Mapreduce
Yarn과 Mapreduce
MapReduce:
- MapReduce는 대규모 데이터 세트를 처리하기 위한 분산 병렬 처리 프레임워크
- MapReduce는 맵(Map) 단계와 리듀스(Reduce) 단계로 구성
- MapReduce는 데이터 처리 작업을 여러 노드로 분산하고, 각 노드에서 작업을 병렬로 처리하여 처리 속도를 높입니다.
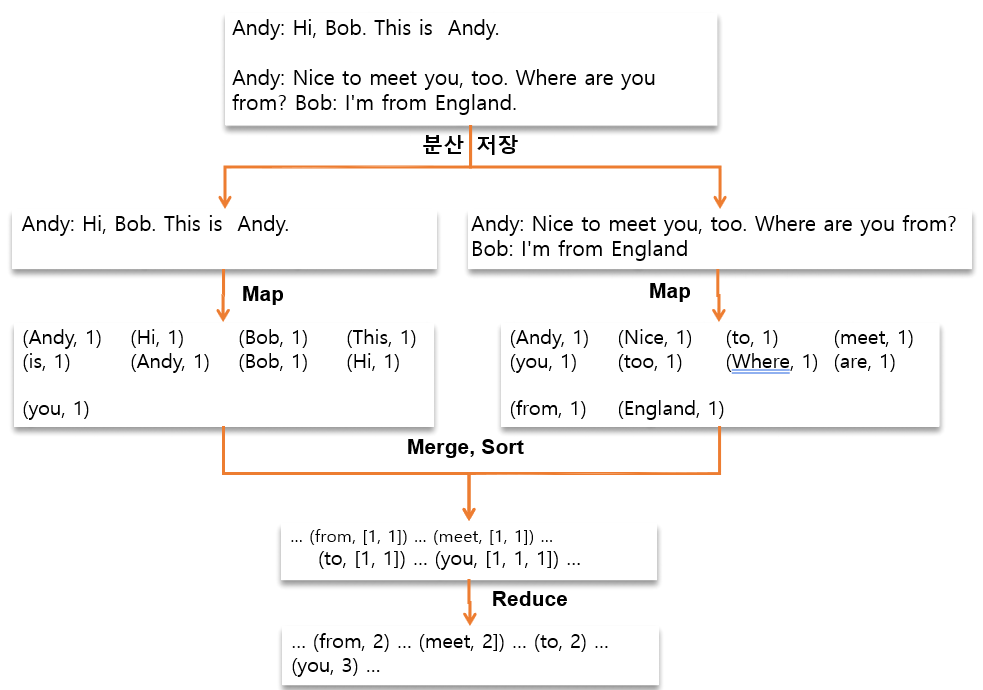
Map
- Map 단계는 입력 데이터를 키-값 쌍으로 변환하고, 이를 중간 데이터로 처리한다.
- 예를들어, wordcount의 경우 특정 텍스트 파일의 단어의 개수를 키-값 형태로 변환한다.
Reduce
-
리듀스 단계는 중간 데이터를 입력으로 받아서 연산을 수행하고 결과를 생성합니다.
-
리듀스의 연산
- 데이터 그룹화(Grouping Data)
- 정렬(sorting)
- 집계(Aggregation)
- 사용자 정의 연산(User-defined Operations)
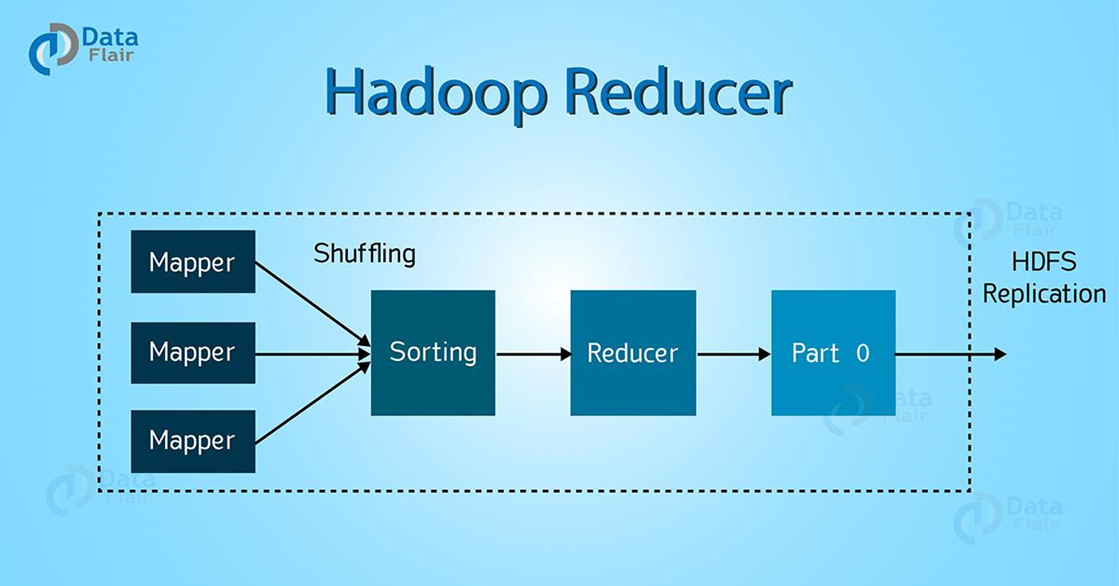 [출처 : https://data-flair.training/blogs/hadoop-reducer/]
[출처 : https://data-flair.training/blogs/hadoop-reducer/]
-
YARN (Yet Another Resource Negotiator):
-
YARN은 Apache Hadoop 2.0부터 도입된 리소스 관리 시스템입니다.
-
YARN은 Hadoop 클러스터 내의 자원 관리와 작업 스케줄링을 담당.
-
이전 버전의 Hadoop에서는 MapReduce만을 위한 자원 관리 시스템이었지만, YARN은 다양한 작업 유형(예: MapReduce, Spark, Tez 등)을 지원
-
YARN은 클러스터 리소스를 각 애플리케이션에 할당하고, 각 애플리케이션의 요구 사항에 따라 동적으로 리소스를 조정
-
이를 통해 Hadoop 클러스터에서 여러 작업을 동시에 실행하고, 자원의 효율성을 높일 수 있다.
-
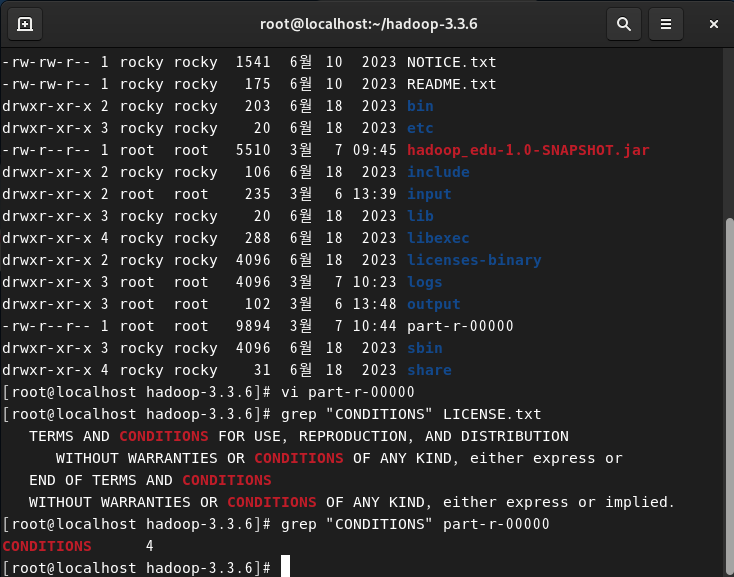
greb을 통해 CONDITIONS 찾기
grep [옵션] [패턴] [파일]
-
greb 정리
- [옵션]: 그렙 명령에 사용할 다양한 옵션을 지정합니다. 일반적으로 -i 옵션을 사용하여 대소문자를 구분하지 않고 검색하거나, -r 옵션을 사용하여 디렉토리의 모든 파일을 검색할 수 있습니다.
- [패턴]: 검색하려는 문자열 또는 정규 표현식을 지정합니다.
- [파일]: 검색을 수행할 파일의 경로를 지정합니다.

JINSU