먼저 1.3B개의 초기 데이터로 모델을 학습시킨다.
- 각 pair를 백만 개의 random passages와 같이 놓고, 질문 에 대한 모든 passage의 score를 구해 top-k개를 뽑는다.
- top-개의 passages 안에 원래 와 연결되어 있던 가 있으면 해당 pair를 그대로 두고, 그렇지 않으면 해당 pair를 데이터셋에서 제외시킨다. (를 사용했다고 한다.)
-> 이 과정을 톹해 1.3B개의 데이터는 270M개로 줄어든다.
이러한 방법은 모델의 예측이 consistent해야한다는 직관을 반영했는데, 논문에서는 이것이 신경망의 'memorization behavior'를 고려한 것이라고 한다.
memorization behavior란,신경망이 처음에는 clean label을 먼저 기억하고 그 다음 점차 noisy label에 overfit되는 경향을 의마한다고 한다.
- 모델 학습 초기에 clean label이 주는 신호가 더 크다는 것으로 이해된다. clean label과 noisy label이 순서를 갖고 모델에 들어가는 것은 아니기 때문에, 정확히 말하면 clean label 뿐만 아니라 noisy label에서도 우선적으로 'clean signal'을 기준으로 모델이 먼저 어느정도 수렴한 다음 noisy한 signal을 학습하는 형태가 될 것 같다.
Method
E5는 위에 언급한 CCPairs 데이터셋을 통한 contrastive learning을 통해 일차적으로 학습된다. 별개의 언급이 없는 것을 보면 1.3B개의 dataset으로 한 번, 270M개의 dataset으로 한 번 이러한 학습을 진행하는 것 같다.
이후에는 성능을 높이기 위해 NLI, MS-MARCO, NQ 의 3가지 Labeled dataset을 이용해 fine-tuning을 거친다. 다른 Sota dense retriever들과 유사하게, hard negatives과 knowledge distillation을 이용한다고 한다. Loss function은 아래와 같다.
는 teacher model이 되는 cross-encoder 모델, 는 student model이 되는 E5에서의 probabilities를 뜻하며 는 contrastive Loss이다.
Analysis
아래 table 7은 위에서 언급한 data filter의 ablation result인데, 첫 2개 행은 1M개의 데이터만 사용했을 때, 아래 2개 행은 전체 270M개 데이터만 사용했을 때의 결과이다.
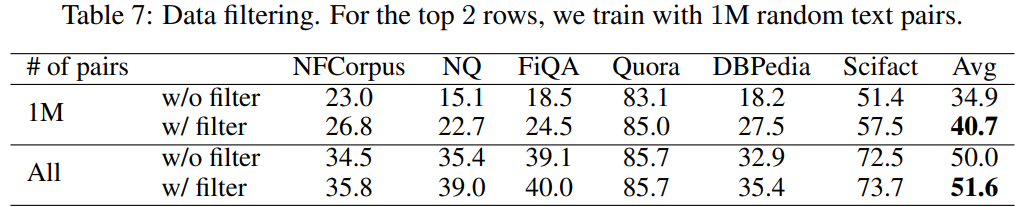
데이터가 적을수록 filtering으로 인한 성능 향상이 뚜렷한데, 직관적으로 생각해보면, data가 적을수록 noisy한 signal에 saturated될 우려가 있으니 이 때 적절한 filtering이 성능을 많이 높이는 것이 이해되기도 한다.
Research Questions
Consistency를 generative model에서 활용하려면?
consistency filtering은 결국 'LLM이 일관된 생각을 갖도록' 하는 방법인데, 최근에 했던 고민과 같은 맥락을 갖는 듯해 글로 적는다. LLM으로 QA task를 진행하면서, LLM으로 생성된 답변이 얼마나 confident할까? 라는 생각을 해봤다. 그래서 prompt로 정답과 관련된 / 혹은 무관한 hint를 주며 likelihood의 평균을 내고 t-test를 해봤는데, LLM likelihood는 well calibrated signal이 아니라는 글을 읽고 다른 기준도 찾아보기로 했다. 마침 오늘 찾은 논문에서 prompt 변화에 따른 출력의 consistency를 다루고 있었는데, 이를 읽어보고 생각을 정리한 다음에 다시 글을 써볼 예정이다.
