Hadoop 다운로드 및 설정
Hadoop 다운로드
VMware station의 firefox에서 Apache Hadoop사이트로 들어가 링크를 복사한다.
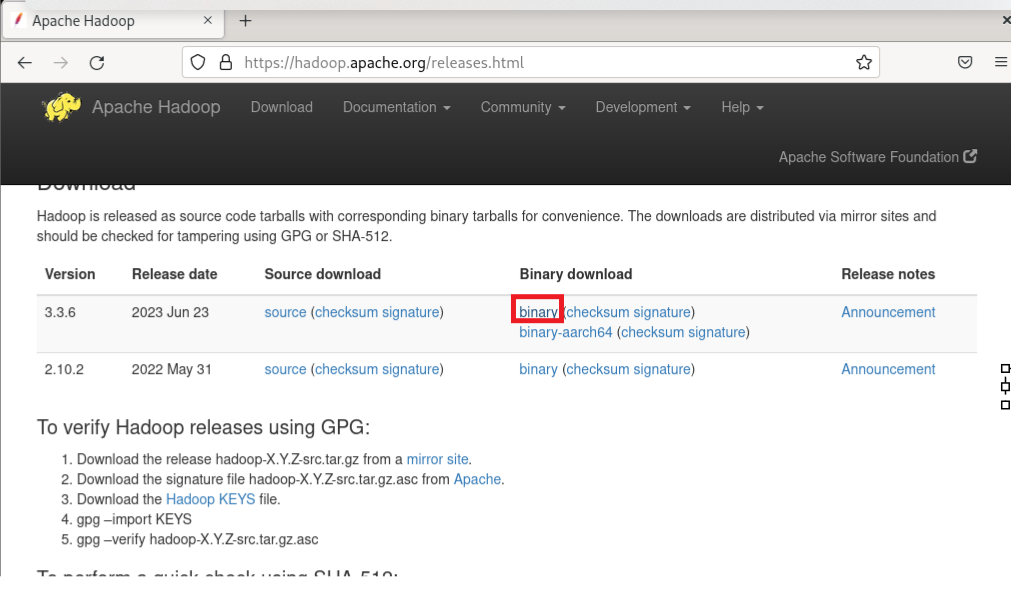
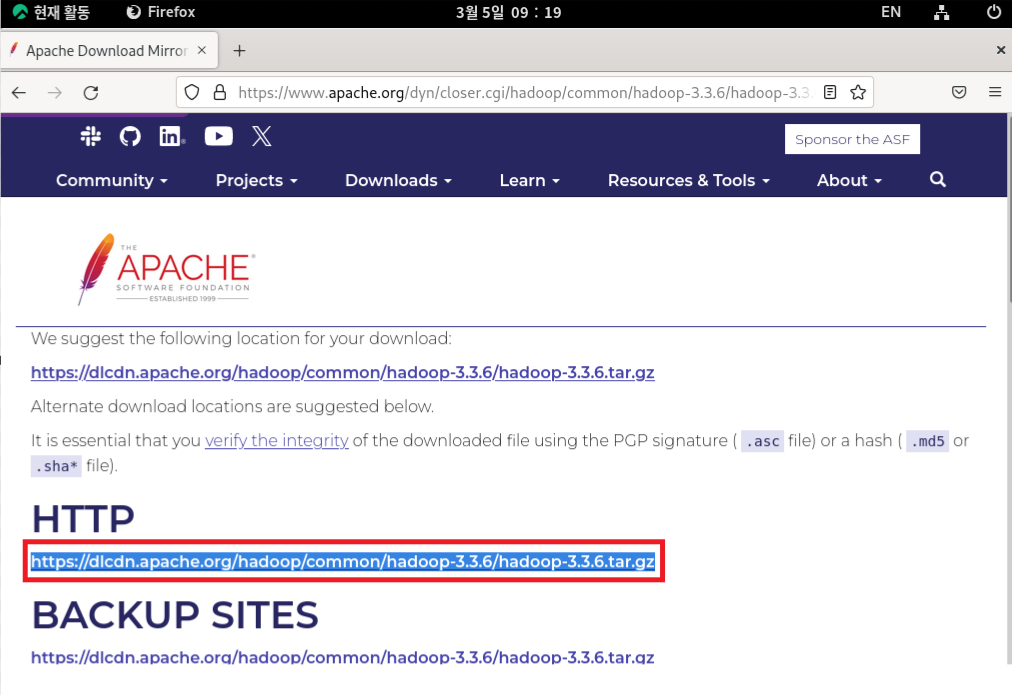
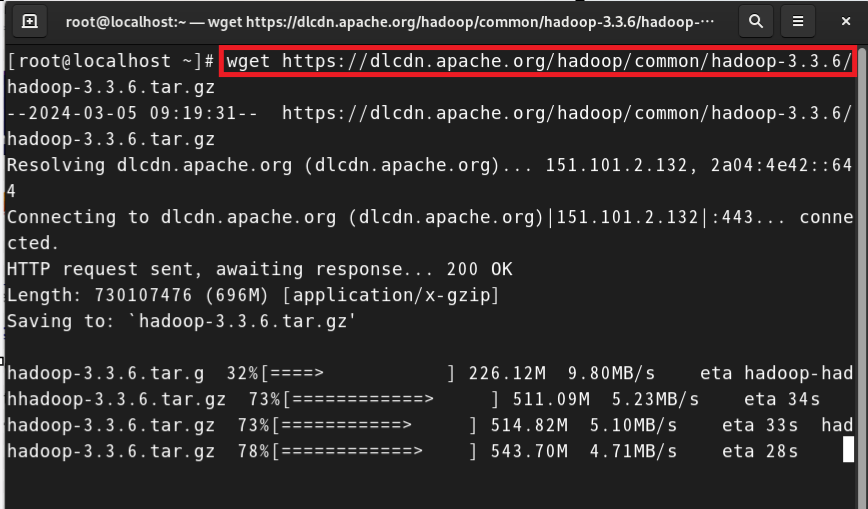
wget 링크를 통해 복사한 링크를 통해 로컬에 하둡을 설치한다.
tar xvfz hadooop-3.3.6.tar.gz를 통해 다운로드 받은 zip파일의 압축을 푼다.
Java 설치 및 환경변수 설정
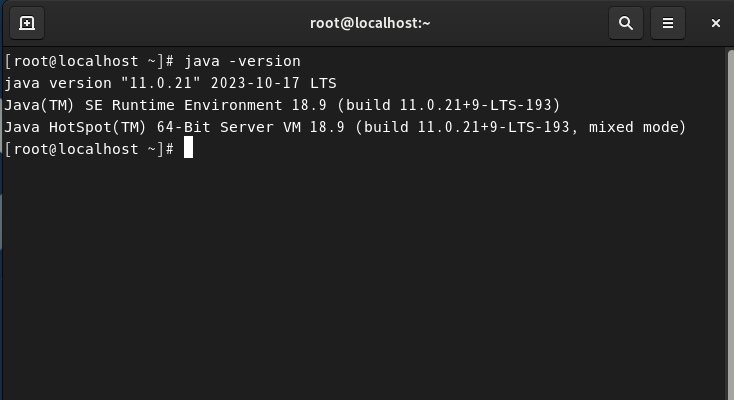
1. java 버전확인
- java -version을 통해 자바 버전을 확인한다
- 버전 확인 시 없다고 뜨면 java를 설치해야한다.
2. java 설치
Hadoop을 위해선 java를 11.0.22 버전을 설치해야한다.11.0.22도 하둡호환이 가능하지만 8버전(1.8.~)을 설치해야 hive와의 호환이 가능하다...- 해당 버전은 암호가 걸려있기에 회원가입 후 파일을 '직접' 다운로드 하여 root 경로에 압축해제 해야한다.
링크 -> java 11 다운로드
- 해당 버전은 암호가 걸려있기에 회원가입 후 파일을 '직접' 다운로드 하여 root 경로에 압축해제 해야한다.
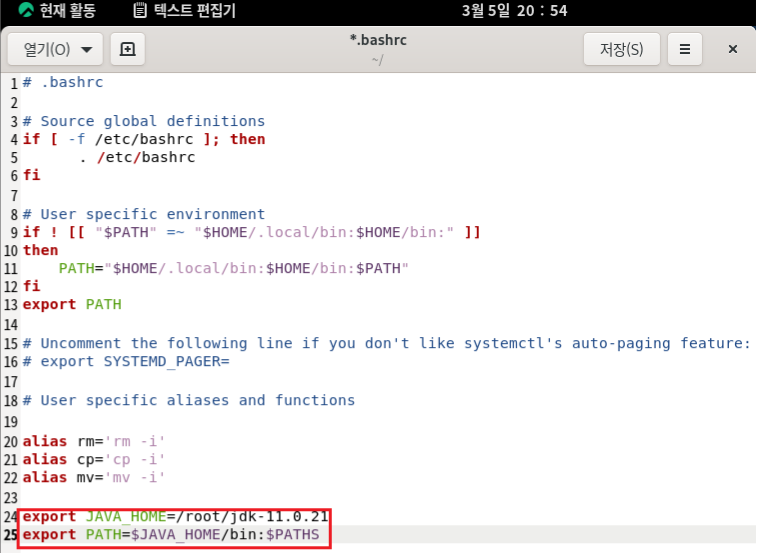
3. 환경 변수 설정
- gedit ~/.bashrc
- 위의 명령어를 통해 에디터로 열고 추가사항을 추가한다
- source ~/.bashrc를 통해 .bashrc 파일을 실행하여 해당 스크립트에 포함된 환경 설정을 현재 셸 세션에 적용한다.
- echo $JAVA_HOME을 통해 java의 환경변수를 확인한다.
- 환경변수가 존재한다면 해당 디렉토리가 출력된다.
Hadoop 환경설정
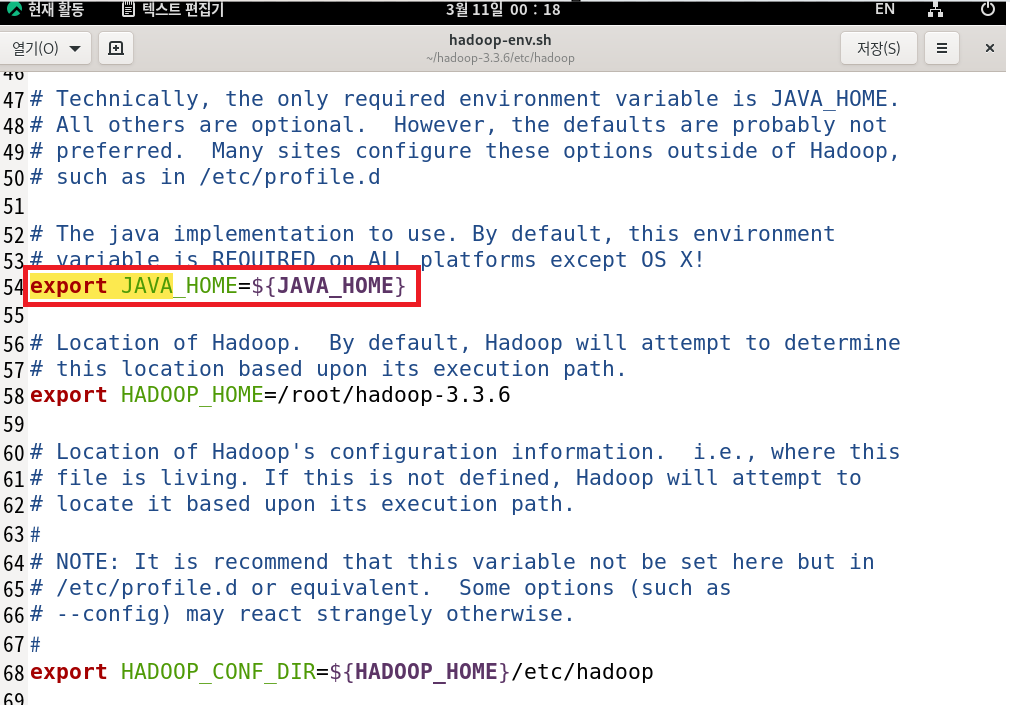
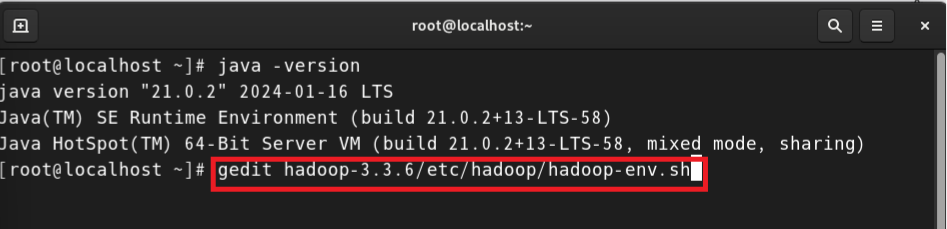
1. 환경변수 설정 및 하둡 환경설정 (java와 동일)
2. 클러스터링 구성(core-site.xml, hadoop-site.xml, mapreduce-site.xml, yarn-site.xml)

- core-site.xml은 Apache Hadoop의 핵심 구성 파일 중 하나로 이 파일은 Hadoop 클러스터의 핵심 설정을 정의하는 데 사용.
- core-site.xml 파일은 Hadoop 클러스터의 모든 노드에서 동일한 설정을 갖고 있어야 함
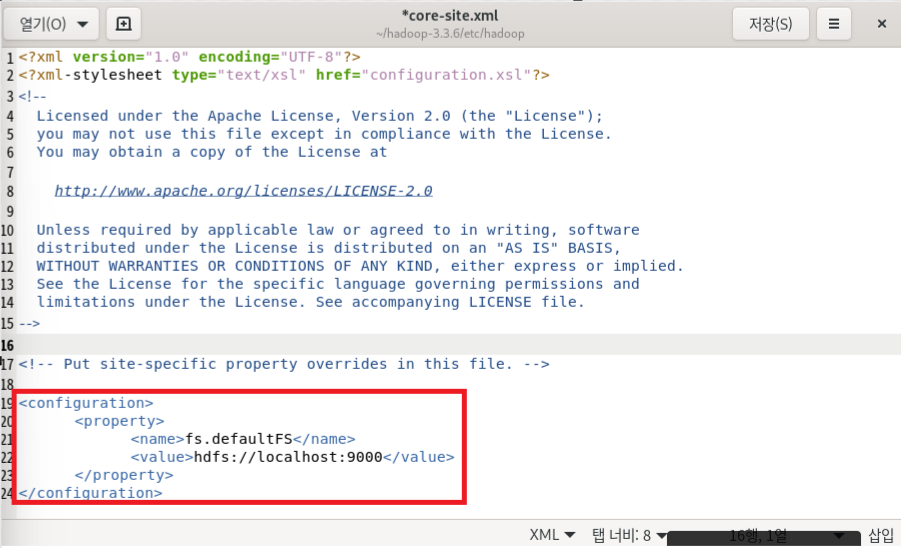
- core-site.xml 파일은 Hadoop 클러스터에서 기본 파일 시스템으로 HDFS를 사용하도록 구성
- fs.defaultFS 속성을 사용하여 HDFS (Hadoop Distributed File System)의 기본 주소를 hdfs://localhost:9000으로 설정

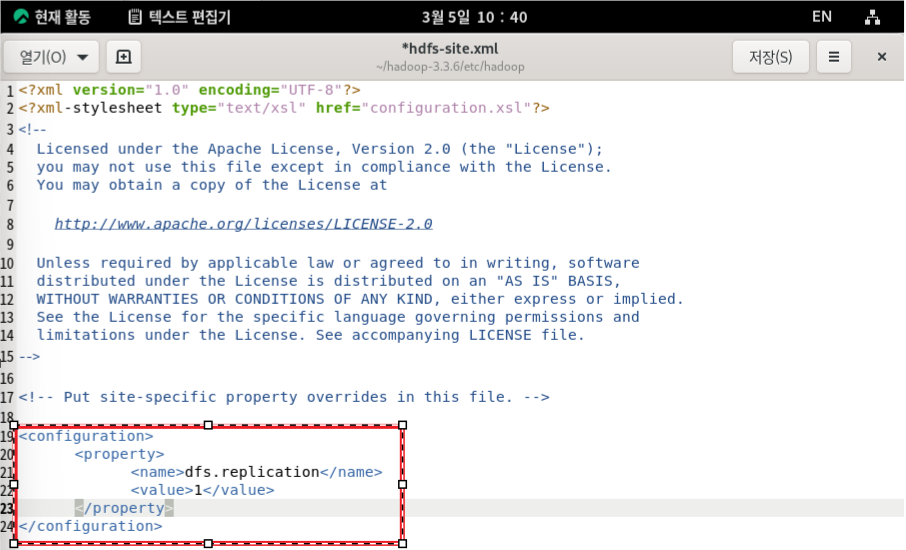
1.hdfs-site.xml 파일은 Hadoop 클러스터에서 HDFS에 대한 구성을 정의
2.dfs.replication 속성의 값을 1로 설정. 이것은 HDFS에서 파일의 복제 수를 1로 설정한다는 것을 의미
3. 접속 공개키 해제

1. ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa

- RSA 키 쌍을 생성하고 암호를 설정하지 않고 개인키 파일을 ~/.ssh/id_rsa에 저장. 이 키는 SSH 연결을 수립할 때 사용
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- ~/.ssh/id_rsa.pub에 저장된 공개키를 ~/.ssh/authorized_keys 파일에 추가
- 해당 공개키가 인증된 사용자로서 해당 시스템에 액세스가 가능
- chmod 0600 ~/.ssh/authorized_keys
- ~/.ssh/authorized_keys 파일의 허가 권한을 설정
- 파일에 대한 읽기 및 쓰기 권한을 소유자에게만 부여
- ssh localhost
- localhost로 SSH 연결을 시도, 사용자의 공개키가 ~/.ssh/authorized_keys에 추가되었으므로 비밀번호 없이 SSH 연결이 수립
1~4 단계를 통해 Hadoop을 접속할 때 비밀번호없이 접속이 가능해짐.
Hadoop 실행
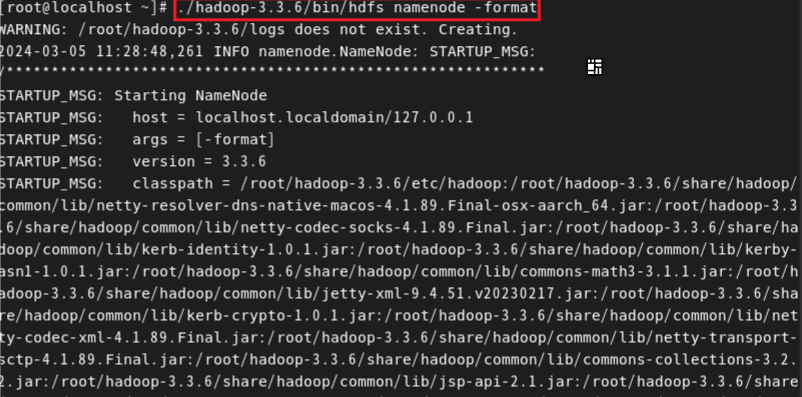
1. Hadoop의 HDFS 네임노드 포맷
- 네임노드를 형식화하면 기존의 모든 데이터와 메타데이터가 삭제되고 클러스터를 초기화
2. Hadoop 분산 파일 시스템(HDFS) 데몬 실행
- Hadoop 분산 파일 시스템(HDFS) 데몬
- Hadoop 클러스터에서 파일 시스템 서비스를 제공하는 소프트웨어 프로세스
- 네임노드(NameNode), 데이터노드(DataNode), 보조 네임노드(Secondary NameNode)로 구성
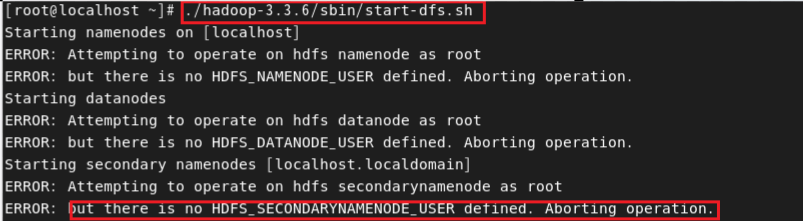
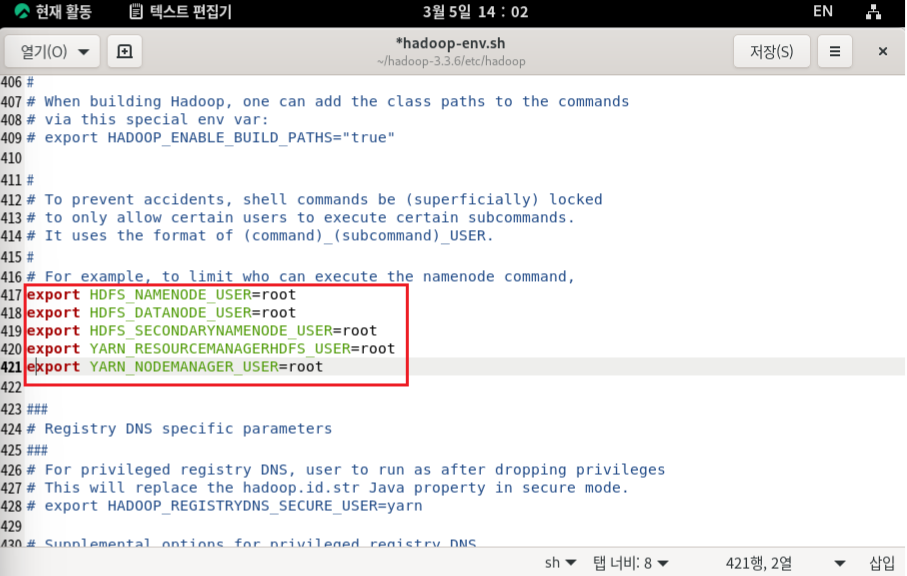
데몬을 실행하였는데 DataNode,Secondary NameNode가 없다는 오류가 발생한다.
따라서 hadoop-env.sh에서 datanode, secondarynamenode, resourcemanager,nodemanager 설정을 추가로 진행한다.
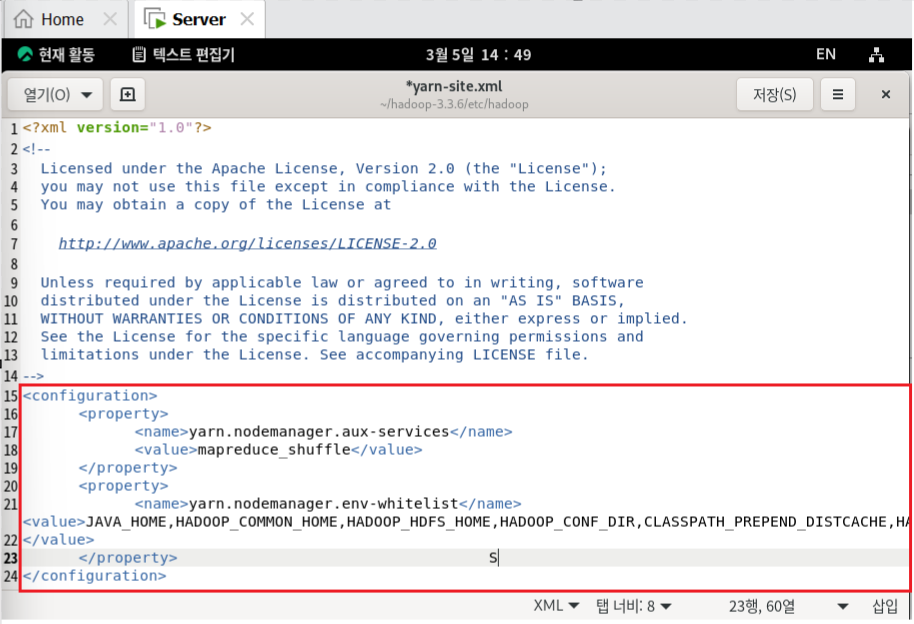
3. Mapreduce, Yarn 설정
- Yarn 설정
이 파일을 사용하여 YARN 관련 구성을 조정하고 Hadoop 클러스터의 리소스 관리 및 작업 스케줄링을 구성할 수 있음

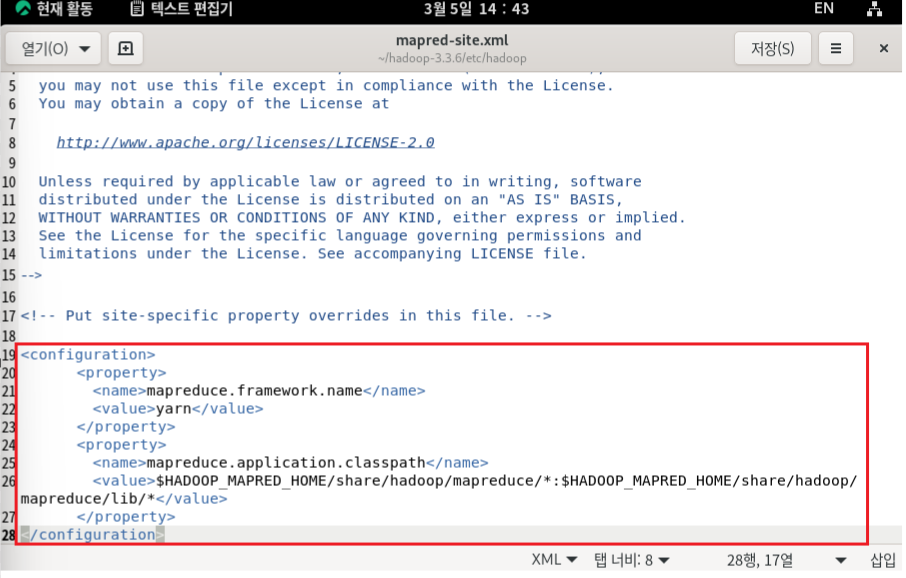
- MapReduce 설정
Hadoop MapReduce의 설정 파일 , 이 파일을 사용하여 MapReduce 작업에 대한 설정을 지정할 수 있음. 예를 들어, 매퍼 및 리듀

서의 수, 잡 트래커 및 작업 트래커의 위치 등을 설정
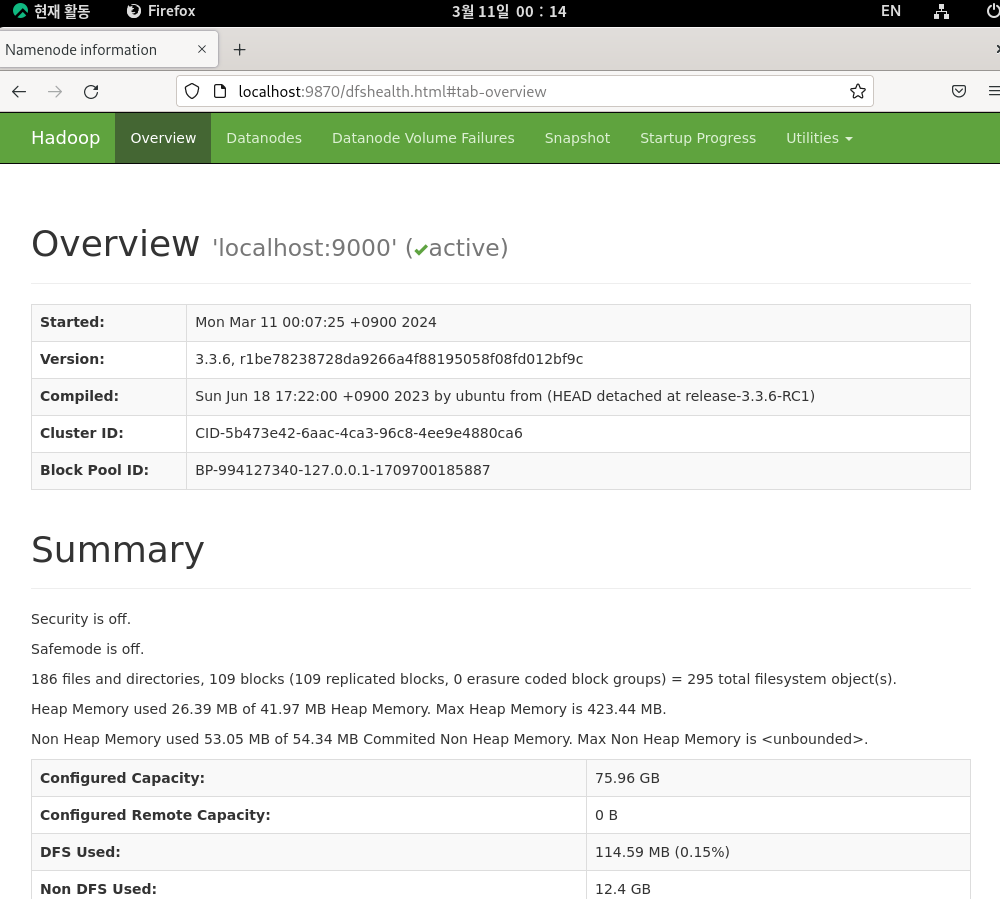
4. Yarn 데몬 실행
- YARN은 Hadoop 클러스터의 리소스 관리 시스템으로, 클러스터 리소스를 효율적으로 관리하고 작업을 스케줄링하는 역할을 담당
- sbin/start-all
- 해당 명령어를 실행하면 HDFS,YARN 클러스터의 구성 요소 즉, 전체 소프트웨어의 데몬실행이 가능하다. (단, core-site.xml, hdfs-site.xml, maprduce-site.xml, yarn-site.xml 설정이 제대로 선행되어야 한다.)
- Hadoop cluster 설정법을 통해 클러스터 설정에 관해 자세히 공부 할 수 있으니 자주 볼 필요가 있다.


JINSU