Apache Hive
Hive란?
하둡에 저장된 데이터를 쉽게 처리할 수 있는 데이터웨어하우스 패키지
SQL과 유사한 Query Language를 지원
SQL레벨의 ETL 처리도구로 활용 가능
Hive metastore
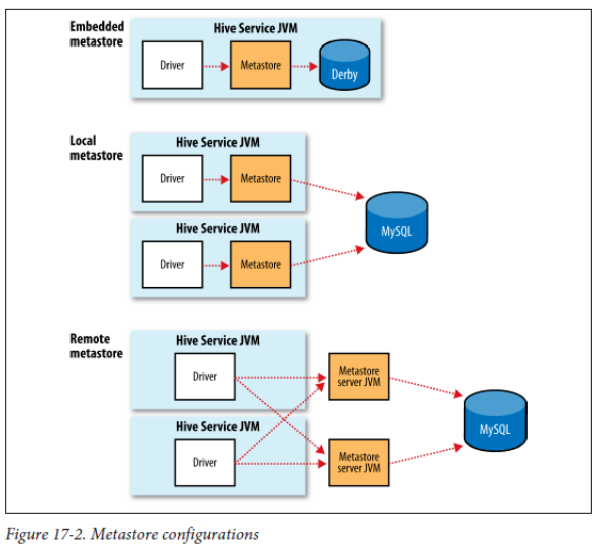
1. Embedded metastore
- 메타스토어 (메타데이터의 저장소)가 로컬 장비(hive가 설치된 경로)에 파일로 생성
- 한번에 하나의 프로세스만 접근 가능
- default로 Apache DerbyDB가 메타스토어의 DB로 사용
2. Local metastore
- 메타데이터(Hive에서 생성된 테이블의 정보, partition 등)가 원격환경(RDMS 즉, mysql,postresql)의 DB에 저장 즉, 외부의 RDMS를 Hive의 메타스토어로 사용
3. Remote metastore
- local metastore과 동일하게 Hive의 메타데이터가 모두 원격의 데이터베이스에 저장
- local metastore의 차이점은 Remote metastore은 메타스토어를 참조 및 서비스하는 서비가 별도로 존재
- 해당 서버를 통해 클라이언트가 db에 직접 쿼리를 날리는 것이 아닌 서버의 중개를 받음
- 이를 통해, 여러개의 노드에 존재하는 hive 객체가 동일한 메타데이터를 공유
- 즉, 분산처리시스템에서 데이터 처리 및 분석 작업을 위해 중앙화된 메타데이터 저장소를 구축
헷갈리면 안되는 부분
클라이언트는 hive 메타스토어에 저장된 메타데이터를 통해 hive에서 형성한 실제 데이터를 '참조'할 수 있으나 '수정 및 변경'은 불가능하다.
hive에서 생성된 데이터(테이블 정보)를 수정하기 위해서는 다양한 방법이 있지만 Apache sqoop을 사용한다면, hive에서 생성된 데이터는 hive가 HDFS위에 존재하기에 HDFS에 저장이 되고 Sqoop export를 통해 '실제 데이터'를 HDFS로 부터 RDMS로 가져올 수 있다.
Hive 다운로드
HADOOP : 하둡 3.3 버전으로 설치
JAVA : 1.8. 버전으로 설치해야만 hive와 충돌이 발생하지 않는다
HIVE : 3.1.3로 설치
1. 하이브 3.1.3 설치
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz 으로 리눅스에 하이브를 설치한다
링크 : https://dlcdn.apache.org/hive/hive-3.1.3/
2. 홈 디렉토리에 파일 압축 풀기
tar xzvf -파일이름.tar.gz
unzip 파일이름.zip
gunzip 파일이름.gzip
3. template 파일을 변경하여 hive-env.sh파일 생성
> mv conf/hive-env.sh.template conf/hive-env.sh4. apache-3.1.3으로 경로 이동뒤 vi conf/hive-env.sh에서 하둡 홈 경로 설정
gedit conf/hive-env.sh
(추가 내용)
HADOOP_HOME=~/hadoop-3.3.6
5. hive-site.xml 생성
hive-site.xml 파일은 Hive의 기본 설정을 변경하고 사용자 정의 설정을 추가하는 데 사용됩니다. 예를 들어, Hadoop 클러스터의 네임노드 및 데이터노드의 호스트 이름, JDBC 연결 정보, 저장소 위치 및 설정 등을 구성
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>6. Hadoop 실행
hadoop을 켜줄때 hadoop-3.3.6경로로가서 sbin/start-all.sh를 해도 되지만 다른 경로에 지금 있다면 $HADOOP_HOME/sbin/start-all.sh 해도 된다. 이를 더 간편히 하기위해 경로 설정을 진행하자.
cd hadoop-3.3.6
sbin/start-all.sh
7. Hive를 실행하기 위해 Hadoop 분산 파일 시스템(HDFS)에서 필요한 디렉토리를 생성하고 권한을 설정

- hadoop -fs -mkdir /tmp/hive: Hive가 실행되는 동안에 사용되는 임시 디렉토리를 생성. 일반적으로 Hive 작업 중에 임시 파일이 이 디렉토리에 저장
- hadoop -fs -mkdir /user/hive/warehouse/bin: Hive 데이터 웨어하우스 디렉토리를 생성. 이 디렉토리는 Hive 테이블의 데이터가 저장되는 위치
- 권한 설정
- hadoop fs -chmod g+w /tmp
- hadoop fs -chmod g+w /user/hive/warehouse/bi
- hadoop fs -chmod 777 /tmp/hive
8. 이슈 해결을 해결하기 위한 작업
# guava 라이브러리 삭제 및 복사 실행
cp ~/hadoop-3.3.6/share/hadoop/hdfs/lib/guava-27.0-jre.jar ~/apache-hive-3.1.3/lib/
9. Derby 메타스토어 초기화
# 하이브 홈 디렉토리
~/apache-hive-3.1.3/bin/schematool -initSchema -dbType derby
10. hive 경로 설정
-
hive 환경 변수 추가
- gedit ~/.bashrc
#hive 추가
export HIVE_HOME=/root/apache-hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
- gedit ~/.bashrc
-
수정된 bashrc 재실행
- source ~/.bashrc
11. hive 실행 및 트러블 슈팅
- hive 명령어를 통해 hive를 실행한다.
- 기존에 설치했던 java 11.0 버전과 충돌이 발생
/usr/bin/which: no hbase in (/root/hadoop-3.3.6/bin:/root/jdk-11.0.22/bin:/root/hadoop-3.3.6/bin:/root/jdk-11.0.22/bin:/root/hadoop-3.3.6/bin:/root/jdk-11.0.22/bin:/root/.local/bin:/root/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/root/apache-hive-3.1.3/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/root/apache-hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/root/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 62ea331f-fe6f-4b47-873d-2162a5285151
Exception in thread "main" java.lang.ClassCastException: class jdk.internal.loader.ClassLoaders$AppClassLoader cannot be cast to class java.net.URLClassLoader (jdk.internal.loader.ClassLoaders$AppClassLoader and java.net.URLClassLoader are in module java.base of loader 'bootstrap')
at org.apache.hadoop.hive.ql.session.SessionState.<init>(SessionState.java:413)- java 1.0.8 버전의 재설치 필요
- linux pipe를 사용
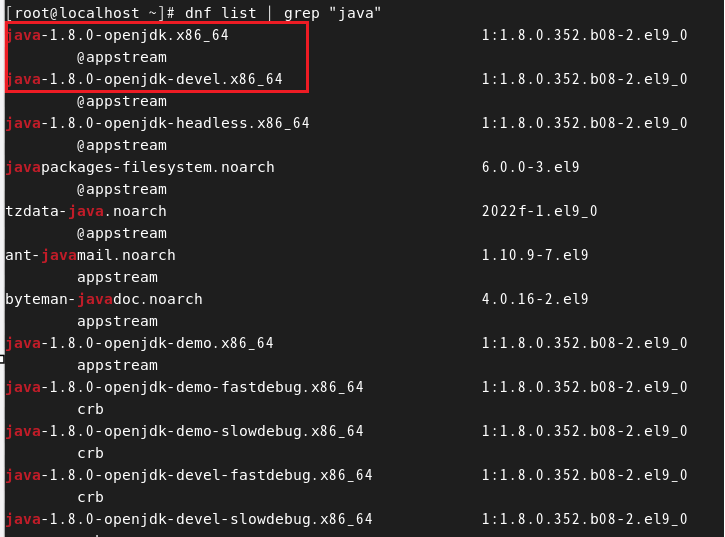
- dnf list | grep "java"
- dnf의 설치 가능 파일 중 java가 들어가 있는 부분 찾기
- 필요한 rpm 파일 설치
- 환경 변수 재설정
# root(/)부터 파일명에 해당하는 파일 경로 전부 찾기
find / -name 파일명
- linux pipe를 사용

실습 > 공공데이터를 맵리듀스를 통해 적재한 후 hive를 통해 쿼리 진행
실습 데이터 다운로드
1. 공공데이터 포털에서 csv파일 다운로드 하기
2. 해당 csv 파일의 수정부분 확인하기
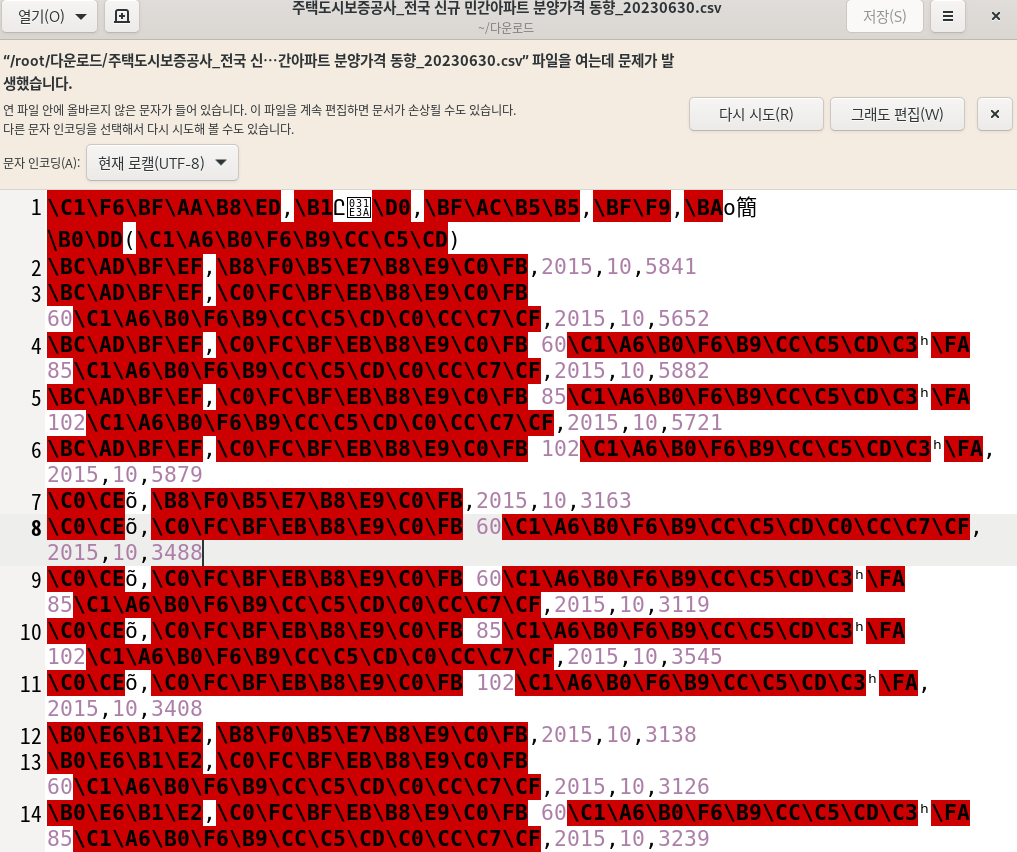
파일을 살펴보면 파일의 인코딩이 잘못된 것을 알 수 있다. 해당 파일의 인코딩 방식을 UTF-8로 바꿔주어야 한다.
iconv -f [현재 인코딩] -t UTF-8 input.csv -o /path/to/output.csv
- 순서>
- file-bi 파일명 -> 현재 파일의 인코딩 형식 출력
- 위에서 언급한 인코딩 변경 명령어를 통해 인코딩 바꾸기
- 원래 우리가 살펴볼 파일의 인코딩 형식은 iso-8859-1인데 cp949로 해주어야 변경이 된다.
- locale 명령어를 치면 현재 리눅스에서 한글 인코딩은 UTF-8을 사용함을 알 수 있음
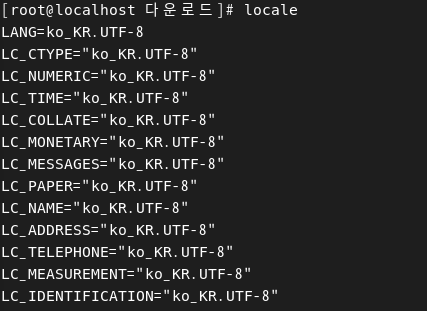
- locale 명령어를 치면 현재 리눅스에서 한글 인코딩은 UTF-8을 사용함을 알 수 있음
- 최종적으로 인코딩 형식 UTF-8로 바꾸기
iconv -f cp949 -t utf-8 apartment.csv -o apartment_new_1.csv
3. Hadoop 환경내 경로 생성 및 csv파일 put하기
hadoop fs -mkdir -r /user/root/hadoop_edu/apartment
hadoop fs -put ~/다운로드/apartment.csv /user/root/hadoop_edu/apartment
4. Hadoop & yarn 데몬 실행
sbin/start-all.sh
5. Hive 실행 및 데이터베이스, 테이블 형성
cd ~/apache-hive
create database if not exists hadoop_edu;
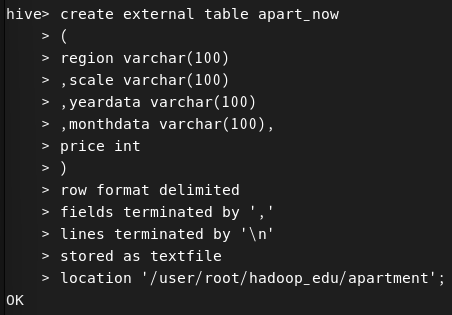
6. 쿼리문 진행
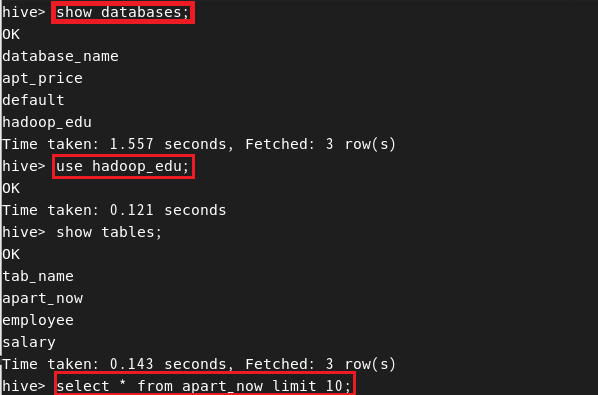
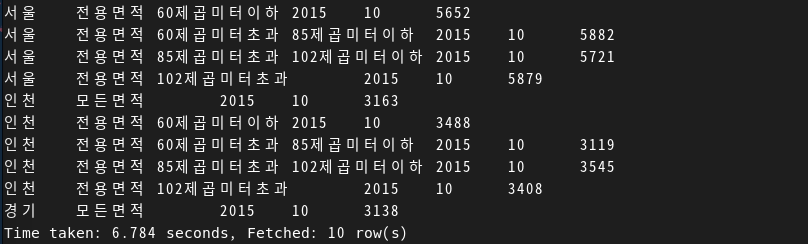
Partition에 대하여
https://spidyweb.tistory.com/235 (설명이 상당히 잘 되어 있음)
오늘 알게된 내용
1. 환경변수에 대하여

 예를들어, hadoop-3.3.6을 설치하였고 hadoop에 대한 명령어를 사용하기 위해서는 hadoop-3.3.6/bin/에 존재하는 hadoop을 통해 명령어를 사용해야한다. 즉, hadoop 명령어를 사용하기위해 항상 hadoop-3.3.6/bin/을 사용해야한다. 이를 PATH에 경로를 설정해준다면 hadoop-3.3.6/bin/ 경로로 이동없이 hadoop명령어를 사용할 수 있다.
예를들어, hadoop-3.3.6을 설치하였고 hadoop에 대한 명령어를 사용하기 위해서는 hadoop-3.3.6/bin/에 존재하는 hadoop을 통해 명령어를 사용해야한다. 즉, hadoop 명령어를 사용하기위해 항상 hadoop-3.3.6/bin/을 사용해야한다. 이를 PATH에 경로를 설정해준다면 hadoop-3.3.6/bin/ 경로로 이동없이 hadoop명령어를 사용할 수 있다.
2. linux pipe
command1 | command2
- command1의 출력을 command2의 입력으로 넣어주는 기능
- ex. dnf list | grep "java"
- dnf list의 출력인 dnf를 통해 설치할 수 있는 목록을 grep "java"의 입력으로 넣어주면 해당 목록중 "java"가 포함되어 있는 목록만 볼 수 있다.
3. linux redirection
 [출처 : 출처]
[출처 : 출처]
- 리디렉션을 사용하면 각 스트림의 방향을 지정할 수 있음
- 스트림이란?
- 데이터의 연속적인 흐름을 나타내는 추상화
- 입력 스트림 : 데이터를 읽는데 사용, 파일이나 네트워크 연결로부터 데이터를 읽어와서 프로그램으로 전달
- 출력 스트림 : 데이터를 쓰는 데 사용, 프로그램이 생성한 파일이나 네트워크 연결등으로 전송하기 위해 사용
- 데이터의 연속적인 흐름을 나타내는 추상화
실습>
1. 명령어 > 파일
- 임의의 파일 2개를 root 경로에 형성
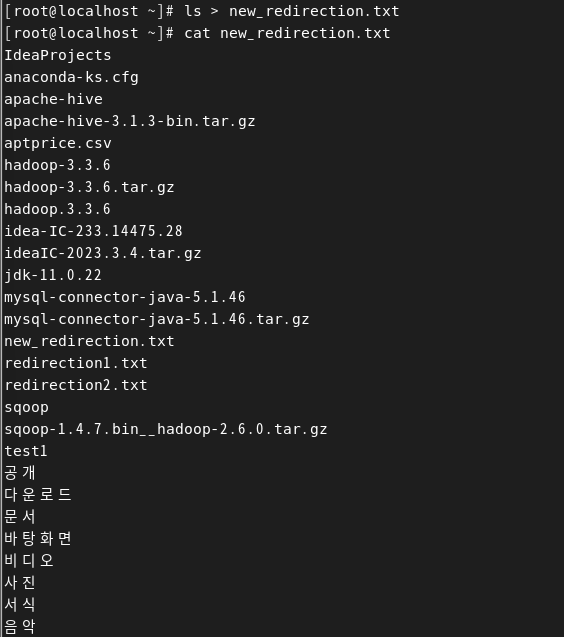
- ls > new_redirection.txt를 통해 ls의 출력스트림(=현재 경로 목록)을 redirection1.txt 파일의 입력 스트림으로 넣기 (즉, 파일에 덮어쓰기)
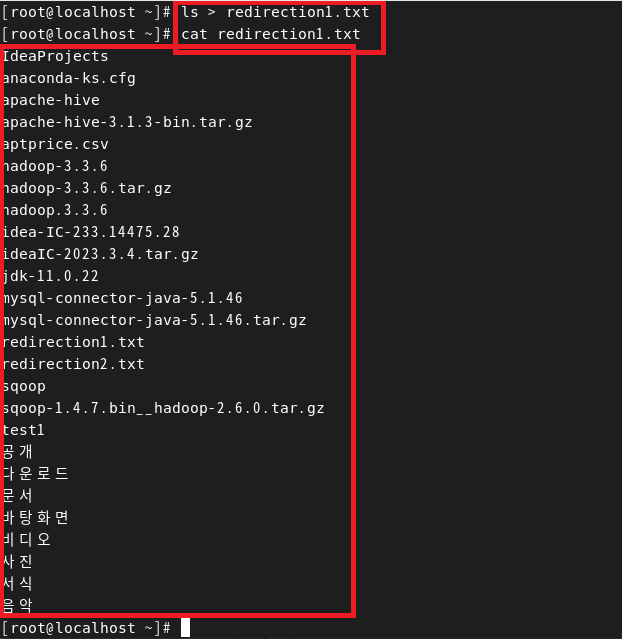
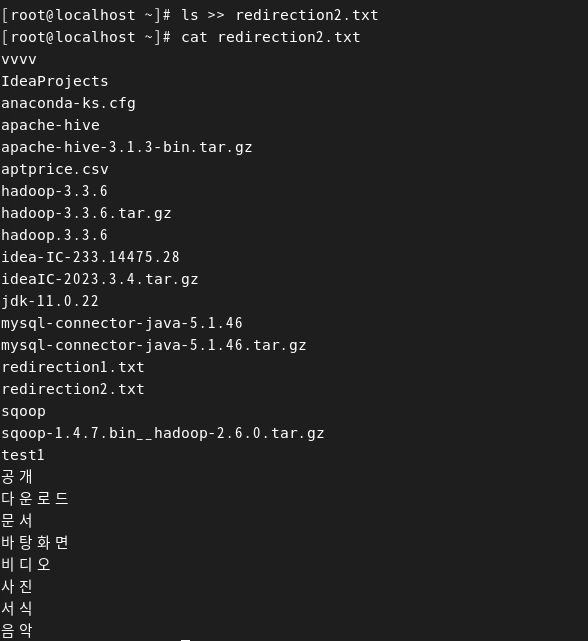
2. 명령어 >> 파일
- 표준 출력 결과를 기존 파일에 추가하기
3. 명령어 < 파일
- <를 통해 파일의 내용을 명령어의 입력스트림으로 사용한다.
- 즉, 파일의 출력을 명령어의 입력으로 넣어줌
- 앞서 만든 redirection1.txt 파일의 마지막 부분 2개 행을 출력

4. Scp

scp [윈도우파일 경로][리눅스유저명]@[호스트명 or IP][파일을 넣을 리눅스 경로]

