
> 이 글은 스탠퍼드대학교 Andrew Ng 교수님의 강의를 수강한 것을 토대로 작성한 글입니다
📌 Cost Function
비용 함수
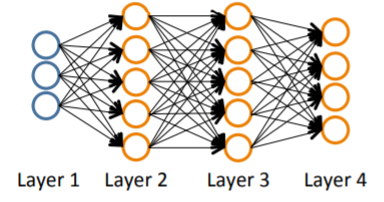
-
Binary classification :
y의 output unit = 1개 ( 0 또는 1 ) -
Multi-class classification :
output units = k개 ( k >= 2 )
-> y = k차원의 행렬이 됨
( 단 하나의 행만 1의 값, 나머지 행들은 모두 0의 값)
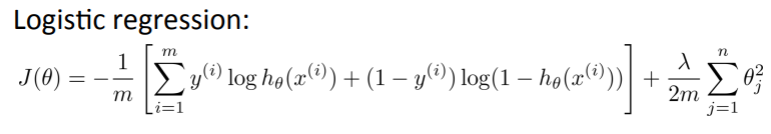
- Neural Network(이하 NN)의 Cost function = Logistic function의 Cost function를 일반화시킨 함수
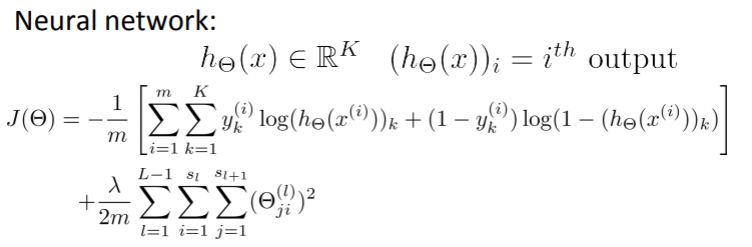
📌 BackPropagation Algorithm
역전파 알고리즘
-
Cost Function을 최소화시키는 알고리즘
-
Forward propagation의 과정
- input layer에서 시작하여 output node의 값을 구함
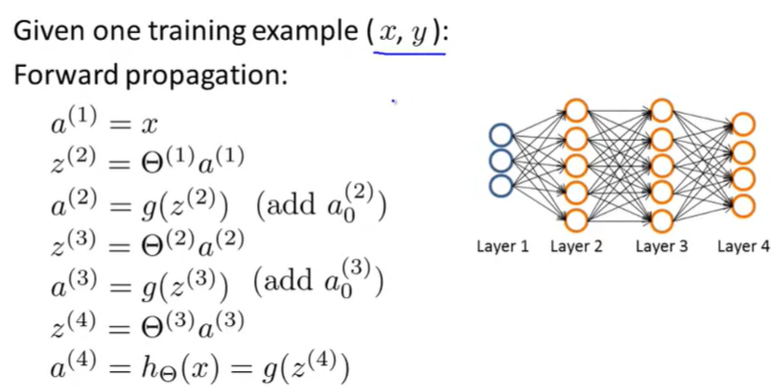
- input layer에서 시작하여 output node의 값을 구함
-
Back propagation의 과정
-
output layer에서 시작하여 output node의 error를 통해 이전 layer node들의 error를 구함
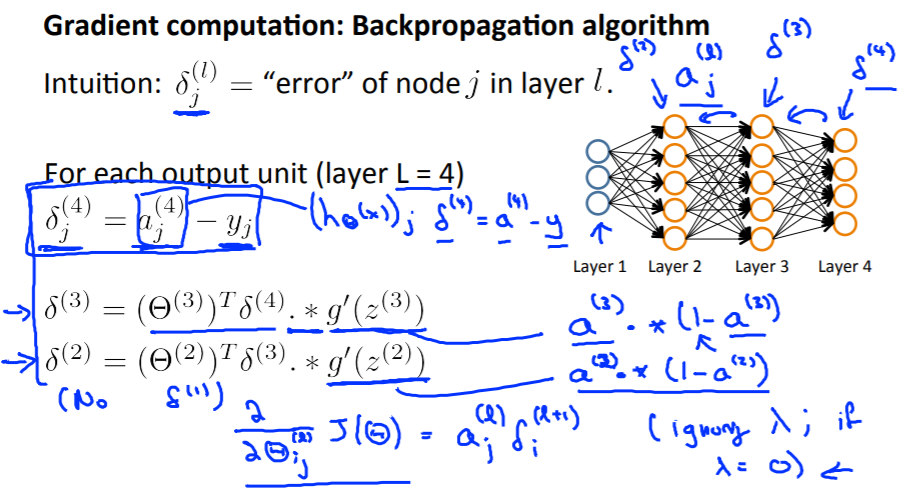
-
Training set이 m개일 때 BP 진행 과정

-
📌 Backpropagation Instuition
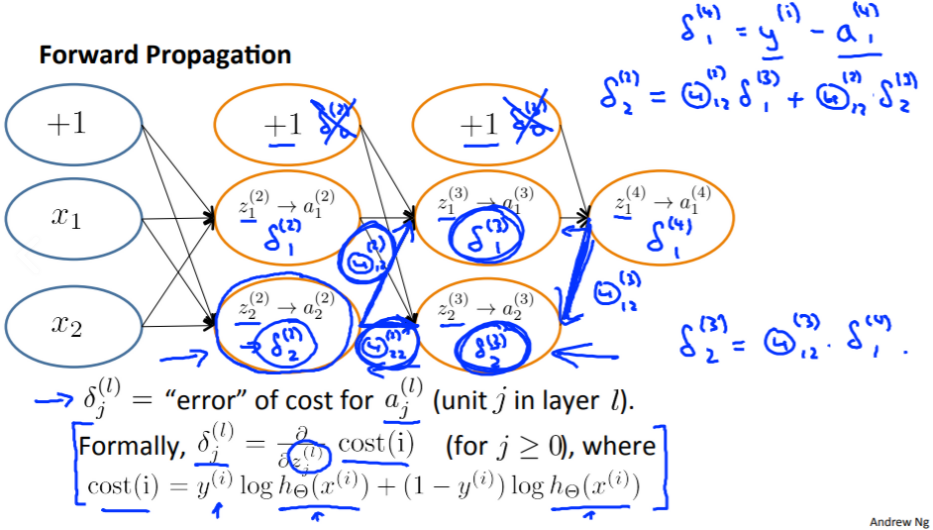
델타값 = l*j개의 unit의 cost function
직관적으로 설명하면 ,
각 노드의 델타값 = cost function에 미치는 gradient
그렇기 때문에 델타값을 파악하면 Θ를 적절하게 조절 가능
📌 Back propagation in Practice
-
Unrolling Parameters

-
Gradient Checking
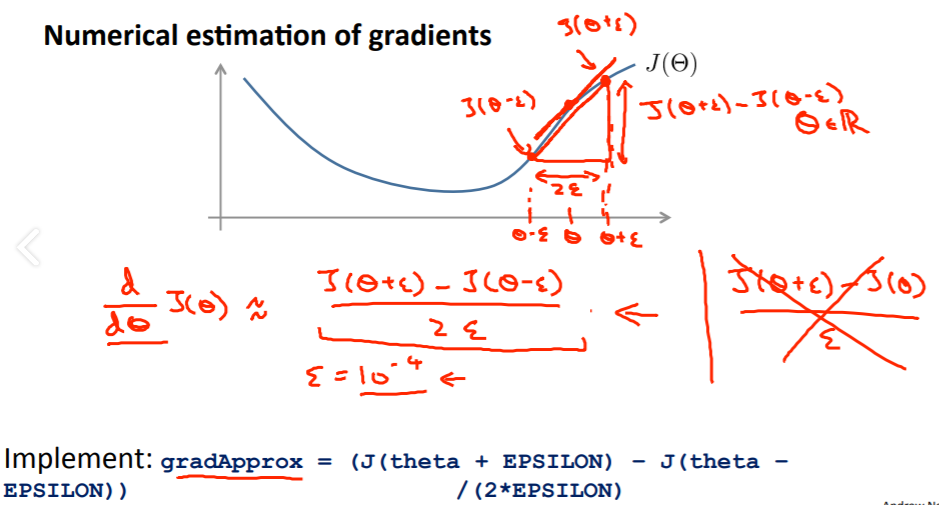
Θ별 기울기의 gradApprox를 구하는 방법

📌 Random initialization
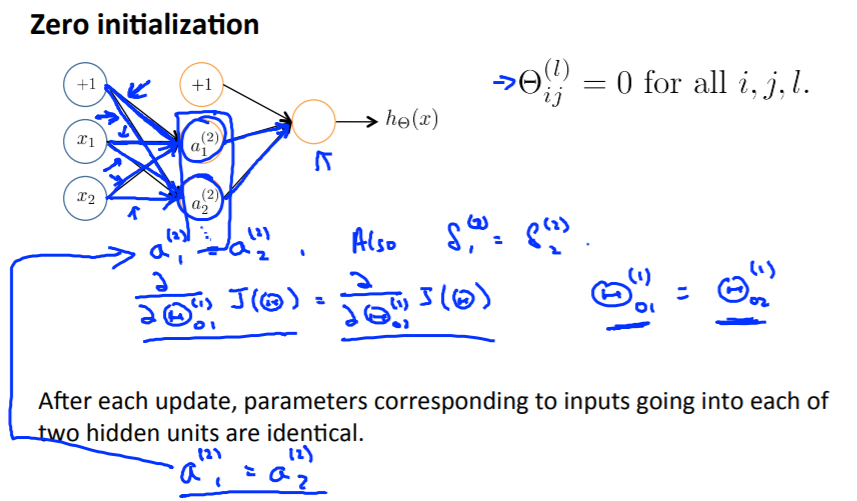
초기 Θ값을 모두 0으로 초기화했다 가정 ,
-
forward propagation을 수행
-> 두번째 layer의 모든 unit의 a값이 동일해짐 -
Back propagation 수행
-> 두번째 layer의 모든 unit의 델타값이 동일해짐 -
J(Θ)를 Θ로 편미분한 값도 동일해짐
-> Back propagation가 수행될 때 마다 첫번째 layer의 Θ값은 같은 값으로만 바뀜
!!! NN에서 zero initialization을 사용하면 중복 뉴런을 사용하게 되어 비효율적인 결과가 나타남 -> random initialization을 사용하여 개선
📌 Putting it together


