2024.02.26
오늘 학습한 내용 : 데이터 크롤링 기본
크롤링이란
- 인터넷 상에서 웹 페이지를 자동으로 탐색하고 필요한 정보를 수집하는 프로세스
- 웹 스크래핑의 한 형태로, 웹 페이지의 HTML 코드를 분석하여 원하는 데이터를 추출
HTML에서 데이터 불러오기
모듈 불러오기 및 파싱
# 라이브러리 호출
from bs4 import BeautifulSoup # BeautifulSoup : html 크롤링 라이브러리
import requests # HTTP 호출 라이브러리
html = '''
<h1 id="title">한빛출판네트워크</h1><div class="top">
<ul class="menu">
<li><a href=http://www.hanbit.co.kr/member/login.html class="login"> 로그인 </a></li>
</ul>
<ul class="brand">
<li><a href="http://www.hanbit.co.kr/media/">한빛미디어</a><li>
<li><a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a></li>
</ul>
</div>
'''
#BeautifulSoup를 이용한 HTML 소스 파싱
soup = BeautifulSoup(html,'lxml')
print(soup.prettyify())result>
<h1 id="title">
한빛출판네트워크
</h1>
<div class="top">
<ul class="menu">
<li>
<a class="login" href="http://www.hanbit.co.kr/member/login.html">
로그인
</a>
</li>
</ul>
<ul class="brand">
<li>
<a href="http://www.hanbit.co.kr/media/">
한빛미디어
</a>
<li>
<li>
<a href="http://www.hanbit.co.kr/academy/">
한빛아카데미
</a>
</li>
</li>
</li>
</ul>
</div>- requests : 웹페이지의 HTML 소스를 가져오는 모듈
- BeautifulSoup : HTML 소스를 파싱하고 HTML 태그나 속성을 통해 원하는 데이터 추출하는 라이브러리
- lxml은 html 소스를 처리하기 위한 파서
- prettify()는 파싱 결과를 보기 편하게 HTML구조의 형태로 확인
크롤링 허용 여부 확인하기
- 크롤링할 주소/robots.txt를 사용하여 판별 가능하다

단일 태그 가져오기
- 파싱 대상 soup.태그를 통해 단일 태그를 가져올 수 있다.
# 단일 태그 html가져오기
# div 태그 가져오기
tag_div = soup.div
print(tag_div)
result>
<div class="top">
<ul class="menu">
<li><a class="login" href="http://www.hanbit.co.kr/member/login.html"> 로그인 </a> </li>
</ul>
<ul class="brand">
<li><a href="http://www.hanbit.co.kr/media/">한빛미디어</a></li>
<li></li>
<li><a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a></li>
</ul>
</div>
tag_a = soup.a
print(soup.a)
result>
<a class="login" href="http://www.hanbit.co.kr/member/login.html"> 로그인 </a>
- 2번째 예시에서 3개의'a'태그 html중 첫번째만 출력 된 것을 알 수 있다. 즉, 단일태그는 가장 먼저 언급
모든 태그 가져오기
- find_all , select
tag_a_all = soup.find_all('a')
print(tag_a_all)
result>
[<a class="login" href="http://www.hanbit.co.kr/member/login.html"> 로그인 </a>, <a href="http://www.hanbit.co.kr/media/">한빛미디어</a>, <a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a>]
tag_li_all_1 = soup.select('li')
print(tag_li_all_1)
result>
[<li><a class="login" href="http://www.hanbit.co.kr/member/login.html"> 로그인 </a></li>, <li><a href="http://www.hanbit.co.kr/media/">한빛미디어</a></li>, <li>
</li>, <li><a href="http://www.hanbit.co.kr/academy/">한빛아카데미</a></li>]
- 중요한 점은 find_all, select 모두 '리스트'로 반환한다는 것이기에 특정 html을 추출하기 위해서는 인덱싱이 필요하다
속성 정보를 이용하여 파싱하기
- attrs를 사용하면 특정태그의 속성이 '딕셔너리'형태로 반환된다.
- ex.
#1.
tag_a.attrs
result>
{'href': 'http://www.hanbit.co.kr/member/login.html', 'class': ['login']}
#2.
print(tag_a.attrs['href'])
result>
http://www.hanbit.co.kr/member/login.html
웹 사이트에서 데이터 불러오기
기본패턴
1. 모듈 불러오기
# 라이브러리 호출
from bs4 import BeautifulSoup # BeautifulSoup : html 크롤링 라이브러리
import requests # HTTP 호출 라이브러리2. 웹페이지 가져오기
# 크롤링 사이트 불러오기 및 parsing 설정
res = requests.get('https://davelee-fun.github.io/blog/crawl_html_css.html') # requests.get()메소드를 통해 크롤링 HTTP 불러오기
res.content # .content를 통해 해당 웹브라우저의 HTML파일 즉, 페이지의 소스 가져오기 3. 웹페이지 parsing
soup = BeautifulSoup(res.content,'html.parser') #BeufifulSoup를 사용하여 크롤링 대상과 파싱도구 설정 (파싱대상,파싱도구)
soup # 분석결과 - 1~3번 과정은 default로 진행되는 과정이고 추후 select,find_all등을 통해 필요한 부분을 크롤링을 진행한다.
실습1 > 할리스커피 사이트에서 매장정보 갖고와서 표로 만들기
# 실습 . 할리스커피에서 매장정보 가져오기
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store='
res = requests.get(url)
soup = BeautifulSoup(res.content,'html.parser')
items = soup.select('div.tableType01 tbody tr') # 이 경우는 div.tableType01 이라는 태그의 하위태그인 tbody가 바로 올수있다.
item2 = soup.select('div.tableType01 > table.tb_store> tbody > tr') # >를 사용한 경우는 반드시 상위태그와 하위태그의 연속성이 중요하다. 즉, div.tableType01과 tbody사이에 위치한 table.tb_store을 생략할 수 없다.
result = []
for item in items:
item_1 = item.select('td')
store=[]
for i in item_1:
store.append(i.get_text())
result.append(store)
# print(result)
df = pd.DataFrame(result,columns=['지역', '매장명', '현황', '주소', '매장 서비스', '전화번호'])
df.to_csv("할리스커피매장정보.csv",encoding='ms949')
df
-
key point>
- select의 방식
items = soup.select('div.tableType01 tbody tr') # 이 경우는 div.tableType01 이라는 태그의 하위태그인 tbody가 바로 올수있다. item2 = soup.select('div.tableType01 > table.tb_store> tbody > tr') # >를 사용한 경우는 반드시 상위태그와 하위태그의 연속성이 중요하다. 즉, div.tableType01과 tbody사이에 위치한 table.tb_store을 생략할 수 없다.-
parsing후 데이터 처리 부분
- select, find_all 등의 크롤링부분은 반드시 리스트 반환임을 잊으면 안된다.
- 이 부분은 복잡할수록 print 출력문으로 디버깅을 해주는 것이 좋다
result = [] # 최종 값을 저장하기 위한 리스트 for item in items: item_1 = item.select('td') # td태그 있는 부분만 items에서 다시 추출하여 리스트화 -> 각 td태그에 정보가 담겨있기 때문 store=[] for i in item_1: store.append(i.get_text()) # 리스트로 만드는 이유는 이중 리스트로 만들어서 dataframe을 사용하기 위함 result.append(store) # print(result)
실습2 > 실습1의 예제에서 매장 서비스 부분이 나오도록 하고, 나머지 페이지에 명시된 매장도 불러오기
import requests
import pandas as pd
from bs4 import BeautifulSoup
url = 'https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store='
res = requests.get(url)
soup = BeautifulSoup(res.content,'html.parser')
# print(soup.prettify())
items = soup.select('div.tableType01 tbody tr')
result = [] # 최종 값을 저장하기 위한 리스트
for item in items:
item_1 = item.select('td') # td태그 있는 부분만 items에서 다시 추출하여 리스트화 -> 각 td태그에 정보가 담겨있기 때문
#print(item_1)
store=[]
for idx,content in enumerate(item_1): # enumerate()를 통해 해당 리스트의 인덱스와 내용을 동시에 갖고온다.
if idx == 4:
service_info = []
for i in content.select('img'):
service_info.append(i.attrs['alt'])
store.append(','.join(service_info))
else:
store.append(content.get_text()) # 리스트로 만드는 이유는 이중 리스트로 만들어서 dataframe을 사용하기 위함
result.append(store)
df = pd.DataFrame(result,columns=['지역', '매장명', '현황', '주소', '매장 서비스', '전화번호'])
df.to_csv("할리스커피매장정보.csv",encoding='ms949')
dfResult>

- key point>
result = [] # 최종 값을 저장하기 위한 리스트
for item in items:
item_1 = item.select('td') # td태그 있는 부분만 items에서 다시 추출하여 리스트화 -> 각 td태그에 정보가 담겨있기 때문
#print(item_1)
store=[]
for idx,content in enumerate(item_1): # enumerate()를 통해 해당 리스트의 인덱스와 내용을 동시에 갖고온다.
if idx == 4:
service_info = []
for i in content.select('img'):
service_info.append(i.attrs['alt'])
store.append(','.join(service_info))
else:
store.append(content.get_text()) # 리스트로 만드는 이유는 이중 리스트로 만들어서 dataframe을 사용하기 위함
result.append(store)- enumerate()를 통해 인덱스와 리스트(정확히는 ResultSet 타입)의 원소를 동시에 for문을 통해 갖고와서 '매장 서비스' 부분을 특정짓고 attrs을 통해 속성을 통한 파싱이 가능했다는 점이 중요하다.
- 알아두면 좋은 정보
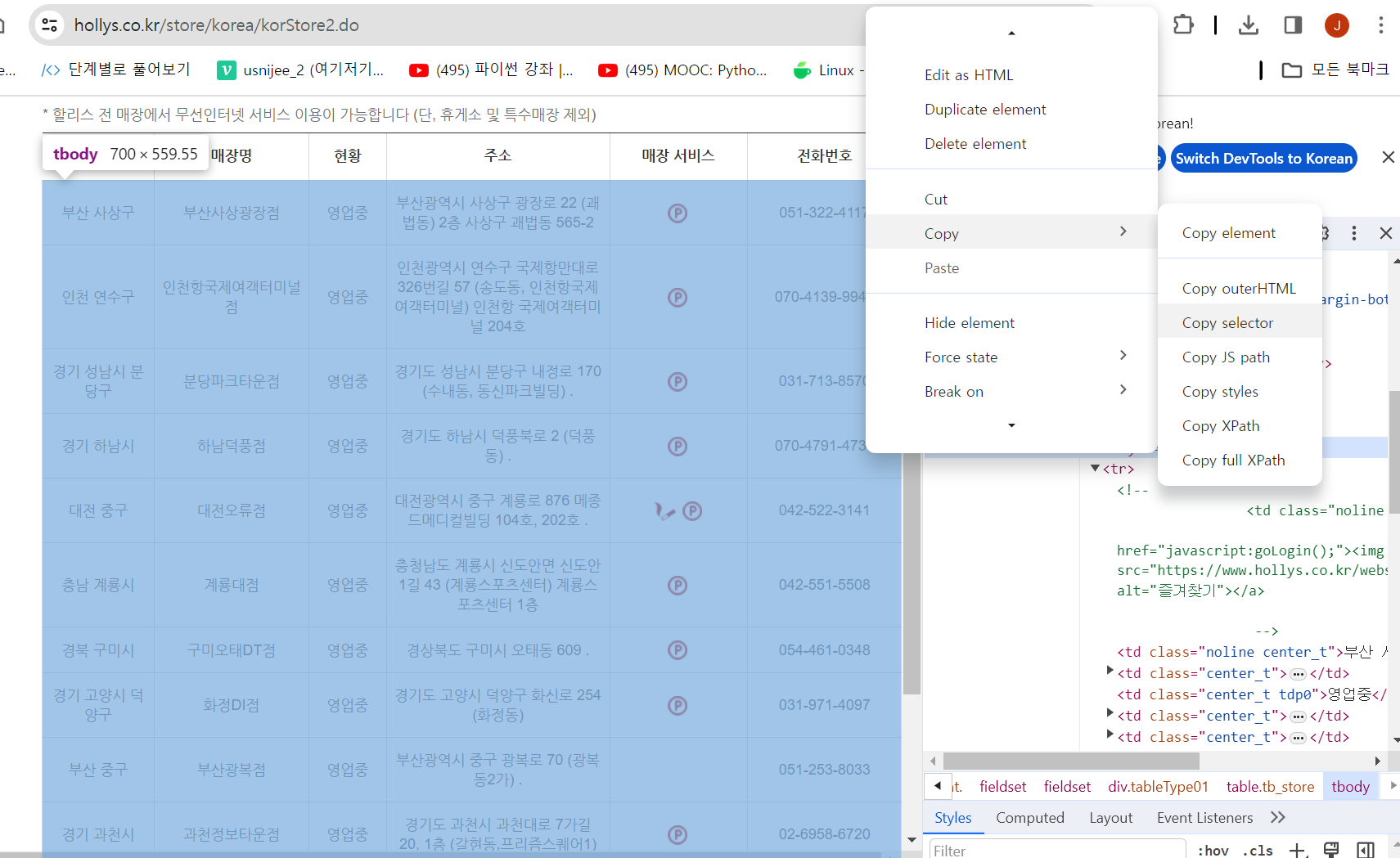
그림에 나와 있는 과정을 진행하면 웹 페이지에서 크롤링하고 싶은 대상을 복사하여 select 또는 find를 통해 크롤링 할 수 있다.
이미지 데이터 크롤링하고 저장하기

JINSU